






 本文介绍了在Buildroot中通过修改/etc/network/interfaces和/etc/dhcpcd.conf来配置网络接口,包括静态IP地址、DNS服务器等,以及如何使用nslookup验证DNS设置。
本文介绍了在Buildroot中通过修改/etc/network/interfaces和/etc/dhcpcd.conf来配置网络接口,包括静态IP地址、DNS服务器等,以及如何使用nslookup验证DNS设置。
目前在buildroot有两种修改配置文件方式:
1、修改 /etc/network/interfaces
auto eth0
iface eth0 inet static
address 192.168.3.232
gateway 192.168.3.9
broadcast 192.168.3.0
netmask 255.255.255.0
dns-nameservers 8.8.8.8
auto eth1
iface eth1 inet static
address 192.168.217.23
gateway 192.168.217.1
broadcast 192.168.3.0
netmask 255.255.255.0
dns-nameservers 8.8.8.8
2、修改配置文件 /etc/dhcpcd.conf
interface eth0
static ip_address=192.168.3.21/16
static routers=192.168.3.1
static domain_name_servers=8.8.8.8 114.114.114.114
static broadcast_address=192.168.3.255
interface eth1
static ip_address=192.168.3.55/16
static routers=192.168.3.1
static domain_name_servers=8.8.8.8 114.114.114.114
static broadcast_address=192.168.3.255

3、使用 nslookup + ip 地址可以查看DNS
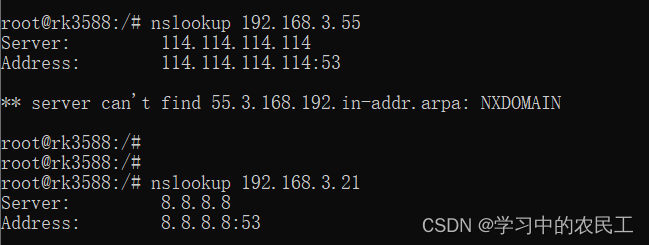
/etc/dhcpcd.conf详细配置可以参考或者(package/dhcp/dhclient-script):
https://wiki.archlinuxcn.org/wiki/Dhcpcd?rdfrom=https%3A%2F%2Fwiki.archlinux.org%2Findex.php%3Ftitle%3DDhcpcd_%28%25E7%25AE%2580%25E4%25BD%2593%25E4%25B8%25AD%25E6%2596%2587%29%26redirect%3Dno

















 1249
1249

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









