










文章目录
1.神经网络如何调参?
GridSearch
神经网络调参的方法一般叫网格搜索法,对所有参数进行循环遍历,尝试每一种可能性,找出最优结果。其原理就像是在数组里寻找最大值。
2. 讲一下Transformer?以及它比RNN优势在哪里?
tensorfmer使用的编码解码器原理,它将输入序列编码成一个连续表达式,在输出端将这个表达式又转换成序列。
它的编码器和解码器各有6层,在每一层后面都会接一个残差归一化层。模型中的所有子层的输出维度都是512。
-
对于RNN来说,它当前隐藏层的输出只与上一层的隐藏层输出和当前的输入有关系,限制了模型的并行能力且无法处理长期依赖。
-
LSTM在一定程度上能够解决长期依赖问题,但是对于特别长期的依赖仍然无法处理。
-
Tensorfor将序列中任意两个位置之间的距离转换成一个常量;并且它不同于CNN的顺序结构,它能够并行处理问题。
3. LSTM的概念,LSTM有哪些变种以及BPTT(基于时间的反向传播)
LSTM是为了解决RNN无法处理长程依赖问题的,它的结构主要由输入门、遗忘门以及输出门组成。控制门开关的cell类似于信息传送工具,使得LSTM在长序列场景下不会丢失信息。
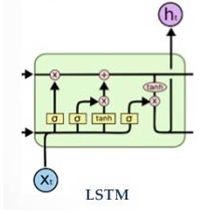
它的变种包括:
-
MOGRIFIER LSTM:网络的特点是当前这一轮的输入和隐藏状态输入都是由上一轮训练的输入和隐藏状态计算得到的,这就保证了信息各层输入与隐藏状态之间产生关联,更好获取上下文信息。
-
GRU:它的特点是只有更新门和重置门。更新门用来控制上一时刻状态中有多少信息被代入到当前状态,而控制门用来确定上一时刻代入的信息有多少被写入,也就是有多少是可利用的。
BPTT:循环神经网络时间反向传播网络
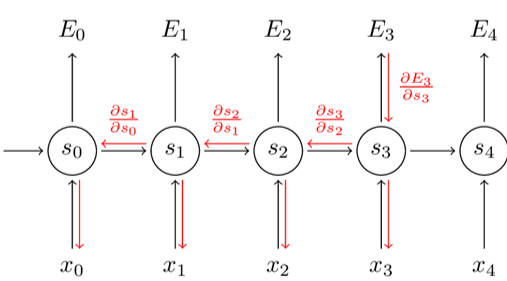
BPTT网络将每次输入的一个序列看作一个训练样本,然后计算交叉熵表征每个时刻的损失情况,将每个时刻的交叉熵损失之和作为总的损失。然后利用总的损失误差在参数(U,V,W)上的梯度,然后利用梯度下降法来更新参数。
BPTT的输入是序列,是以时间尺度来更新参数的。
4. LR不使用MSE而使用交叉熵损失函数的原因
LR线性回归使用交叉熵损失函数的原因就是为了避免训练进入到局部最小值,这将很依赖网络初始值的选取。它的损失函数为
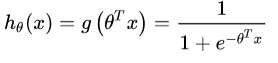
如果使用MSE作为损失函数,那么它的梯度是与损失函数的导数有关的,损失函数的导数分母是2次的,因此如果当前输出接近0或者1的话,那梯度的值就会很小,导致收敛很慢。
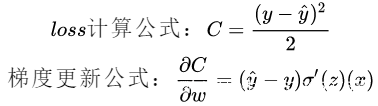
但是交叉熵损失就不会,它的损失函数只与输出误差有关系,误差大,损失函数就大,梯度就大;误差小,损失函数就小,梯度就小。
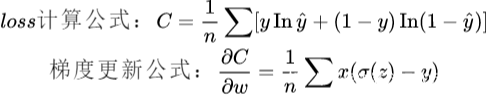
5. 说说CNN的优点、缺点
优点:可以自动提取特征;共享同一个卷积核和权重
缺点:池化层会丢失大量的信息;可解释性不强;需要大量数据进行训练
6. 讲一下item-CF,怎么计算相似度,以及用什么优化
item-cf是一种基于物品的协同过滤推荐算法,它的方法是通过用户对item打的分数来对item的相似度进行评估,然后再基于这个相似度进行item推荐。
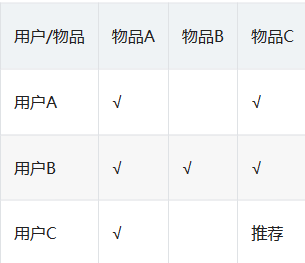
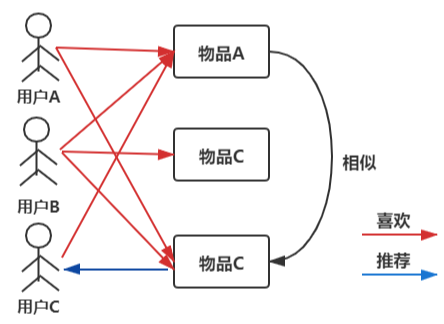
推荐算法的步骤:
STEP1 根据用户对某些item的历史行为构建表,统计同时喜欢两种item的用户数,即R[i][j]=N表示同时喜欢i物品和j物品的用户数为N。得到共现矩阵
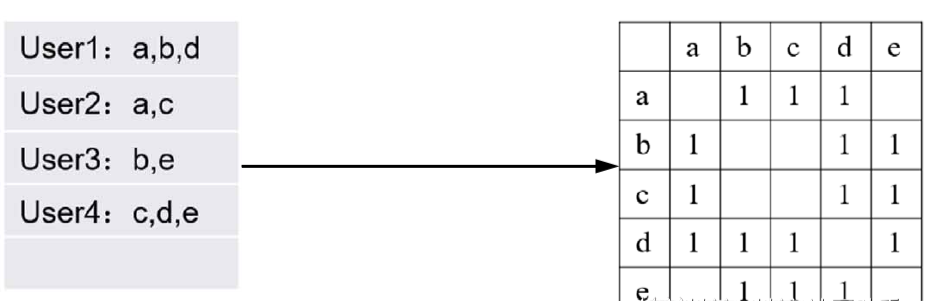
STEP2 根据共线矩阵计算物品之间的相似度
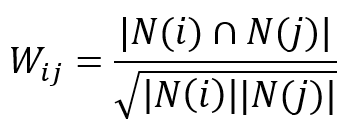
Wij表示物品i和物品j之间的相似度。则用户u对于物品j感兴趣的程度为
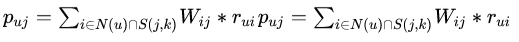
其中,k表示通过数据集计算出来的相似item的集合,S(j,k)表示与物品j相似的k个item的集合,N(u)表示用户喜欢的item集合,Rui表示用户u对物品i的感兴趣的度量值。
优化的三种办法:
基于时间权重的优化:也就是用一个权重表示用户购买时刻i和时刻j的时间差,其核心思想是用户在一段时间内买的两个物品,时间越近,相似度越高。
基于用户session的优化:将用户的购买记录在一段时间内分成多个session,单独计算每个session的分数,然后求和。依据是认为用户在一段时间内的行为具有关联性。
基于序列的单项相似性优化:假定用户的行为具有一定的序列意义,用户在购买手机后购买手机壳的几率大,但是反过来几率小。做法是加上一个衰减因子。
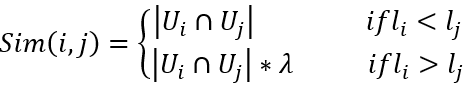
7. CNN参数计算
-
卷积层输出张量大小

I为输入图像的大小,K为卷积核的大小,P为核的填充,S为移动步长。 -
池化层输出张量
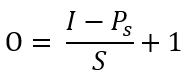
Ps为池化层核的尺寸大小,I为输入图像尺寸,S为移动步长。 -
卷积层的参数数量
权重数量: W_c = K^2 * C * N
偏置数量: B_c = N
N代表的是核的个数,也就是卷积层的神经元个数,K代表的是核的尺寸大小,C指的是输入的图像通道数,也就是输入层的神经元个数。 -
全连接层的参数数量
权重: W_cf = O^2 * N * F
偏置: B_cf = F
N代表全连接层核的数量,也就是全连接层神经元个数,F代表上一层的神经元个数,O代表全连接层核的尺寸大小。
8. 请你说说TFIDF的公式
词频-逆文本频率
- 词频
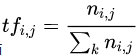
- 逆文本频率
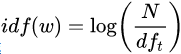
- 词频-逆文本频率
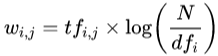
9. 请你说说tfidf
tfidf是谷歌发家的主要核心算法之一,它主要用在文本信息检索,语意抽取等自然语言处理当中。它的主要核心思想是
- 字词的重要性与它在文本中出现的频次成正比;
- 字词的重要性与它的语料库中出现的频次成反比。
也就是说,一个词语在一个文章中出现的次数最多,但是在所有文章中出现的次数最少,那么它最能代表该文章的信息内容。
不足:
- 文本中出现频次小的词语不重要,出现次数多的重要,显然不是完全正确的;
- 它结构简单,并不能指出单词的重要程度和特征词的分布情况,使其无法很好地调整权值;
- 没有给出单词的位置信息,单词在文中不同位置时应该给出不同的权重计算方法,因为不同位置的单词的重要程度是不一样的。
10. 决策树的算法和优缺点
决策树就是从训练数据中选择特征对数据进行分类,由于一棵树能选取的特征是有限的,因此就有了随机森林。是有监督的学习算法。
选择特征的标准:
- ID3算法:以信息增益作为特征筛选数据,表示在知道特征A的信息而使得样本的不确定性减少的程度
- C4.5算法:以信息增益比作为特征筛选数据;
- ART算法:既可以用于分类,也可以作回归问题,CART采用了基尼系数取代了信息熵模型。
优缺点:
决策树易于理解,可以可视化分析,容易提取出规则;
可以同时处理标称数据和数值数据;
比较适合有缺失属性的样本;
能够处理不相关的数据;
测试数据时,运行速度比较快;
能够在较短时间内对大型数据作出可行且效果良好的结果。
容易发生过拟合(RF,GBDT可以解决);
容易忽略数据集中属性的关联;
对于那些各类别样本数量不一致的数据,在决策树中,进行属性划分时,不同的判定准则会带来不同的属性选择倾向















 4157
4157











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









