










上周,有个小伙伴参加了美团的面试。面试官给他出了一个很经典的问题:
两个数据库各有一百万条数据,如何在20秒内完成数据比对?
小伙伴没有答到点子上,面试官不满意,最终面试挂了
这个问题看似简单,但实际上却需要高效的算法设计。今天,我们就来详细解析一下这个问题,并给出一些实用的解决方案。
接下来我分享一下具体细节。
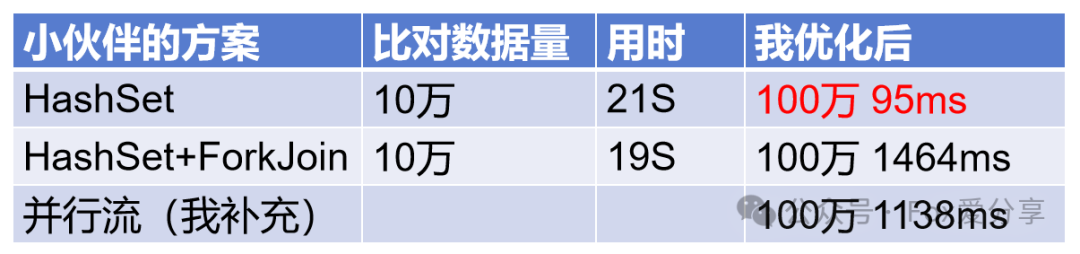
方案1:HashSet,10万数据对比用时21秒多
为了实现高效的比对,可以选择HashSet作为主要的数据结构。HashSet的显著特点是利用哈希表实现,保证了元素的唯一性和查询速度。在此场景下,HashSet将提供接近O(1)的查询性能,大大缩短比对时间。
小伙伴的代码
public class FastComparison {private static final int NUM_OF_THREADS = 8;private static final long DATA_SIZE = 100000; //10万条数据public static void main(String[] args) throws InterruptedException, ExecutionException {// 创建两个包含100万条数据的HashSetHashSet<String> set1 = createData(DATA_SIZE);HashSet<String> set2 = createData(DATA_SIZE);// 创建固定大小的线程池ExecutorService executor = Executors.newFixedThreadPool(NUM_OF_THREADS);CompletionService<Boolean> completionService = new ExecutorCompletionService<>(executor);// 记录开始时间long startTime = System.currentTimeMillis();// 提交任务到线程池for (int i = 0; i < DATA_SIZE; i += (DATA_SIZE / NUM_OF_THREADS)) {final int start = i;completionService.submit(() -> {for (int j = start; j < start + (DATA_SIZE / NUM_OF_THREADS); j++) {if (!set2.contains(set1.toArray()[j])) {return false;}}return true;});}// 等待所有任务完成int finishedTasks = 0;boolean isIdentical = true;while (finishedTasks < NUM_OF_THREADS) {Future<Boolean> future = completionService.take();if (!future.get()) {isIdentical = false;break;}finishedTasks++;}// 关闭线程池executor.shutdown();// 记录结束时间long endTime = System.currentTimeMillis();System.out.println("是否相同: " + isIdentical);System.out.println("耗时: " + (endTime - startTime) + "毫秒");}// 创建数据集private static HashSet<String> createData(long size) {HashSet<String> setData = new HashSet<>();for (int i = 0; i < size; i++) {setData.add("item" + i);}return setData;}}
处理用时
100万数据比对要很久,调整到10万,花了21秒多
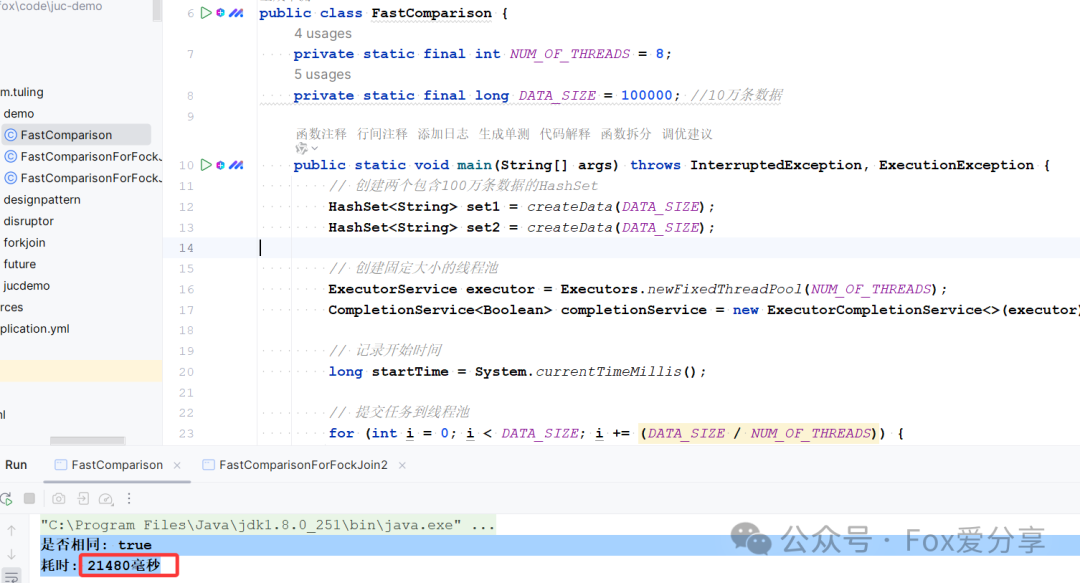
我优化后的代码
100万数据比对仅需要95ms
public class FastComparison {private static final int NUM_OF_THREADS = 8;private static final long DATA_SIZE = 1000000; //100万条数据public static void main(String[] args) throws InterruptedException, ExecutionException {// 创建两个包含100万条数据的HashSetHashSet<String> set1 = createData(DATA_SIZE);String[] set1Array = set1.toArray(new String[0]);HashSet<String> set2 = createData(DATA_SIZE);// 创建固定大小的线程池ExecutorService executor = Executors.newFixedThreadPool(NUM_OF_THREADS);CompletionService<Boolean> completionService = new ExecutorCompletionService<>(executor);// 记录开始时间long startTime = System.currentTimeMillis();// 提交任务到线程池for (int i = 0; i < DATA_SIZE; i += (DATA_SIZE / NUM_OF_THREADS)) {final int start = i;completionService.submit(() -> {for (int j = start; j < start + (DATA_SIZE / NUM_OF_THREADS); j++) {if (!set2.contains(set1Array[j])) {return false;}}return true;});}// 等待所有任务完成int finishedTasks = 0;boolean isIdentical = true;while (finishedTasks < NUM_OF_THREADS) {Future<Boolean> future = completionService.take();if (!future.get()) {isIdentical = false;break;}finishedTasks++;}// 关闭线程池executor.shutdown();// 记录结束时间long endTime = System.currentTimeMillis();System.out.println("是否相同: " + isIdentical);System.out.println("耗时: " + (endTime - startTime) + "毫秒");}// 创建数据集private static HashSet<String> createData(long size) {HashSet<String> setData = new HashSet<>();for (int i = 0; i < size; i++) {setData.add("item" + i);}return setData;}}
处理用时
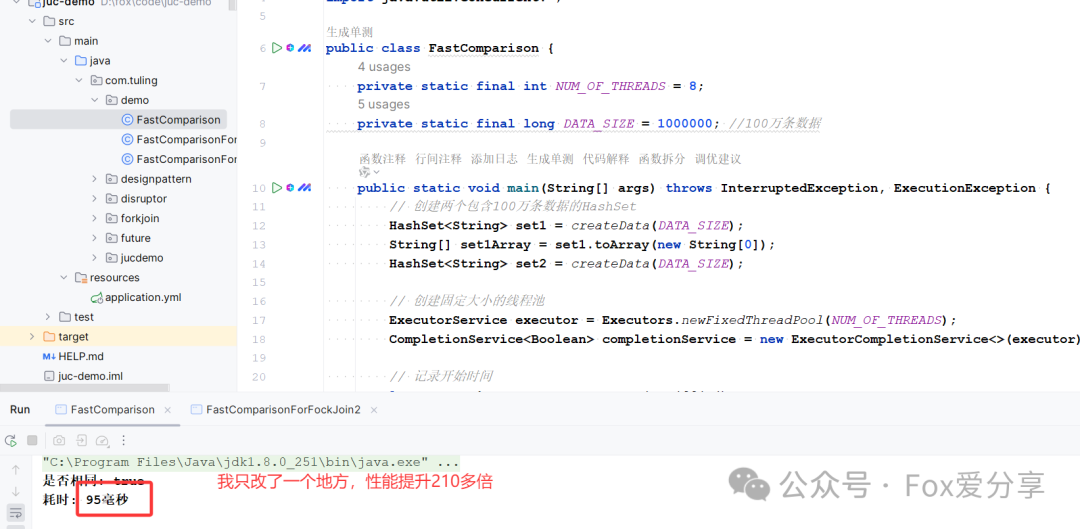
方案2:继续优化,引入ForkJoin分批次并行处理,10万数据比对用时19秒多
使用Java中的ForkJoin框架来进行多核并行处理。ForkJoin框架基于工作窃取算法,非常适合递归分治任务,可以显著提升大规模数据处理的性能。
小伙伴的代码
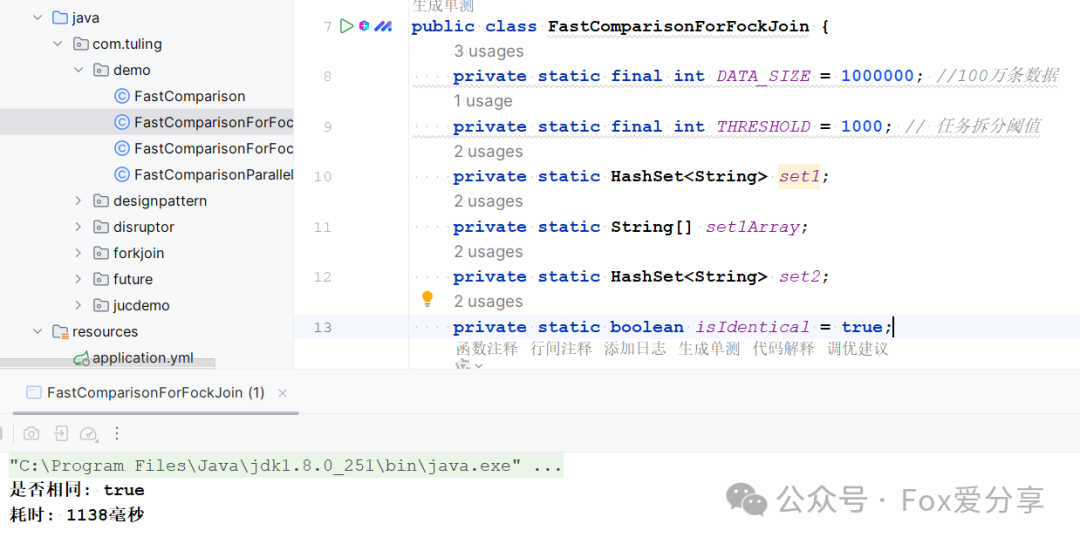
public class FastComparisonForFockJoin {private static final int DATA_SIZE = 100000; //10万条数据private static final int THRESHOLD = 1000; // 任务拆分阈值private static HashSet<String> set1;private static HashSet<String> set2;private static boolean isIdentical = true;public static void main(String[] args) throws InterruptedException, ExecutionException {// 创建两个包含100万条数据的HashSetset1 = createData(DATA_SIZE);set2 = createData(DATA_SIZE);// 创建ForkJoin池ForkJoinPool forkJoinPool = new ForkJoinPool();// 记录开始时间long startTime = System.currentTimeMillis();// 提交任务到ForkJoin池CompareTask task = new CompareTask(0, DATA_SIZE);forkJoinPool.invoke(task);// 关闭ForkJoin池forkJoinPool.shutdown();// 记录结束时间long endTime = System.currentTimeMillis();System.out.println("是否相同: " + isIdentical);System.out.println("耗时: " + (endTime - startTime) + "毫秒");}// 创建数据集private static HashSet<String> createData(long size) {HashSet<String> setData = new HashSet<>();for (int i = 0; i < size; i++) {setData.add("item" + i);}return setData;}// 比较任务static class CompareTask extends RecursiveAction {private final int start;private final int end;public CompareTask(int start, int end) {this.start = start;this.end = end;}@Overrideprotected void compute() {if (end - start <= THRESHOLD) {for (int i = start; i < end; i++) {if (!set2.contains(set1.toArray()[i])) {isIdentical = false;}}} else {int mid = (start + end) / 2;CompareTask leftTask = new CompareTask(start, mid);CompareTask rightTask = new CompareTask(mid, end);invokeAll(leftTask, rightTask);}}}}
处理用时
同样的100万数据比对要很久,调整到10万,花了19秒多
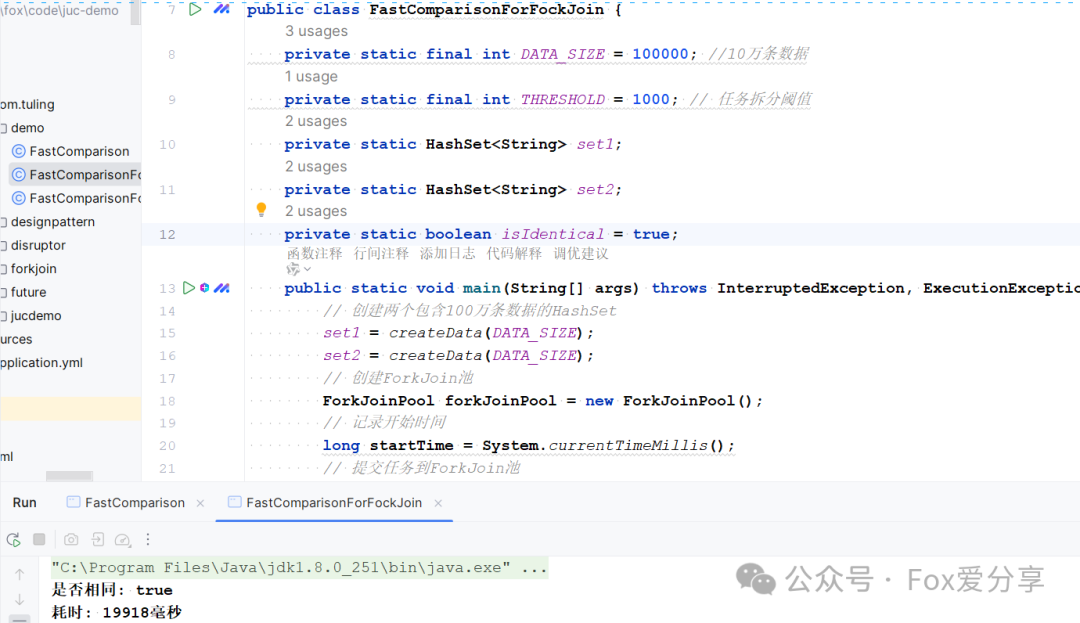
我修改后的代码
public class FastComparisonForFockJoin {private static final int DATA_SIZE = 1000000; //100万条数据private static final int THRESHOLD = 1000; // 任务拆分阈值private static HashSet<String> set1;private static String[] set1Array;private static HashSet<String> set2;private static boolean isIdentical = true;public static void main(String[] args) throws InterruptedException, ExecutionException {// 创建两个包含100万条数据的HashSetset1 = createData(DATA_SIZE);set1Array = set1.toArray(new String[0]);set2 = createData(DATA_SIZE);// 创建ForkJoin池ForkJoinPool forkJoinPool = new ForkJoinPool();// 记录开始时间long startTime = System.currentTimeMillis();// 提交任务到ForkJoin池CompareTask task = new CompareTask(0, DATA_SIZE);forkJoinPool.invoke(task);// 关闭ForkJoin池forkJoinPool.shutdown();// 记录结束时间long endTime = System.currentTimeMillis();System.out.println("是否相同: " + isIdentical);System.out.println("耗时: " + (endTime - startTime) + "毫秒");}// 创建数据集private static HashSet<String> createData(long size) {HashSet<String> setData = new HashSet<>();for (int i = 0; i < size; i++) {setData.add("item" + i);}return setData;}// 比较任务static class CompareTask extends RecursiveAction {private final int start;private final int end;public CompareTask(int start, int end) {this.start = start;this.end = end;}@Overrideprotected void compute() {if (end - start <= THRESHOLD) {for (int i = start; i < end; i++) {if (!set2.contains(set1Array[i])) {isIdentical = false;}}} else {int mid = (start + end) / 2;CompareTask leftTask = new CompareTask(start, mid);CompareTask rightTask = new CompareTask(mid, end);invokeAll(leftTask, rightTask);}}}}
处理用时
方案3:我提供的方案,Java内置并行流
示例代码
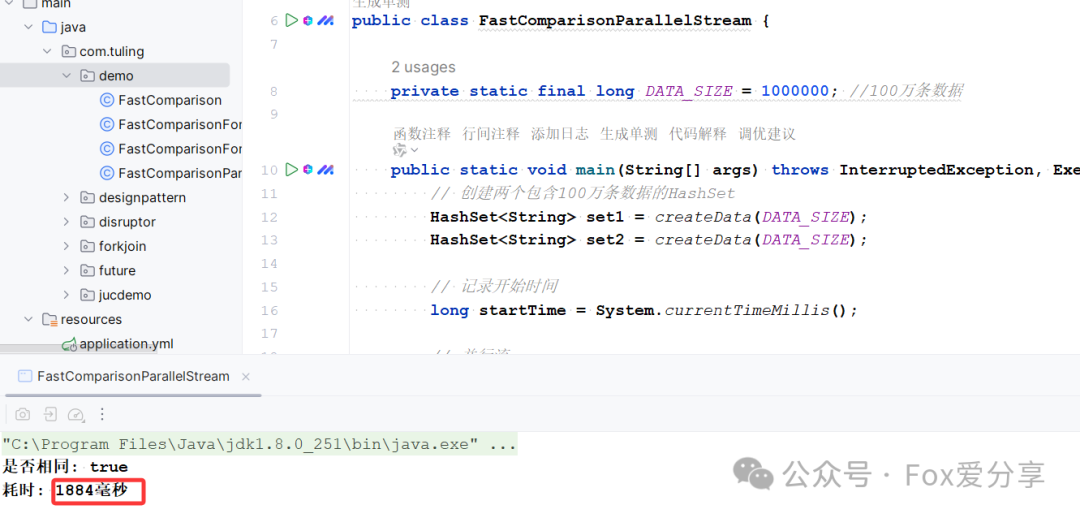
public class FastComparisonParallelStream {private static final long DATA_SIZE = 1000000; //100万条数据public static void main(String[] args) throws InterruptedException, ExecutionException {// 创建两个包含100万条数据的HashSetHashSet<String> set1 = createData(DATA_SIZE);HashSet<String> set2 = createData(DATA_SIZE);// 记录开始时间long startTime = System.currentTimeMillis();// 并行流boolean isIdentical = set1.parallelStream().allMatch(set2::contains);// 记录结束时间long endTime = System.currentTimeMillis();System.out.println("是否相同: " + isIdentical);System.out.println("耗时: " + (endTime - startTime) + "毫秒");}// 创建数据集private static HashSet<String> createData(long size) {HashSet<String> setData = new HashSet<>();for (int i = 0; i < size; i++) {setData.add("item" + i);}return setData;}}
处理用时
拓展:数据库层面的高效比对
- MD5哈希比对:计算行数据的MD5值进行快速比对
-- MD5比对示例SELECT sum(case when left_table.record_key is not null then 1 else 0 end) as left_table_num,sum(case when right_table.record_key is not null then 1 else 0 end) as right_table_num,sum(case when left_table.record_key = right_table.record_key then 1 else 0 end) as left_right_equal_numFROM (SELECT md5(concat_ws('|', col1, col2, ...)) as record_key FROM table1) left_tableFULL OUTER JOIN (SELECT md5(concat_ws('|', col1, col2, ...)) as record_key FROM table2) right_table ON left_table.record_key = right_table.record_key
- 勾稽验证法:统计两表记录数、非空记录数等快速判断一致性
- 暴力比对法:对具有唯一ID的表直接JOIN比对

















 3590
3590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









