







一、概述
1、概念
指编译程序为了生成高质量的目标程序而做的各种加工和处理。
2、分类
1)分类1
- 与机器无关的优化技术:即与目标机无关的优化,通常是在中间代码上进行的优化。
如:数据流分析 ,常量传播,公共子表达式删除,死代码删除,循环交换,代码内联等等 - 与机器相关的优化技术
充分利用系统资源,(指令系统,寄存器资源)。
特点:仅在特定体系结构下有效。
2)分类2
- 局部优化技术
指在基本块内进行的优化
例如,局部公共子表达式删除 - 全局优化技术
函数/过程内进行的优化
– 跨越基本块
– 例如,全局数据流分析、循环优化 - 跨函数(过程间)优化技术
– 整个程序范围内的优化
– 例如,函数内联、函数间常量传播、跨函数别名分析,逃逸分析,死调用/死函数删除,全局变量优化等。
二、基本快、流图
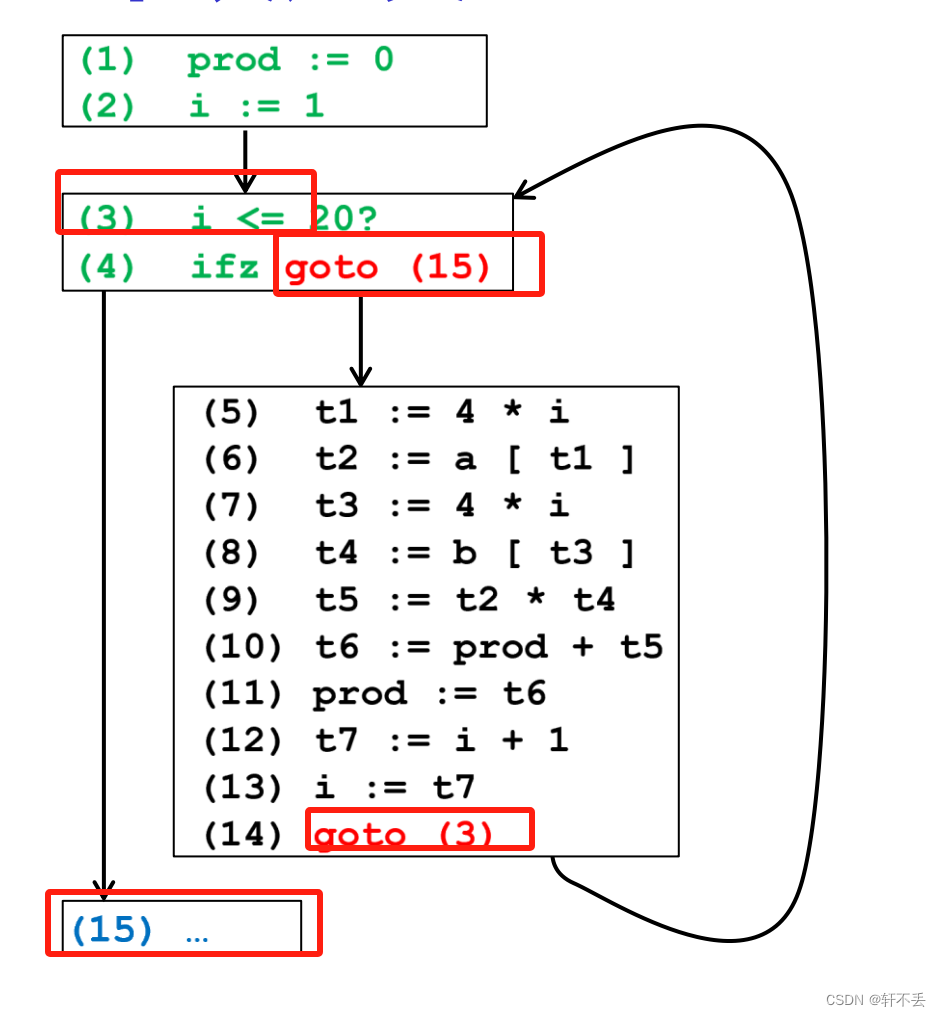
1、基本块定义
- 基本块中的代码是连续的语句序列
- 程序的执行(控制流)只能从基本块的第一条语句进入
- 程序的执行只能从基本块的最后一条语句离开
- 符合上述条件的最大块
总结:有goto的和goto去的地方需要划分
2、流图
流图是一种有向图 G(V,E)
图的节点V: <基本块>组成的集合
图中B1-B2的边:B2的执行紧跟在B1之后
编译器按照“程序—流图—基本块—中间代码”选择合理的数据结构组织和管理中间代码。
三、局部优化(基本块内的优化)
1、利用代数性质(代数变换)
编译时完成常量表达式的计算,整数类型与实型的转换。5+6变成11
2、运算强度削弱
用一种需要较少执行时间的运算代替另一种运算,以减少运行时的运算强度时、空开销) ——比如乘法变移位。
3、常数合并和传播
如 x:=y 这样的赋值语句称为复写语句。由于 x 和 y 值相同,所以当满足一定条件时,在该赋值语句下面出现的 x 可用 y 来代替。
4、删除冗余代码
冗余代码就是毫无实际意义的代码,又称死代码(dead code)或无用代码(useless code)
5、窥孔优化(peep-hole)
窥孔优化关注在目标指令的一个较短的序列上,通常称其为“窥孔”。
通过删除其中的冗余代码,或者用更高效简洁的新代码来替代其中的部分代码,达到提升目标代码质量的目的。
6、消除公共子表达式
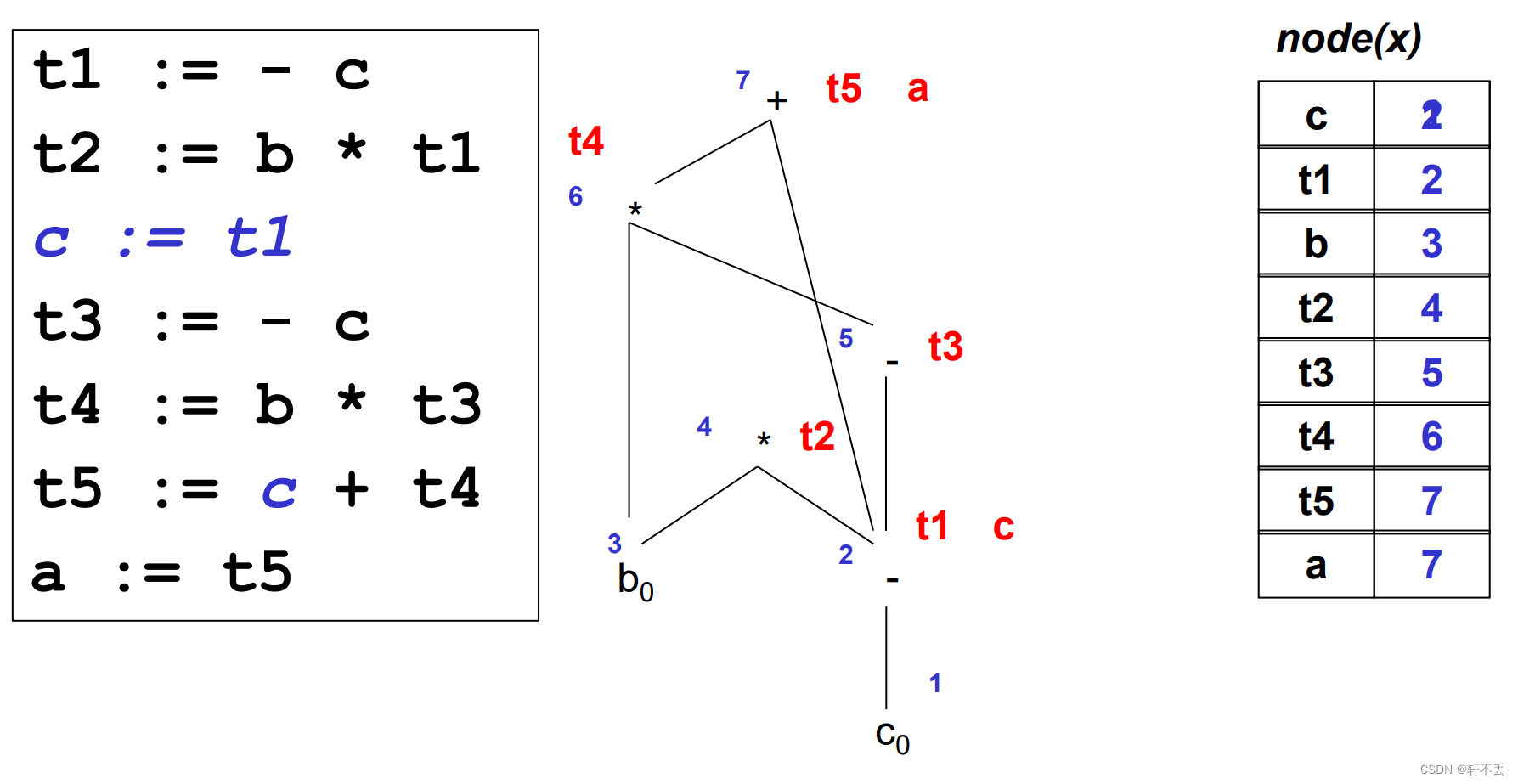
1)基本块DAG图的定义
- 图的叶节点由变量名或常量所标记。
对于那些在基本块内先引用再赋值的变量,可以采用变量名加下标0的方式命名其初值。 - 图的中间节点由中间代码的操作符所标记
代表着基本块中一条或多条中间代码。 - 基本块中变量的最终计算结果,都对应着图中的一个节点;
具有初值的变量,其初值和最终值可以分别对应不同的节点。
通过DAG图可消除公共子表达式,得到更简洁的优化代码
此时需要两个算法:DAG图的生成算法,从DAG图导出代码的算法
2)构建DAG图的算法–消除公共子表达式
• 输入:基本块内的中间代码序列
• 输出:完成局部公共子表达式删除后的DAG图
- 图/节点表初始化:节点表,记录变量名和常量值,及当前对应的DAG图中的节点序号。初始状态为空。
- 顺序遍历每一条中间代码,按照以下规则建立DAG图
形如z = x op y:在节点表中查找x (对y也做处理,对应j)如果找到,记录x 所对应的节点号 i。
找到:记录x 所对应的节点号 i。
未找到:在DAG图中新建叶节点(编号i),标记为x如果x为变量名,该标记更改为x0在节点表中增加新的表项(x, i)。
z = x op y:寻找/创建左操作数为i、右操作数为j的DAG节点,其标记为op,假定其节点编号为k,将节点i和j分别与k相连,作为其左子节点和右子节点。
z = x op y:在节点表中寻找z。
如果找到,将z所对应的节点号更改为k;
如果未找到,在节点表中新增表项(z, k)
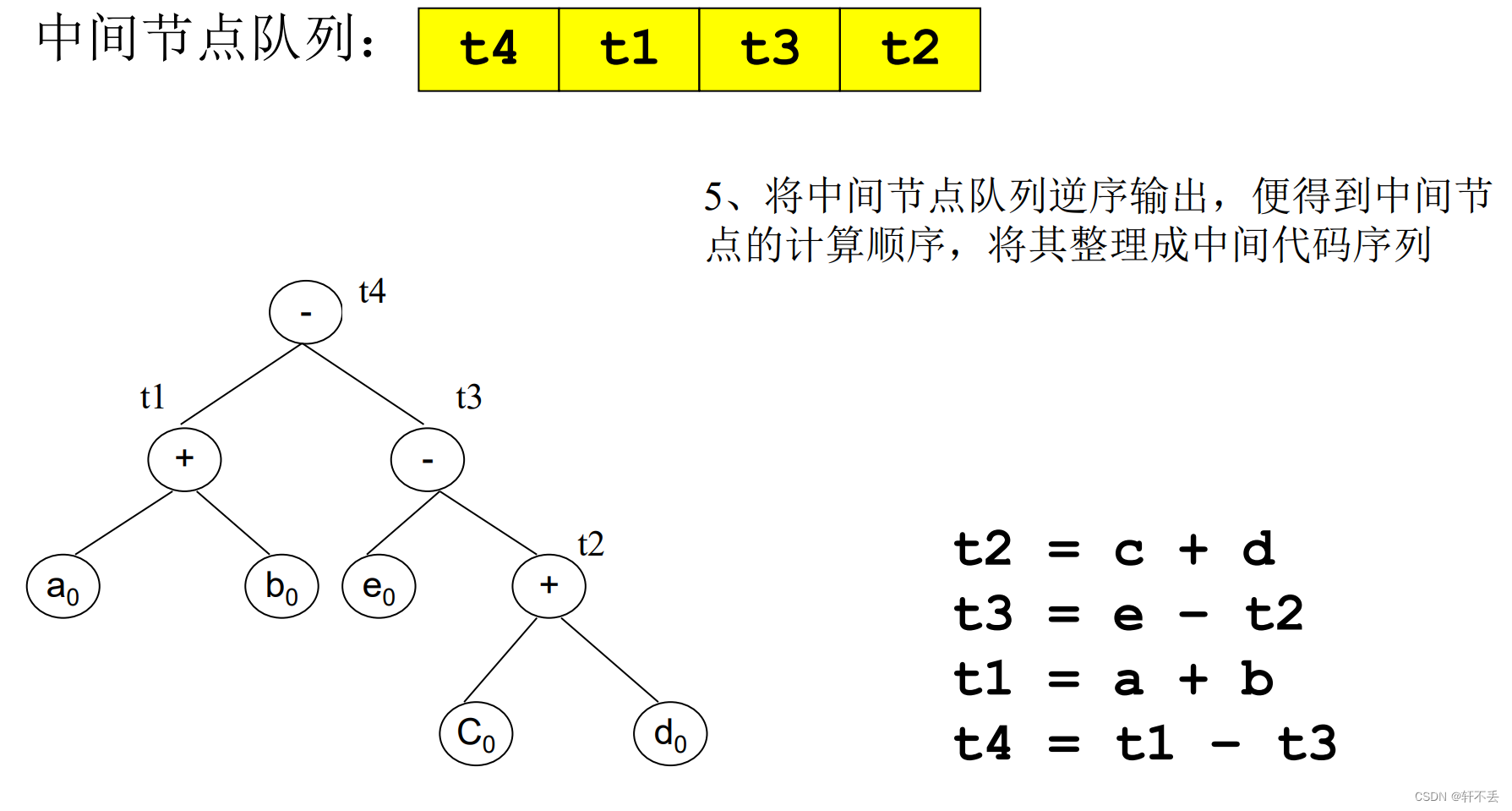
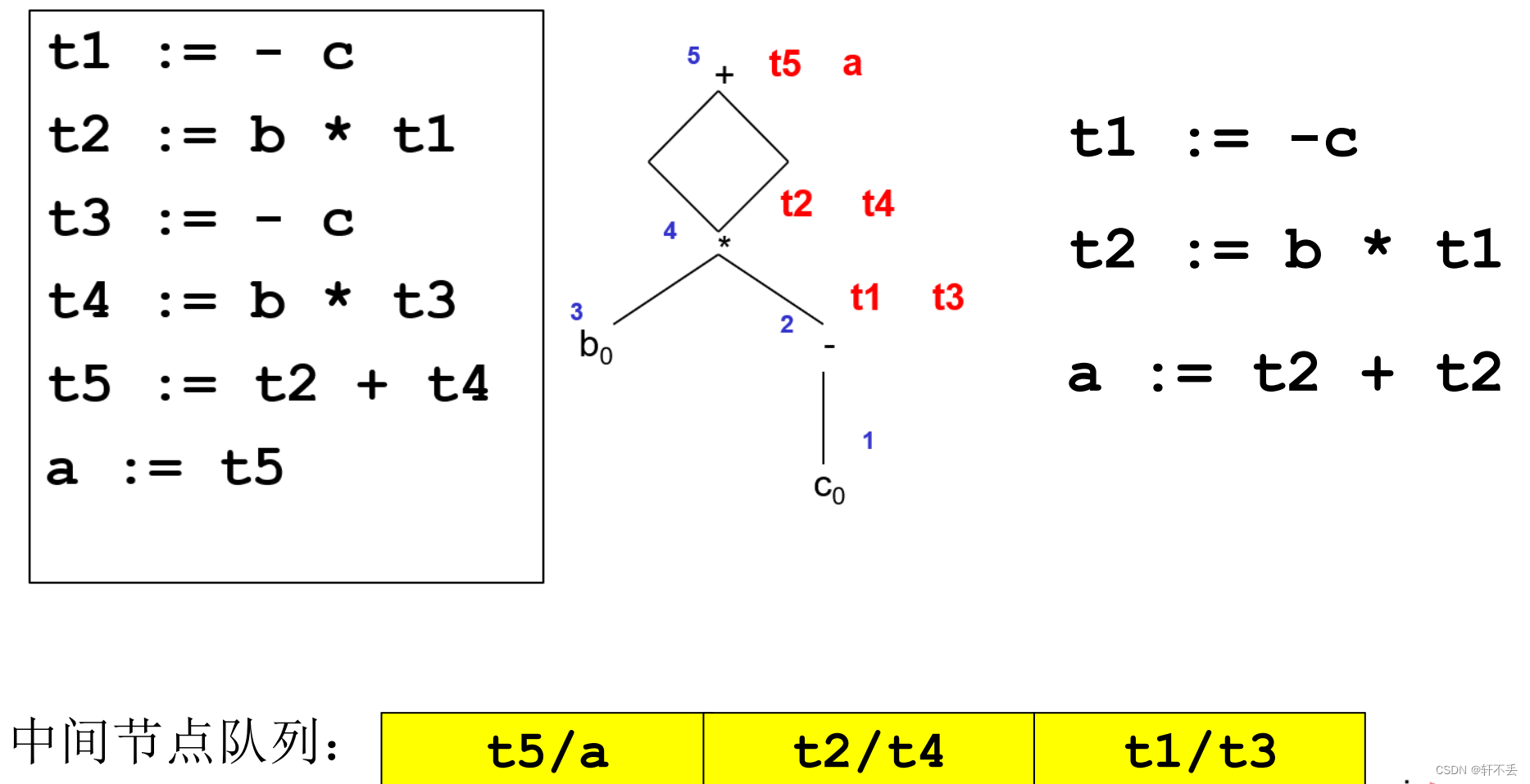
3)从DAG导出中间代码的启发式算法
- 初始化一个放置DAG图中间结点的队列。
- 如果DAG图中还有中间节点未进入队列,则执行步骤3,否则执行步骤5
- 选取一个尚未进入队列,但其所有父节点均已进入队列的中间节点n,将
其加入队列;或选取没有父节点的中间节点,将其加入队列 - 如果n的最左子节点符合步骤3的条件,将其加入队列;并沿着当前节点
的最左边,循环访问其最左子节点,最左子节点的最左子节点等,将符合
步骤3条件的中间节点依次加入队列;如果出现不符合步骤3条件的最左子
节点,执行步骤2 - 将中间节点队列逆序输出,便得到中间节点的计算顺序,将其整理成中间
代码序。
即按照前序遍历输出中间节点
四、局部优化详解
1、公共子表达式删除
利用数据流自上而下分析:等号右边在数据流中有等价的可替代

不断循环这个过程直到没有替代的为止。
2、死代码删除
变量的活性,等号右边表示需要用的,等号左边表示更新了,不能用了。
自下而上分析
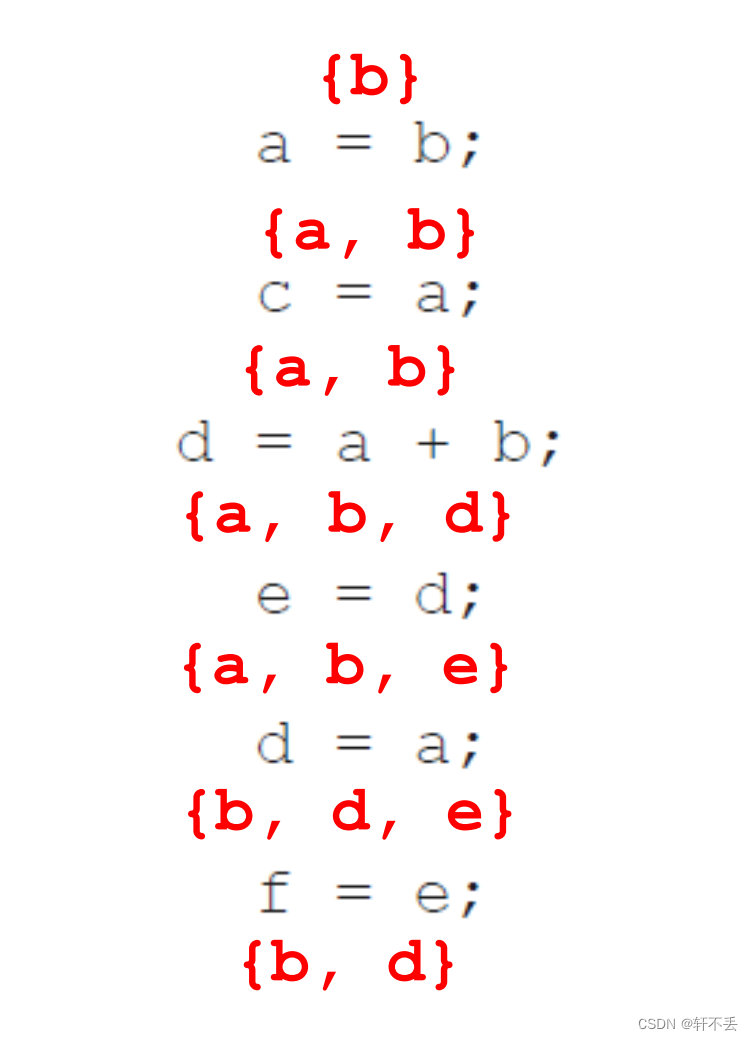
不断循环这个过程直到没有删除的为止。
五、数据流分析
1、概念
用于获取数据在程序执行路径中如何流动的有关信息。
是局部优化、全局优化的基础
上述过程就是所谓的数据流分析
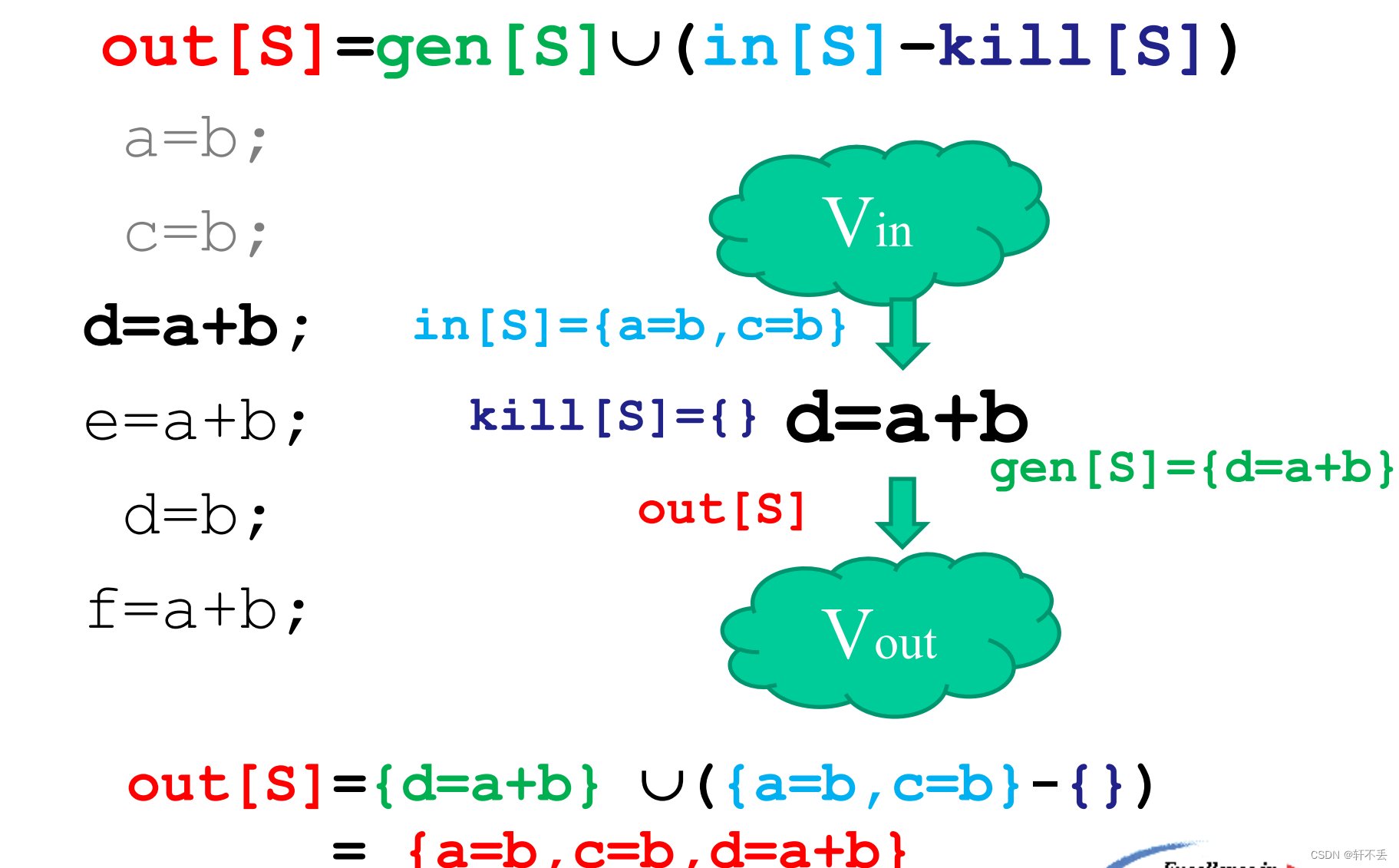
2、公式
o
u
t
[
S
]
=
g
e
n
[
S
]
U
(
i
n
[
S
]
–
k
i
l
l
[
S
]
)
out[S]=gen[S]\ U\ (in[S]–kill[S])
out[S]=gen[S] U (in[S]–kill[S])
–
S
代表某条语句(基本块,基本块集合,或语句集合)
– S 代表某条语句(基本块,基本块集合,或语句集合)
–S代表某条语句(基本块,基本块集合,或语句集合)
–
o
u
t
[
S
]
代表在该语句末尾得到的数据流信息
– out[S]代表在该语句末尾得到的数据流信息
–out[S]代表在该语句末尾得到的数据流信息
–
g
e
n
[
S
]
代表该语句本身产生的数据流信息
– gen[S]代表该语句本身产生的数据流信息
–gen[S]代表该语句本身产生的数据流信息
–
i
n
[
S
]
代表进入该语句时的数据流信息
– in[S]代表进入该语句时的数据流信息
–in[S]代表进入该语句时的数据流信息
–
k
i
l
l
[
S
]
代表该语句注销的数据流信息
– kill[S]代表该语句注销的数据流信息
–kill[S]代表该语句注销的数据流信息
根据所需要的目的不同,这些特征的值都是不同的
比如对于公共子表达式删除
六、全局优化
全局优化处理的是基本块之间的优化受到控制流的影响
1、作用
活跃变量信息对于寄存器分配,不论是全局寄存器分配还是临时寄存器分配都有重要意义
- 如果拥有寄存器的变量x在p点开始的任何路径上不再活跃,可以释放寄存器。
- 如果两个变量的活跃范围不重合,则可以共享同一个寄存器
2、活跃变量定义-以消除死代码为例
达到定义分析是沿着流图路径的,有的数据流分析是 方向计算的
因此公式是
i
n
[
S
]
=
g
e
n
[
S
]
U
(
o
u
t
[
S
]
–
k
i
l
l
[
S
]
)
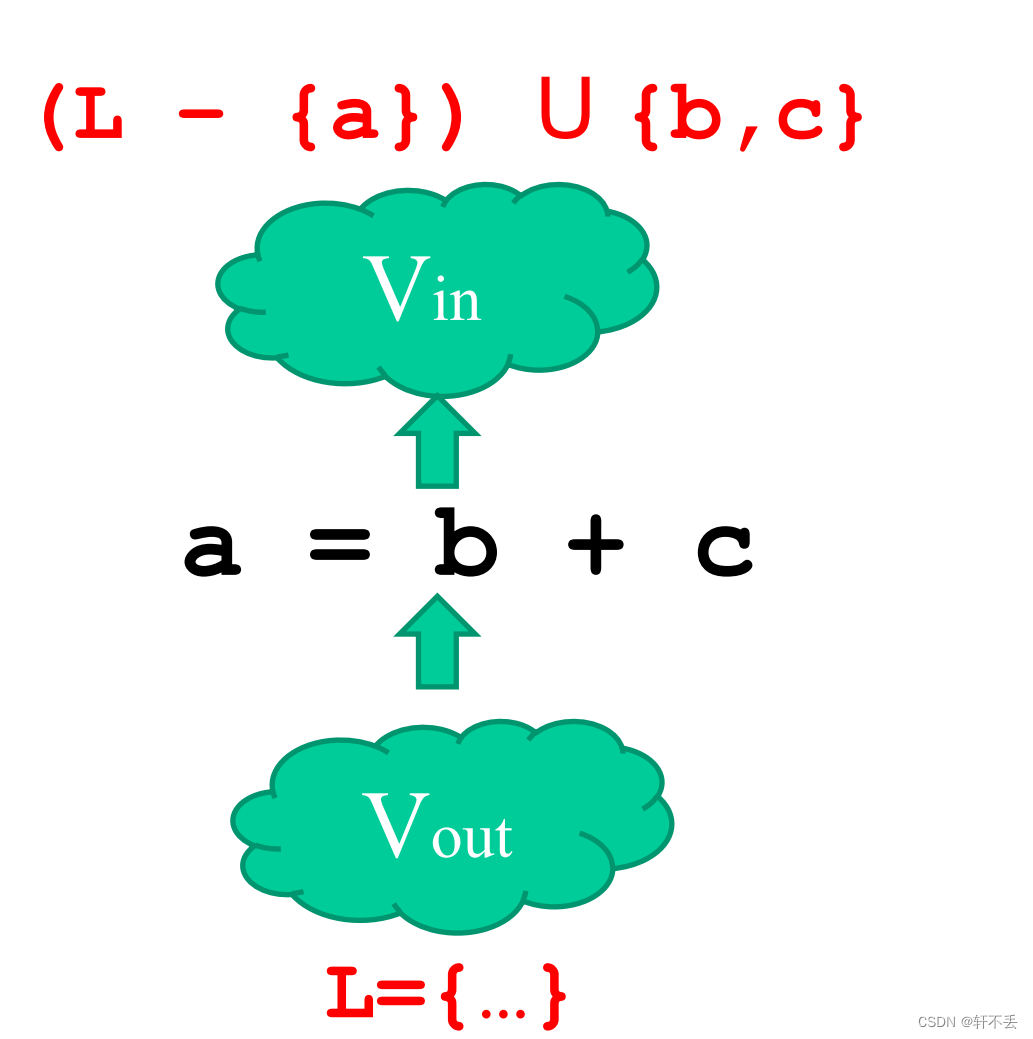
in[S]=gen[S]\ U\ (out[S]–kill[S])
in[S]=gen[S] U (out[S]–kill[S]),根据消除死代码的特殊性,可以写成
i
n
[
S
]
=
u
s
e
[
S
]
U
(
o
u
t
[
S
]
–
d
e
f
[
S
]
)
in[S]=use[S]\ U\ (out[S]–def[S])
in[S]=use[S] U (out[S]–def[S])
• 可达定义分析的数据流:沿流图中的控制流方向计算
• 活跃变量分析的数据流:沿流图中控制流的反方向计算
PS:若是一个变量即被定义又被使用,应该以被使用为主,因此放在use中
3、分析
输入:程序流图,且基本块的use集和def集已计算完毕
输出:每个基本块入口和出口处的
i
n
[
B
]
in[B]
in[B]和
o
u
t
[
B
]
out[B]
out[B]
如果计算得到in[B]与此前计算得出的in[B]不同,则循环执行,直到所有基本块的in[B]集合不再产生变化为止。
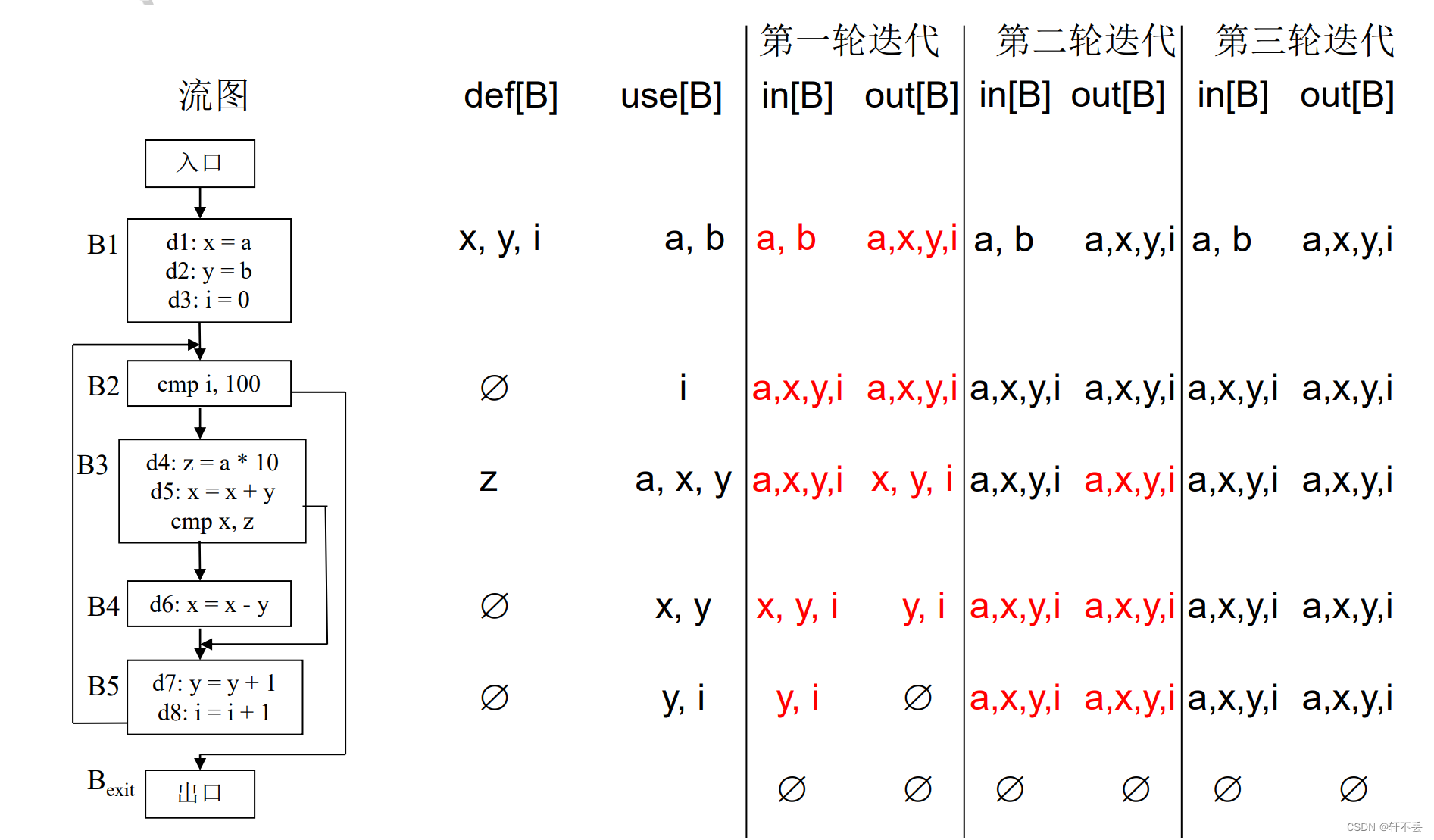
根据in和out的活跃变量即可删除死代码
4、可达定义分析
1)任务
– 在程序的某个静态点p(例如某个代码、基本块)执行前后
– 某个变量可能出现的值都是在哪里被定义的
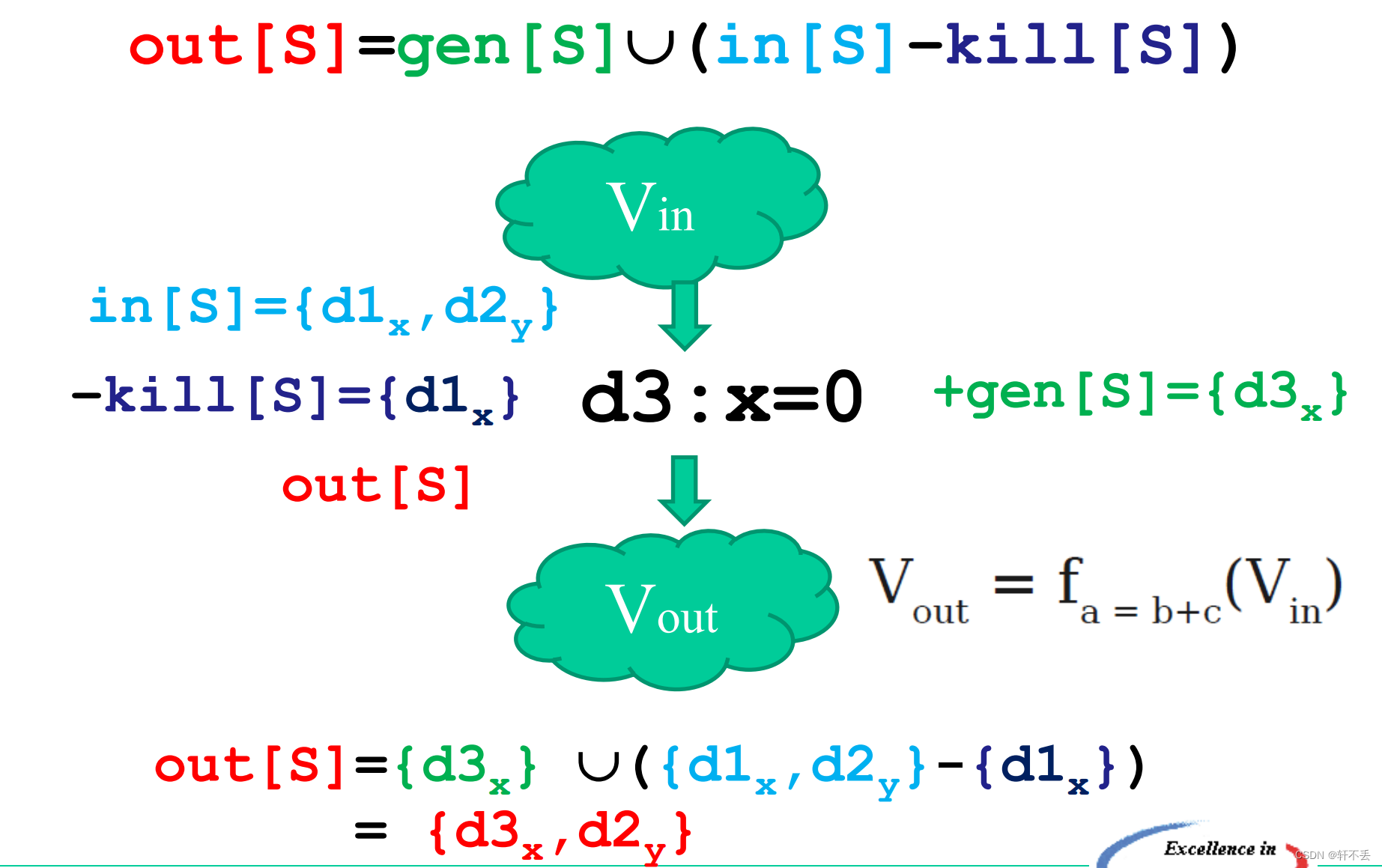
2)分析

比如同一个语句块中一个变量定义多次,则后面会将前面覆盖掉
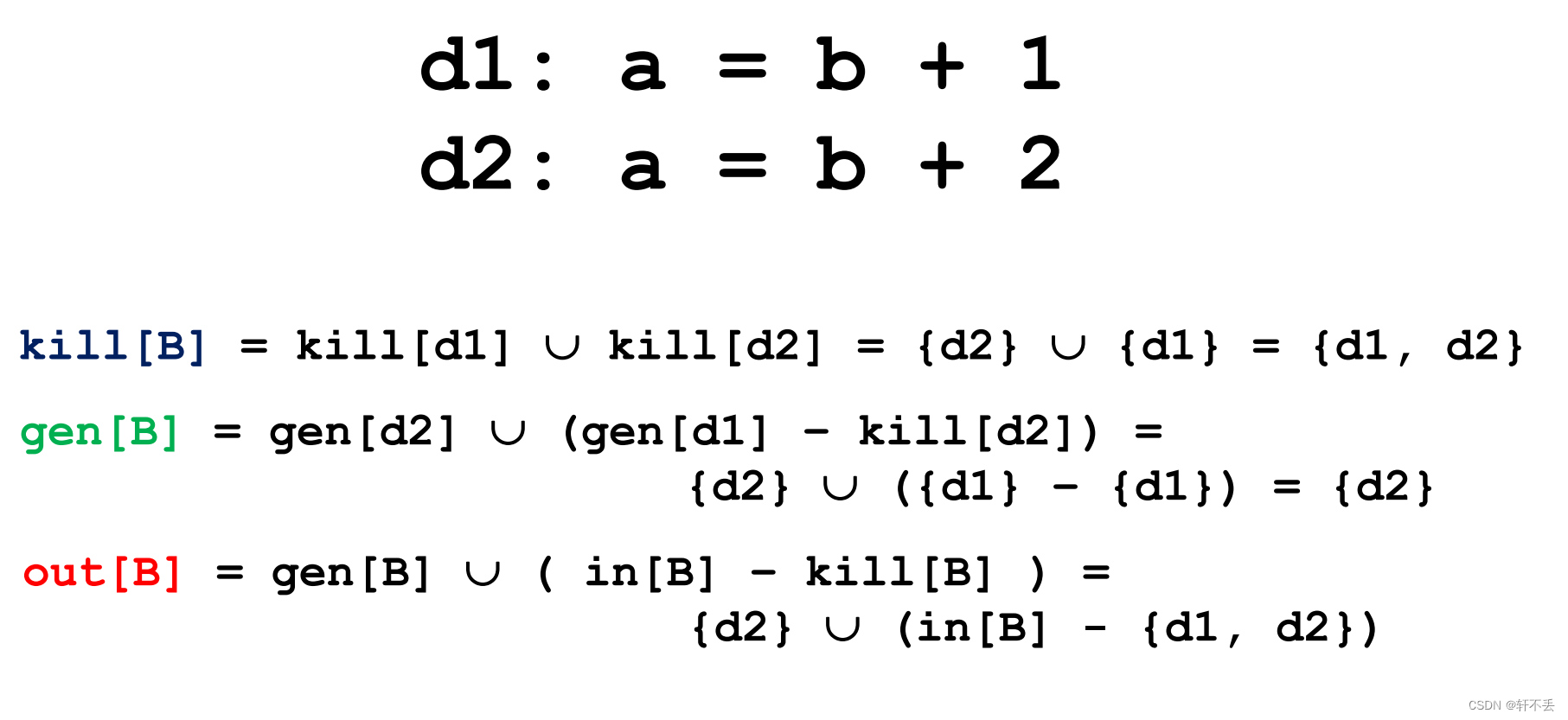
其中:

举例:

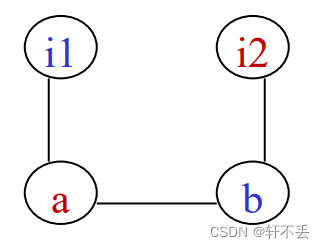
5、define-use链
1)概念
变量的定义-使用链(Define-Use链),变量的某一定义点,以及所有可能使用该定义点所定义变量值的使用点所组成的一个链。

因此可以赋值成:
七、静态单赋值SSA
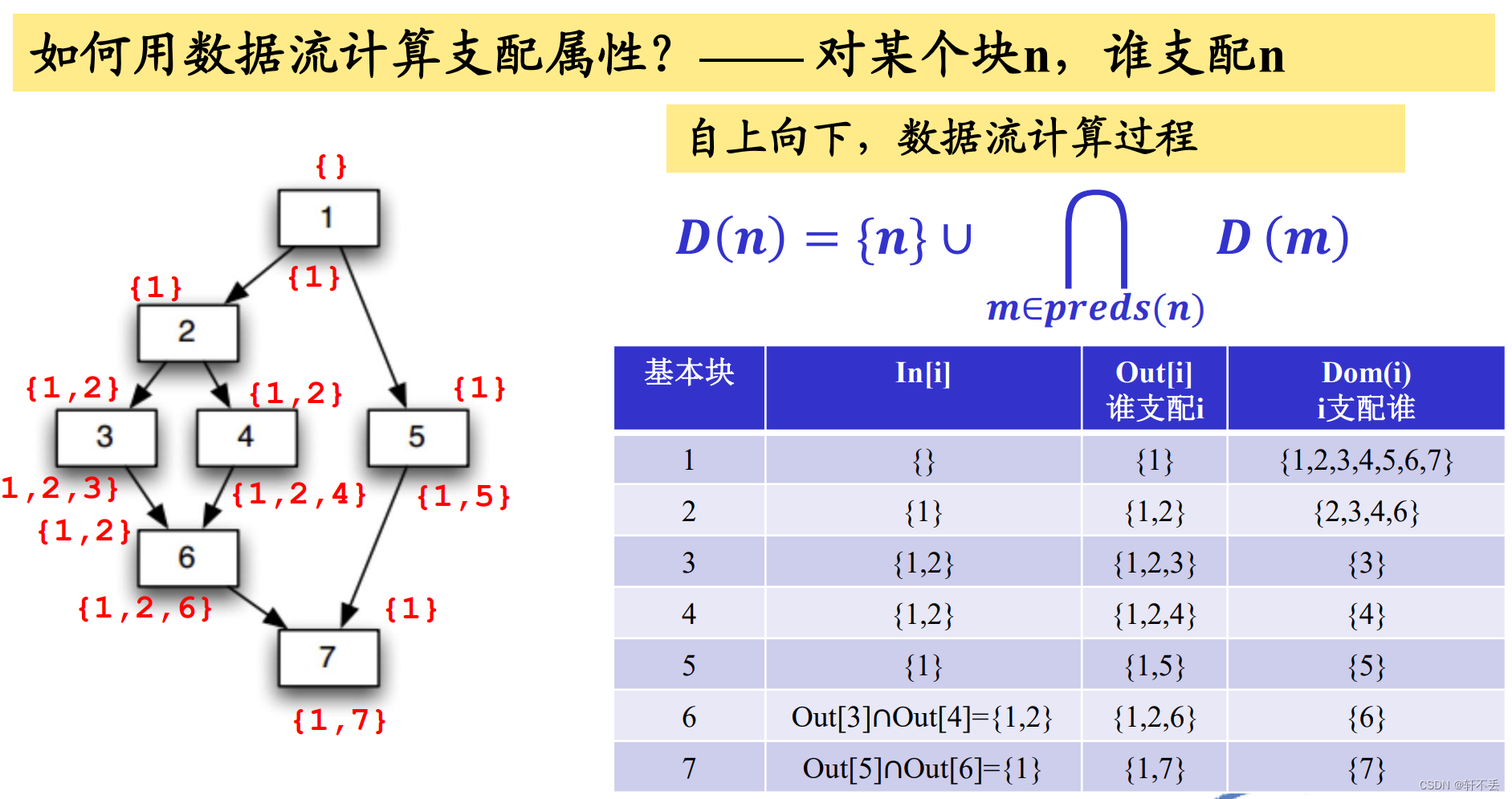
1、前置知识-支配属性
1)概念
节点D支配节点N:如果从开始到N的每条路径都通过D
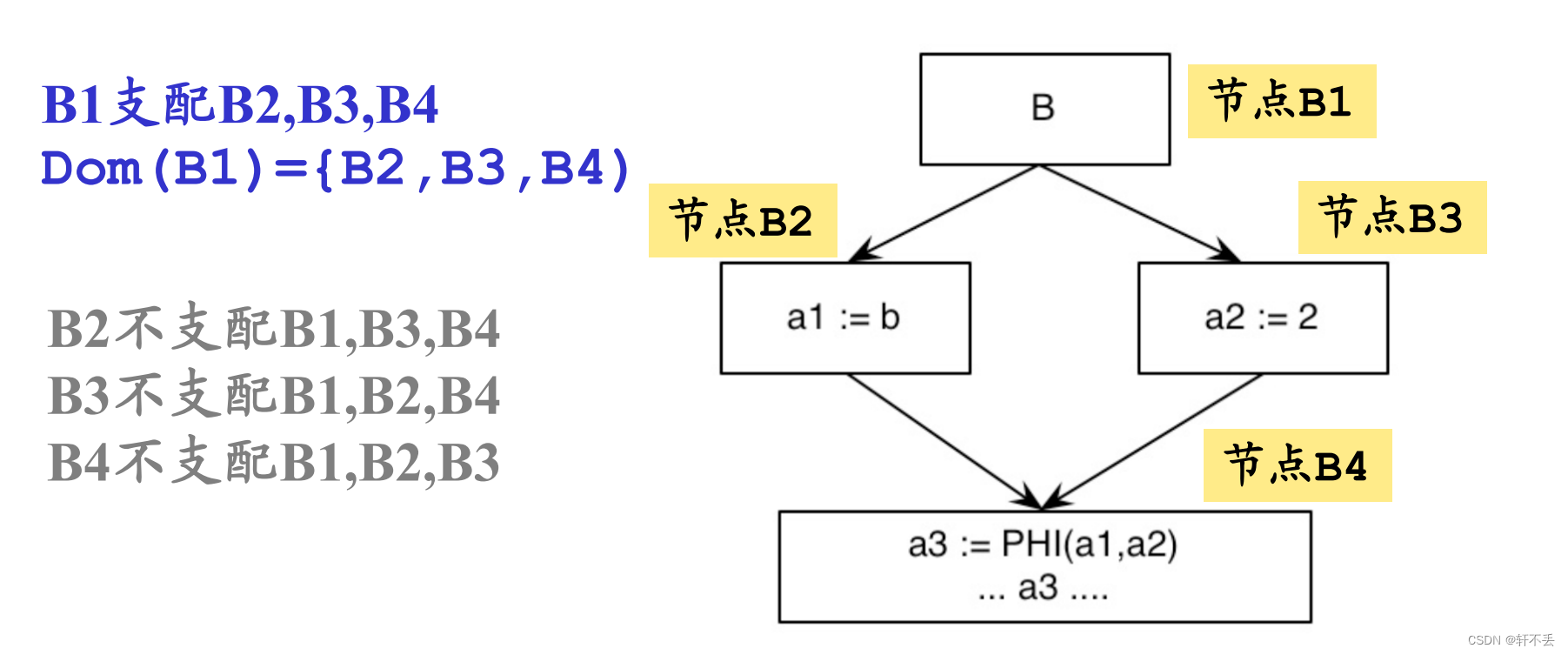

2)计算
利用数据流计算
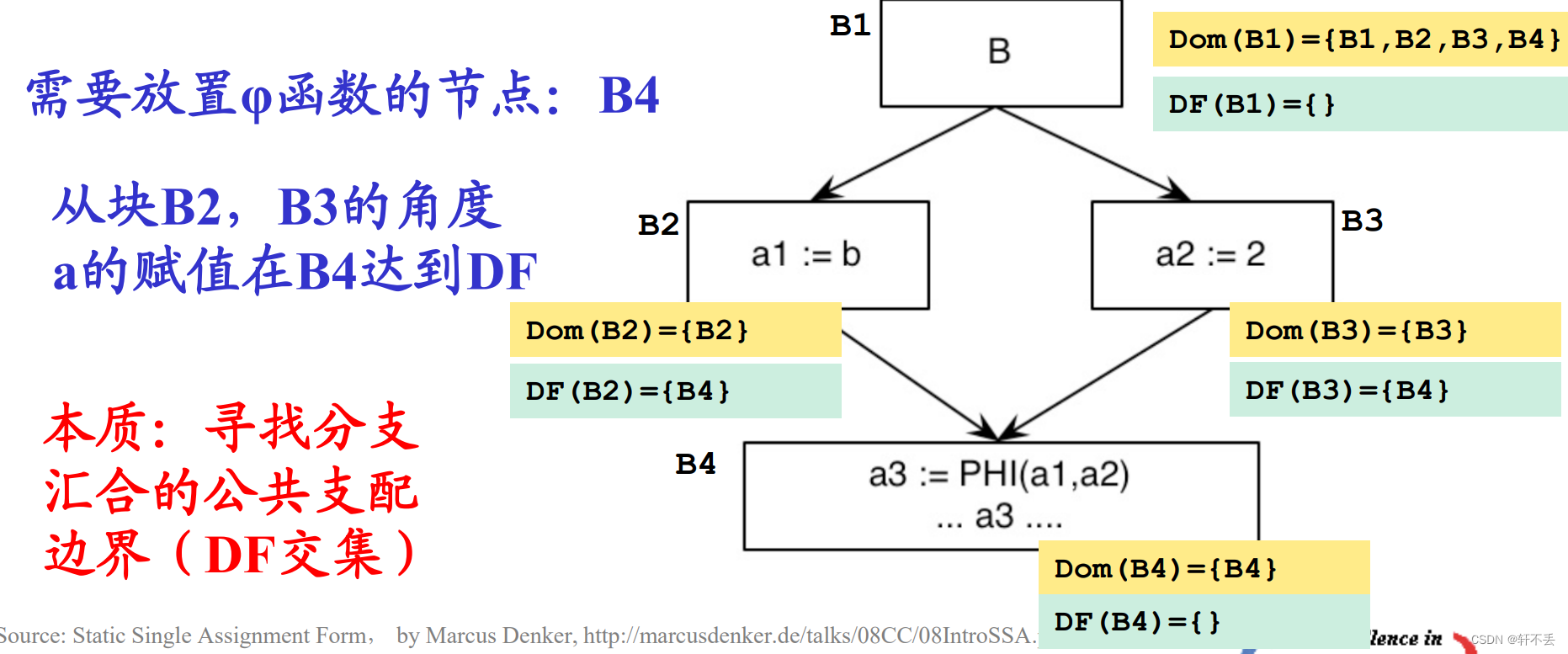
3)支配边界
X的支配边界
D
F
(
X
)
DF(X)
DF(X) ={Y | 存在一个从X->Y的路径,且Y是这个路径上第一个不被X严格支配的节点。

2、概念
SSA:Static Single Assignment 是一种基于三元式或四元式的中间语言的表示形式,其目的是支撑静态优化。
每个变量只有一个定义,每一次使用变量的时候清楚的知道变量是在哪里定义的。
不相关的变量被改成了不同的名字
Φ函数
(phi)通常放置在基本块的开始,根据控制流选择变量的值
a
1
:
=
Φ
(
a
1
,
a
2
,
…
,
a
k
)
a1:= Φ(a1, a2, …, ak)
a1:=Φ(a1,a2,…,ak):表示当前基本块有 k 个前驱基本
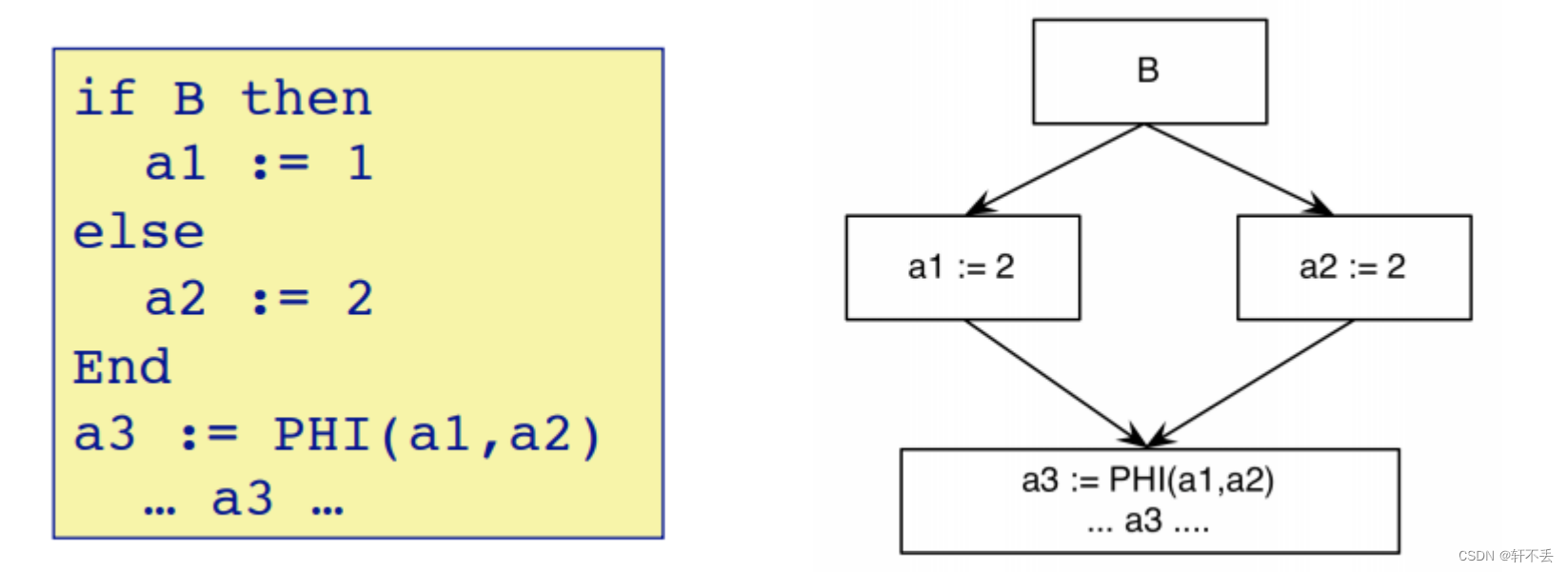
通常在优化处理的开始,将IR转化为SSA形式
3、SSA的支配属性
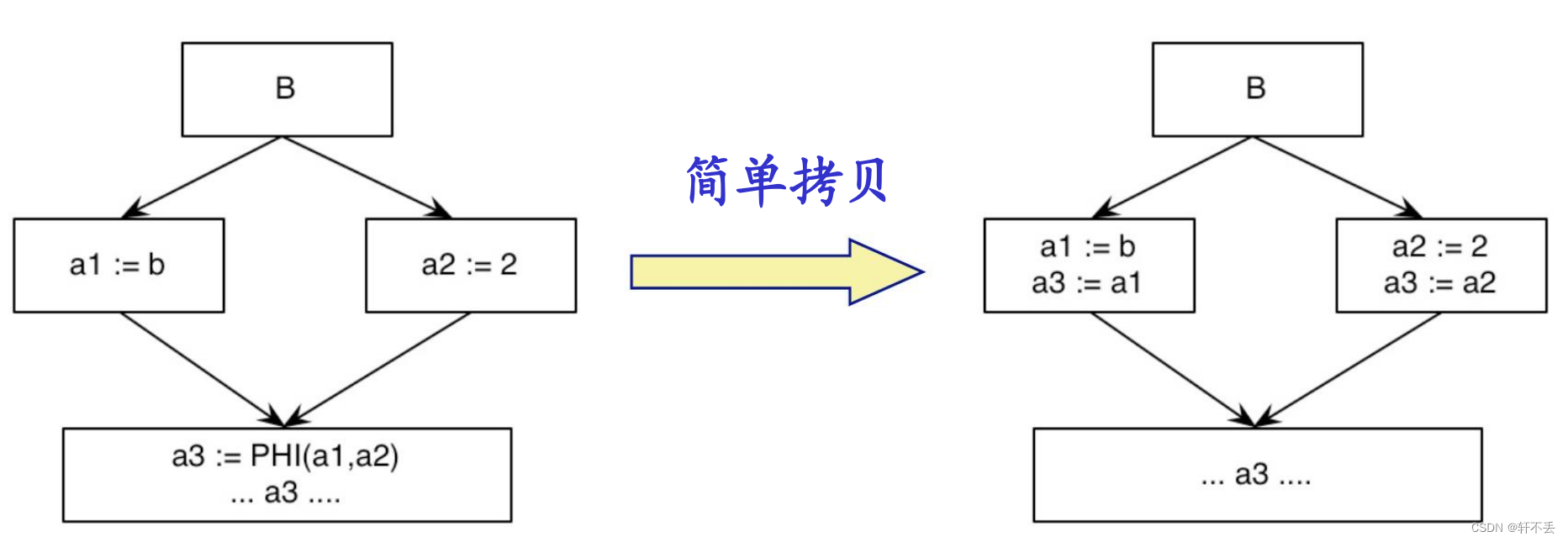
4、消除SSA
八、循环优化
1、发现循环
找回边,
n
−
>
d
n->d
n−>d,且不经过d能够到达n的所有节点(含n)

2、优化点
1)循环不变式(Loop invariant)代码外提(code motion)

2)循环展开
将构成循环体的代码(不包括控制循环的测试和转移部分),重复产生许多次(这可在编译时确定),而不仅仅是一次,以空间换时间。
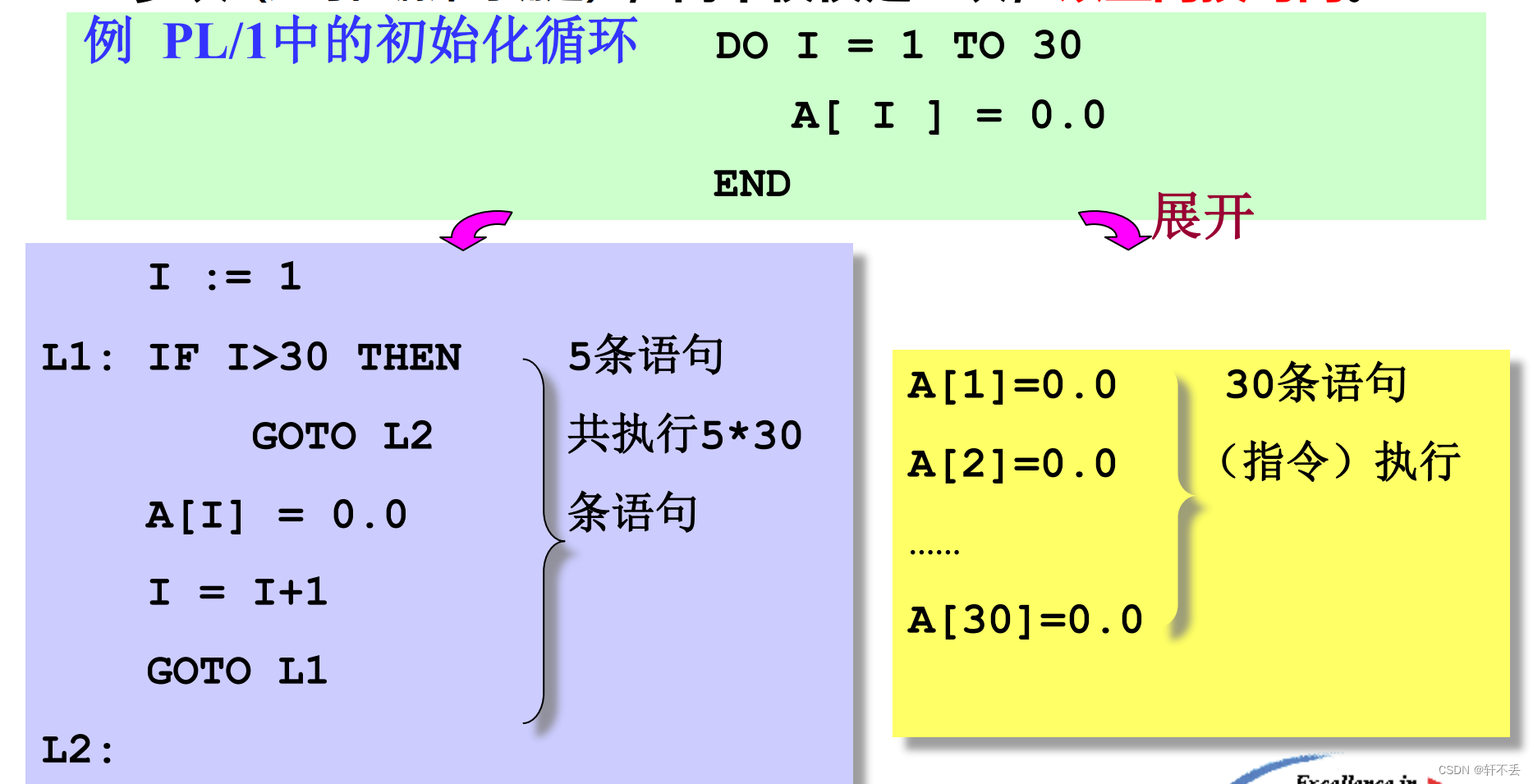
3)其他方法
- 把多重嵌套的循环变成单层循环
- 循环拆分(Loop Distribution)
- 循环融合(Loop Fusion )
- 循环交换(Loop Interchange)
- 循环并行(Loop Parallelization)
九、过程间分析与跨函数优化
1、内联:in_line 展开
把过程(或函数)调用改为in_line展开可节省许多处理过程(函数)调用所花费的开销。

十、总结

















 5813
5813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









