






个人对Pandas中agg、apply和transform函数的理解
学习《利用Python进行数据分析》一书,关于pandas的这三个函数,个人理解如下。
apply() 函数可以直接对 Series 或者 DataFrame 中元素进行逐元素遍历操作,可以代替for 循环遍历dataframe,并且效率远高于for 循环(可以达到800多倍)。pandas apply 带参函数操作多列或者多行数据
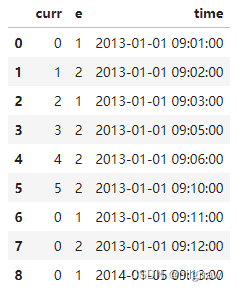
测试数据:
df_group = pd.DataFrame({'curr': [0, 1, 2, 3, 4, 5, 0, 0, 0],'e':[1,2,1,2,2,2,1,2,1],'time':[pd.Timestamp('2013-01-01 09:01:00'),pd.Timestamp('2013-01-01 09:02:00'), pd.Timestamp('2013-01-01 09:03:00'),pd.Timestamp('2013-01-01 09:05:00'),pd.Timestamp('2013-01-01 09:06:00'),pd.Timestamp('2013-01-01 09:10:00'),pd.Timestamp('2013-01-01 09:11:00'),pd.Timestamp('2013-01-01 09:12:00'),pd.Timestamp('2014-01-05 09:13:00')]})
agg
agg方法可以被groupby、dataframe、series等对象调用。
dataframe的agg方法的官方文档
其用法为pandas.DataFrame.agg(self, func, axis=0, *args, **kwargs)
func可以是function, str, list或dict,可以接受的形式有函数、函数名称的字符串、函数列表或字典。
agg可以直接以字符串的形式使用pandas和Python内置的函数,也可以使用用户自定义的函数,可以传递自定义函数的参数,并且有axis参数。
还可以一次性传入多个函数,给函数设置计算结果的列名,支持对不同的series使用不同的函数(以字典形式传参),即一次性对多个列进行不同的聚合操作。
本方法主要用于聚合,首先对Frame对象的各行(或列)进行计算并得到标量聚合结果,然后汇总所有组的聚合结果为一个数组,当一次性传入多个聚合函数时,可返回DataFrame(官网介绍为 DataFrame : when DataFrame.agg is called with several functions Return scalar, Series or DataFrame.)。但当自定义函数的输入输出都是DataFrame时,agg无法实现。
agg的多种用法(函数均为聚合函数):
1.对所有列求中位数。不指定列时,对每一列进行操作,time列无法求中位数,会有warning。原列名变为series的index,无name。
df_group.agg('median', axis=0)

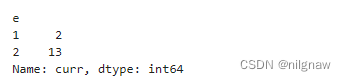
2.按e列分组,对curr列求和。分组值为series的index,series的name为列名curr。
df_group.groupby('e')['curr'].agg('sum')
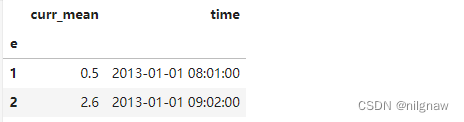
3.分组后,对curr列求均值,返回列名为curr_mean,对time列求第一个值,返回列名为time。dataframe的index有名称‘e’,index和columns都只有一个level。
df_group.groupby('e').agg(curr_mean=('curr','mean'),time=('time','first'))
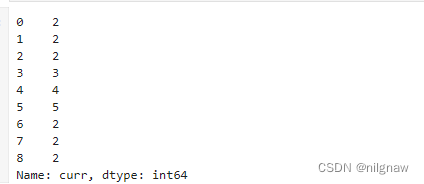
4.对curr列求和、求最小值,对e列求最小值、最大值。返回dataframe,函数名为index,列名仍为列名。
df_group.agg({'curr' : ['sum', 'min'], 'e' : ['min', 'max']})

5.使用lambda函数。series的name为列名curr。
df_group['curr'].agg(lambda x: max(x,2))
apply
apply方法可以被groupby、resampler、dataframe、series、offsets等对象调用。
dataframe的apply方法的官方文档
其用法为pandas.DataFrame.apply(self, func, axis=0, raw=False, result_type=None, args=(), **kwds)
文档中关于func参数,只说了是要应用到行或列的函数。
agg可以做的,好像apply都可以做,所以apply比agg更加灵活,更一般化,但是调用Python内置函数和pandas函数时,运行速度比agg慢。
apply还能向用户自定义函数中传递参数,而且支持在同一个dataframe的不同series间进行运算,当应用的不是聚合函数时,就是对每个元素的逐一操作。
其返回值可以是标量也可以是Series、DataFrame对象。
applymap先应用apply再对每个Series使用map,可实现逐个元素操作。
对比agg和apply读入的数据:
def fun(df):
time.sleep(1)
print(time.time())
print(df)
return df.sum()
print('agg')
b = df_group[['curr','e','time']].groupby('e').agg(fun)
print('apply')
a = df_group[['curr','e','time']].groupby('e').apply(fun)
结果为
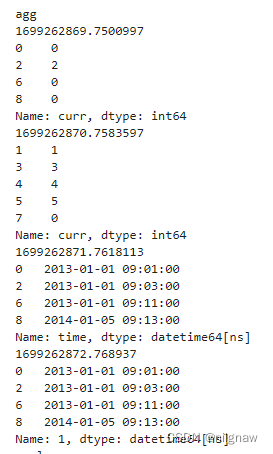
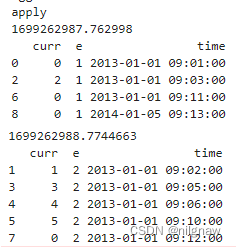
可以看出,agg在调用fun函数时,对每列分别操作,如上面打印结果,先对curr列分组并调用func函数,然后对time列分组并调用func函数。而apply按分组的key,一次性读取dataframe的所有series,对dataframe进行操作。因此,需要对dataframe整体进行处理时,要使用apply。
agg其实就是调用apply函数,也就是apply函数能用的被调用函数,agg也能用。Python - Pandas系列-最强的agg解释!
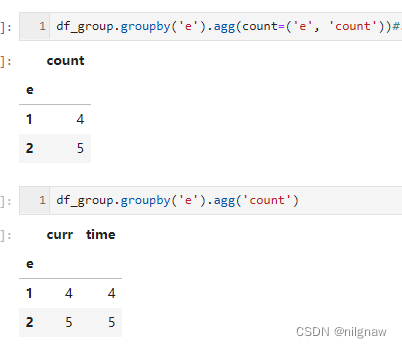
agg操作中指定了列名时,仅返回该列的计算结果;不指定列名时,计算所有列的计算结果,并使用原列名作为聚合后的df的列名。根据上面的测试结论,agg运行时是分别对各个列单独操作,返回计算结果时,按分组时的key将对应列合并。
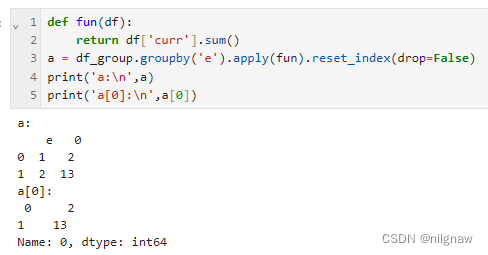
使用apply,且返回标量时,返回的是一个series,重置index后的columns为原index的名称和数字0,因为pandas中DataFrame数据结构默认使用0, 1, 2等数字作为列名。
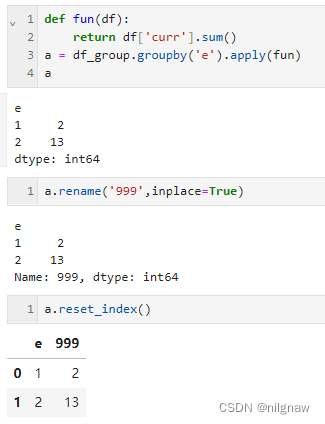
可以先对series做重命名处理,再重置index
apply还有result_type选项,通过设置result_type=‘expand’,可对多列赋值。python 使用pandas同时对多列进行赋值
apply中调用的自定义函数也需注意,当计算结果返回Series时,若自定义函数计算结果为空,应返回含有index的空Series,必须指定index,如原dataframe为
df_result = pd.DataFrame([
{'country': 'US', 'value': 100.00, 'id': 'a'},
{'country': 'US', 'value': 95.00, 'id': 'b'},
{'country': 'CA', 'value': 60.00, 'id': 'y'},
{'country': 'CA', 'value': 60.00, 'id': 'z'},
{'country': 'CA', 'value': 60.00, 'id': 'z'},
{'country': 'qq', 'value':np.nan , 'id': 'z'},
{'country': 'CA', 'value': np.nan , 'id': 'z'},
])
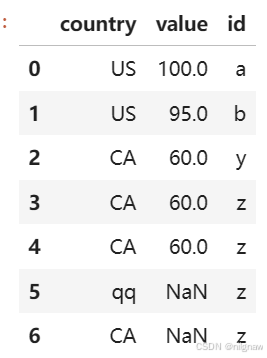
自定义函数返回值中指定了Series的index时
def fun(df):
print(df)
if df['country'].iloc[0]=='qq':
result=pd.Series(index=['max','min'])
else:
result=pd.Series([df['value'].max(),df['value'].min()],index=['max','min'])
return result
aa = df_result.groupby('country').apply(fun)
返回结果为dataframe,结果为空时也被输出:
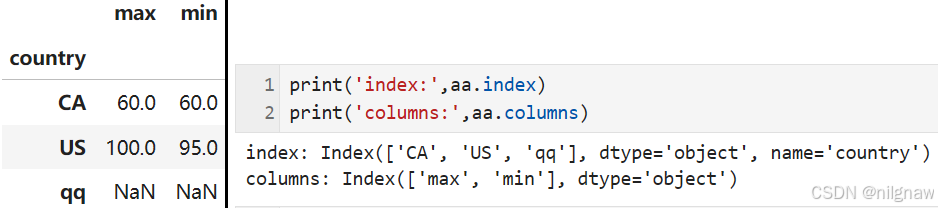 若自定义函数返回值中未指明Series的index,则有
若自定义函数返回值中未指明Series的index,则有
def fun(df):
print(df)
if df['country'].iloc[0]=='qq':
result=pd.Series()
else:
result=pd.Series([df['value'].max(),df['value'].min()],index=['max','min'])
return result
aa = df_result.groupby('country').apply(fun)
返回的是具有multi index的series,而不是dataframe,且空值不被输出。

自定义函数返回值使用Dataframe时
def fun(df):
#print(df)
if df['country'].iloc[0]=='qq':
result=pd.DataFrame(columns=['max','min']) # 指定了列名
else:
result=pd.DataFrame([[df['value'].max(),df['value'].min()]],columns=['max','min'])
return result
# 两种代码返回的结果一样
def fun(df):
#print(df)
if df['country'].iloc[0]=='qq':
result=pd.DataFrame() # 未指定列名
else:
result=pd.DataFrame([[df['value'].max(),df['value'].min()]],columns=['max','min'])
return result
df_result.groupby('country').apply(fun)
结果为多级的dataframe
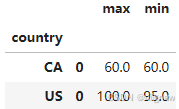
**注意:**此fun函数需要对dataframe的多个列进行操作,不能使用agg。
当fun函数中操作不涉及其他列时,可用agg
def fun(df):
result = pd.Series(index=['x2', 'x', 'xy'], dtype='float64')
if len(df)>=2:
result = pd.Series([0,0,0],index=['x2', 'x', 'xy'])
return result
df_result.groupby('country').agg(fun)
但返回结果是以‘id’为columns的dataframe,每个分组返回一条数据,且直接返回了列表,而不是带有列名的多列。
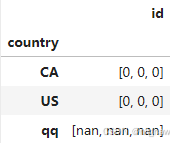
使用apply时,可返回按给定列名的dataframe,结果为空时也输出。
def fun(df):
result = pd.Series(index=['x2', 'x', 'xy'], dtype='float64')
if len(df)>=2:
result = pd.Series([0,0,0],index=['x2', 'x', 'xy'])
return result
df_result.groupby('country').apply(fun)
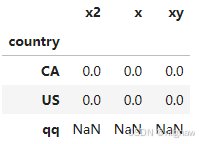
使用apply,且给定列名,返回值为dataframe而非Series时。
def fun(df):
result = pd.DataFrame(index=['x2', 'x', 'xy']).T
if len(df)>=2:
result = pd.DataFrame([0,0,0],index=['x2', 'x', 'xy']).T
return result
# 两个函数都行,结果一样
def fun(df):
result = pd.DataFrame(columns=['x2', 'x', 'xy'])
if len(df)>=2:
result = pd.DataFrame([[0,0,0]],columns=['x2', 'x', 'xy'])
return result
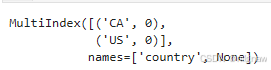
a = df_result.groupby('country').apply(fun)
结果为空时的key的结果不被输出,但index为multiindex,需要进一步对index进行处理,去掉level1的index才便于使用。

transform
transform方法可以被groupby、resampler、dataframe、series等对象调用。
groupby的transform方法的官方文档
其用法为pandas.DataFrame.transform(self, func, axis=0, *args, **kwargs)
func与agg中的func的说明完全相同。
其特点是,按元素进行操作,所以输入dataframe与输出dataframe的大小完全相同。
本方法同样支持对不同的轴调用不同的函数,以及通过字符串形式调用内置函数。
transform可以实现的操作,apply都可以,但是反之不成立。同agg一样,与内建函数一起使用时,比apply速度快。
在groupby对象中执行函数时,会同时使用元素的信息和所在组的信息。
Series.str
顺便说下对Series.str的个人理解。
Python的内置字符串方法不支持向量化操作。str是Series的属性,用于以string的方式访问序列中的元素,并对元素应用一些字符串方法,实现向量化操作。为实现这一功能,这些方法以StringMethods类的对象的方法来执行,以此来与Python的内置字符串方法进行区分。
———————————————————————————
以上均为个人观点,欢迎指正。

















 288
288

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









