







本人对前段时间的比赛做个小总结,方便后续回顾学习
一、赛题介绍
赛题分享安排:
Task1:赛题理解及baseline
Task2:数据增广方法
Task3:网络模型结构发展
Task4:评价函数及损失函数
Task5:模型训练与验证
Task6:分割模型模型集成
竞赛主题:
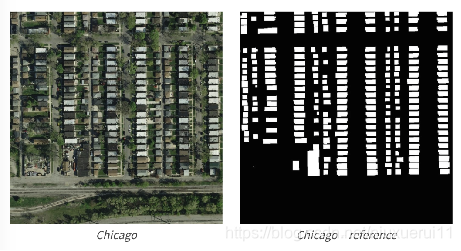
以计算机视觉为背景,要求选手使用给定的航拍图像训练模型并完成地表建筑物识别任务,是一个典型的语义分割问题。
竞赛目标:
通过对本次竞赛内容的学习和练习,掌握计算机视觉中语义分割基本技能,提高数据建模能力
赛题数据:
本赛题使用航拍数据,需要参赛选手完成地表建筑物识别,将地表航拍图像素划分为有建筑物和无建筑物两类。因此标签为有建筑物的像素。赛题原始图片为 jpg 格式,标签为 RLE 编码的字符串。

数据集:
train_mask.csv:存储图片的标注的rle编码;
train和test文件夹:存储训练集和测试集图片;
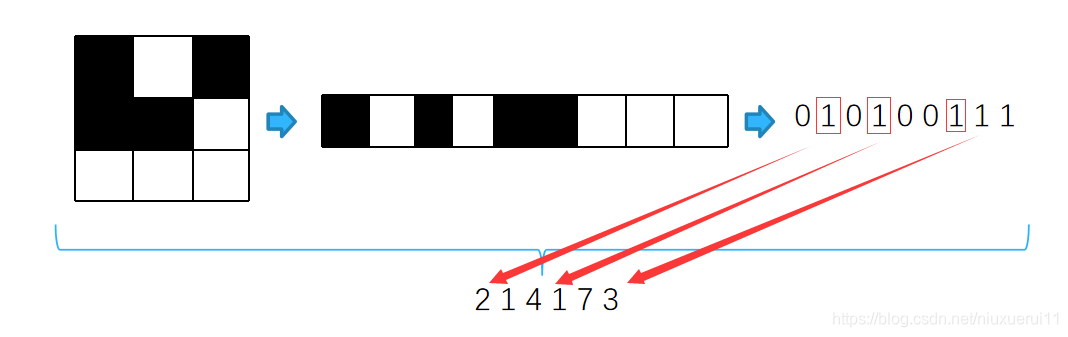
关于rle编码:
RLE全称(run-length encoding),翻译为游程编码或行程长度编码,对连续的黑、白像素数以不同的码字进行编码。RLE是一种简单的非破坏性资料压缩法,经常用在在语义分割比赛中对标签进行编码。
评价指标:
赛题使用 Dice coefficient来衡量选手结果与真实标签的差异性,Dice coefficient 可以按像素差异性来 比较结果的差异性。
Dice coefficient 的具体计算方式如下:
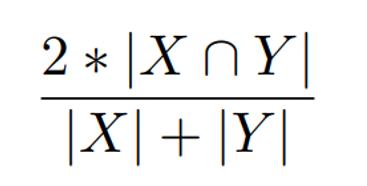
二、Baseline
语义分割问题的本质是分类问题,与图片分类问题不同的是语义分割要做的是对图片上每个像素进行分类,对于本赛题而言,是个二分类问题。
即将图片上每个像素分为有建筑和无建筑两类。
baseline实现思路:
1、数据集读取
2、构建语义分割模型
3、训练和验证
三、知识点
Baseline相关知识点:
使用pytorch读取数据集
rle的概念及其编解码过程
构建语义分割模型
加载ImageNet预训练模型
模型的训练及验证
模型的保存及加载
对于baseline如何深入?
调参
对参数进行消融实验,找到表现最佳的一组参数作为新的baseline数据层面
加入其他数据增强方法,如随机缩放、随机旋转等模型层面
尝试更加强大的语义分割模型,如UNet、PSPNet等后处理
多模型融合,投票、求平均


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











