











字节跳动:大模型网络实践分享
自2019年起,字节跳动公司便开始着手白盒项目。2020年,推出了首款接入交换机——25G型号,随后逐步实现软硬件的自主研发。在当前一代产品中,已经实现了100G接入、25.6T400G互联,为数据中心的大规模部署奠定了基础。最新的交换机产品为51.2T,配备了64和800G的自主研发设备,主要应用于AI大模型网络。此外,字节还研发了P4可编程交换机,适用于网关、公有云、混合云、边缘安全等可编程场景。

LPO模块通过移除DSP,实现了功耗成本和延时的降低。其独特的MAC PCB板技术,支持64Gb和800Gb的数据传输。此外,该模块还在技术层面进行了创新,并发表了相关论文。
除了端口面板,还增加了可插拔管理板。此板内含CPU、内存和磁盘等关键部件,之所以设计成可插拔,是因为这些部件在大规模运维中故障率较高。如此一来,如遇内存损坏等问题,无需整机更换,只需替换管理板即可。
字节跳动的Lambda OS是一款基于SONiC开发的操作系统,我们研发这款自研交换机的目的并非仅仅为了实现设备自研,更重要的是解决大规模网络中所面临的诸多挑战。这包括自动化管控、监控以及升级热补丁等问题。我们必须全面攻克这些问题,才能确保这款设备的真正自研价值。
我们提供丰富的可视化功能,涵盖了丢包、流等各个方面。此外,我们还探索了RDMA端网融合技术,并在设备中引入了BMC以实现硬件监控。关于BMC与Sonic系统的协同作战,我们也将深入探讨。敬请期待!

我想谈论一个特殊话题:随着设备不断演进,芯片能力的提升至关重要。因此,我们的研发工作主要集中在芯片领域。基于此,我们开发了一个基于SAI的自动化测试框架,只需将SAI代码嵌入dock中,即可独立开发、调试和编写自动化测试用例,实现每一代设备的独立演进。这一方法在实践中取得了良好的效果。

我们再分享一下热门AI大模型网络,如51.2T交换机,专为大模型设计。我们的网络采用统一的大模型网络结构,即GPU Server中同一编号的GPU连接在同一轨道上。这种拓扑结构能有效匹配AI大模型训练和推理需求,提升网络性能。
在网络领域,关键问题是负载均衡。我们所遇到的拥塞问题,很大程度上源于负载不均衡。过去我们主要依赖哈希方法,如今在AI模型中,越来越多的人选择使用DLB负载均衡。DLB的优势在于能够实时地根据设备的链路状态和拥塞情况进行动态调整。
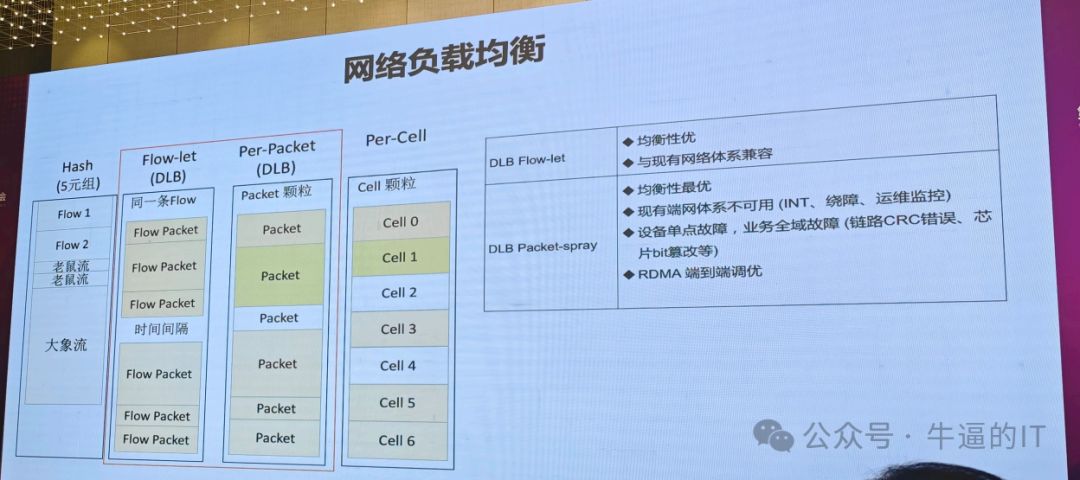
在网络编程中,主要有两种模式:flowlet和Packet。Flowlet是一种基于流的模式,它可以在流间歇时进行切换。Packet则是将流的维度再切小,并进行细分,以便对每个报文进行动态负载均衡。报文维度越小,负载均衡效果越好。此外,还有一个CELL模式,它将一个报文再切分成最小颗粒度。
我这里想分享的是说,我们DLB有两种模式,flowlet、Packet,我们到底怎么选,我这里列了一些优缺点,首先flowlet,它还是有流的维度,流在我们运维过程中是非常关键的,它是起到业务和我们网络之间桥梁的作用,业务说我有一个问题,他其实告诉我说他哪条流有问题,然后我们基于这个流的切入点,我们再去定位,我们所有的这些运维的体系、监控的体系,都是围绕着这个点去构建。所以flowlett这个模式,均衡性相对哈希肯定是有提升的,同时它与我们现有的网络运维体系是比较兼容的。
Packet的优势在于性能最大化,实现均衡。它摒弃了流的概念,对我们的网络运维体系构成颠覆,因此挑战颇大。过去我们一直依赖INT技术,它是以流为单位的监控方式。
单点故障是指在一条链路上的一个节点出现故障时,会影响到整个业务的运行。过去,这种故障可能只会影响到那条链路上的几条流,但现在,由于技术的进步和应用场景的变化,这种故障可能会影响到所有的流。因此,我们需要更加重视单点故障对业务的影响,并采取相应的措施来避免或减少其对我们业务的影响。
在当前挑战背景下,我认为这是我们自研交换机的机会。因为过去的切入点已经消失,我们可以利用设备上的监控能力作为新的切入点。请大家关注这个方向,共同挖掘设备的潜力。
刚才提到了DLB,它仅基于单台设备的信息和链路拥塞状况。为了实现全局拓扑链路级别支持,我们与博通深度合作研发了GLB。通过GLB,我们能够查看整体拓扑,并基于此分析POD级别的链路负载和拥塞情况。此外,GLB还支持三层架构。

我们去做这样一个事情的时候,我们到底要做什么工作,或者说对于我们今天讨论的主题SONiC来说,到底挑战是什么。其实我们的数据中心里面因为是超大规模的,所以过去所有的解决方案其实大多都是分布式的解决方案,我的路由其实是我单台设备的信息,那我们今天要去解决的是我要去看整个网络拓扑的信息,所以这个地方可能会引入比如说控制面怎么去设计,包括路由,它不只是一个芯片,我怎么去做负载均衡的问题,它可能是说我整个全局拓扑里面的这些路由的信息,怎么和我的ECMP配合。
链路故障是云计算中常见的问题之一,它会影响计算性能。据统计,链路故障对计算性能的影响高达5%。为了解决这个问题,我们需要快速收敛链路故障。
下一跳分离是一种非常好的技术,它与路由强绑定。在POD中,每个设备都是一个下一跳,因此它可能涉及到许多下一跳。这可能会导致全新的问题,例如如何解决链路级别的和整个POD维度的问题,以实现快速收敛。
我们引以为豪的是我们的可编程芯片系列,这款产品集成了P4,能够支持FPGA和DPU网卡,同时也能适配X86 CPU。DPU具有独立的CPU和系统,这使得在一台设备内安装多个GPU网卡时,虽然物理形态看似单一,但实际上它形成了一个复杂的逻辑拓扑。这种特性在运维管控上无疑带来了挑战。

在当前场景下,我们将Lambda OS系统融入DPU,构建了一个多Lambda OS分布式协同解决方案,从而实现自动化装机和配置的一站式解决。
在P4分会场,我巧遇一位同学正在分享他遇到的一体化交付问题。在他的设备中,DPU的装机过程与服务器PXE装机流程紧密相连。然而,通过这套系统,我们能够实现一键装机,简化整个流程。
经过3年的努力,我们在数据中心的大规模部署方面取得了显著成果。回顾过去七八年,这是当时难以想象的事情。如今,我们能够迅速实现这一目标,离不开SONiC开源社区的支持以及在座开放白盒生态合作伙伴们的共同努力。在此,向大家表示诚挚感谢!
随着AI时代的到来,网络已从过去的底层逐渐走向前台。今天,基于开源的AI网络正处于黄金时期,让我们共同见证这一历史性时刻。
-对此,您有什么看法见解?-
-欢迎在评论区留言探讨和分享。-




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











