







深入解析Mixture of Attention Heads (MoA):革新Transformer注意力机制
在自然语言处理(NLP)领域,Transformer架构凭借其强大的多头注意力(Multi-Head Attention, MHA)机制,极大地推动了模型性能的提升。然而,随着模型规模的不断扩大,计算成本的激增成为瓶颈。Mixture of Experts (MoE) 作为一种条件计算技术,通过稀疏激活模型参数显著降低了计算负担,但其应用主要集中在Transformer的Feed-Forward Network (FFN) 层。近期,发表在arXiv上的论文《Mixture of Attention Heads: Selecting Attention Heads Per Token》(arXiv:2210.05144)提出了一种新颖的注意力机制——Mixture of Attention Heads (MoA),将MoE的思想引入多头注意力模块,为研究者提供了一种高效且可扩展的替代方案。本文将面向熟悉MoE的研究者,详细分析MoA的核心设计,特别是其如何通过动态选择注意力头(Attention Heads)来实现性能提升。
MoA的核心思想
MoA的核心创新在于将MoE的条件计算机制与多头注意力结合,提出了一种按token动态选择注意力头的架构。传统MHA为每个输入token计算所有注意力头的输出,然后将其结果合并。而MoA则通过一个路由网络(Routing Network),为每个token动态选择一组特定的注意力头(称为“注意力专家”,Attention Experts),并以加权求和的方式生成最终输出。这种机制不仅提升了计算效率,还通过稀疏激活实现了参数的可扩展性,同时保留甚至增强了模型性能。
MoA的架构如论文中的图1和图2所示,主要包含以下两个核心组件:
- 路由网络(Routing Network):负责为每个token选择一组注意力专家,并分配相应的权重。
- 注意力专家(Attention Experts):一组具有独立参数的注意力头,每个专家负责处理输入的查询(Query)、键(Key)和值(Value)序列。
以下将详细剖析MoA的注意力机制设计,重点探讨其如何选择不同的注意力头。
MoA的注意力机制详解
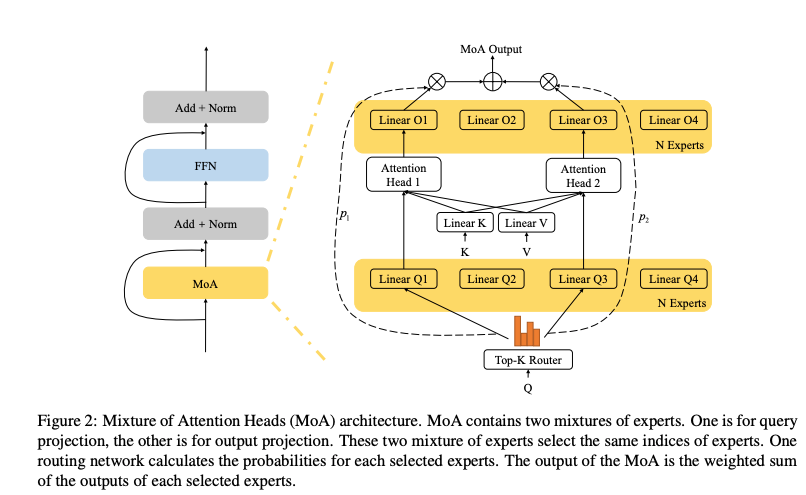
1. 总体架构
MoA的输入与标准MHA一致,包括查询序列 ( Q Q Q )、键序列 ( K K K ) 和值序列 ( V V V )。对于时间步 ( t t t ) 的查询向量 ( q t q_t qt ),MoA通过路由网络动态选择 ( k k k ) 个注意力专家(从总共 ( N N N ) 个专家中选取),并为每个选中的专家分配权重 ( w i w_i wi )。最终输出 ( y t y_t yt ) 是选定专家输出的加权和,数学表达如下:
y t = ∑ i ∈ G ( q t ) w i , t ⋅ E i ( q t , K , V ) y_t = \sum_{i \in G(q_t)} w_{i,t} \cdot E_i(q_t, K, V) yt=i∈G(qt)∑wi,t⋅Ei(qt,K,V)
其中:
- ( G ( q t ) G(q_t) G(qt) ) 表示路由网络为 ( q t q_t qt ) 选择的 ( k k k ) 个专家的索引集合。
- ( E i ( q t , K , V ) E_i(q_t, K, V) Ei(qt,K,V) ) 是第 ( i i i ) 个注意力专家的输出。
- ( w i , t w_{i,t} wi,t ) 是路由网络为专家 ( i i i ) 分配的权重。
与标准MHA不同,MoA并非对所有注意力头进行计算,而是通过稀疏选择减少计算量,同时允许更多的专家(即注意力头)以较低的计算成本加入模型。
2. 路由网络的设计
路由网络是MoA的核心,它决定了如何为每个token选择合适的注意力专家。具体流程如下:
(1) 计算路由概率
路由网络通过一个线性层 ( W g ∈ R d m × N W_g \in \mathbb{R}^{d_m \times N} Wg∈Rdm×N )(其中 ( d m d_m dm ) 是模型的隐藏状态维度,( N N N ) 是专家总数)对查询向量 ( q t q_t qt ) 进行投影,生成每个专家的路由概率:
p i , t = Softmax i ( q t ⋅ W g ) p_{i,t} = \text{Softmax}_i(q_t \cdot W_g) pi,t=Softmaxi(qt⋅Wg)
这里的 ( p i , t p_{i,t} pi,t ) 表示第 ( i i i ) 个专家被选中的概率。Softmax 操作确保所有专家的概率之和为1。
(2) 选择Top-k专家
基于路由概率 ( p i , t p_{i,t} pi,t ),路由网络通过Top-k操作选择概率最高的 ( k k k ) 个专家:
G ( Q ) = TopK ( p i , t , k ) G(Q) = \text{TopK}(p_{i,t}, k) G(Q)=TopK(pi,t,k)
这意味着只有 ( k k k ) 个专家会被激活,其余专家的输出被忽略,从而实现稀疏计算。
(3) 权重归一化
为了确保选定专家的权重之和为1,MoA对选定专家的概率进行归一化处理,并引入了 Detach 操作以阻止梯度回传到分母部分:
w i , t = p i Detach ( ∑ j ∈ G ( q t ) p j ) w_{i,t} = \frac{p_i}{\text{Detach}\left(\sum_{j \in G(q_t)} p_j\right)} wi,t=Detach(∑j∈G(qt)pj)pi
Detach 操作是一个关键技巧,论文中提到它有助于路由网络学习更优的概率分布,避免梯度干扰。
(4) 辅助损失
为了解决MoE模型中常见的负载不均衡问题(即某些专家被过度使用,而其他专家被忽略),MoA引入了两种辅助损失:
- 负载均衡损失 ( L a L_a La ):鼓励专家的均匀使用,定义为:
L a ( Q ) = N ⋅ ∑ i = 1 N f i ⋅ P i L_a(Q) = N \cdot \sum_{i=1}^N f_i \cdot P_i La(Q)=N⋅i=1∑Nfi⋅Pi
其中 ( f i f_i fi ) 是分配给第 ( i i i ) 个专家的token数量,( P i P_i Pi ) 是该专家的路由概率之和。这种损失通过惩罚过高的 ( P i P_i Pi ) 来平衡专家负载。
- 路由z-loss ( L z L_z Lz ):通过惩罚过大的路由logits来稳定训练:
L z ( x ) = 1 T ∑ j = 1 T ( log ∑ i = 1 N e x i , t ) 2 L_z(x) = \frac{1}{T} \sum_{j=1}^T \left( \log \sum_{i=1}^N e^{x_{i,t}} \right)^2 Lz(x)=T1j=1∑T(logi=1∑Nexi,t)2
最终损失函数为:
L = L model + ∑ ∀ MoA module ( α L a + β L z ) L = L_{\text{model}} + \sum_{\forall \text{MoA module}} \left( \alpha L_a + \beta L_z \right) L=Lmodel+∀MoA module∑(αLa+βLz)
其中 ( α = 0.01 \alpha = 0.01 α=0.01 ),( β = 0.001 \beta = 0.001 β=0.001 )。论文通过消融实验(表7)验证了这些辅助损失的有效性。
3. 注意力专家的设计
每个注意力专家是一个独立的注意力头,包含四个投影矩阵:( W q W^q Wq )、( W k W^k Wk )、( W v W^v Wv )、( W o W^o Wo )。其计算过程与标准MHA类似,但有一些优化以降低计算复杂度:
(1) 注意力计算
对于查询向量 ( q t q_t qt ),专家 ( i i i ) 首先计算注意力权重:
W i , t att = Softmax ( q t W i q ( K W i k ) T d h ) W_{i,t}^{\text{att}} = \text{Softmax}\left( \frac{q_t W_i^q (K W_i^k)^T}{\sqrt{d_h}} \right) Wi,tatt=Softmax(dhqtWiq(KWik)T)
其中:
- ( W i q ∈ R d m × d h W_i^q \in \mathbb{R}^{d_m \times d_h} Wiq∈Rdm×dh ) 是查询投影矩阵。
- ( W i k ∈ R d m × d h W_i^k \in \mathbb{R}^{d_m \times d_h} Wik∈Rdm×dh ) 是键投影矩阵。
- ( d h d_h dh ) 是注意力头的维度。
接着,计算值的加权和:
o i , t = W i , t att V W i v o_{i,t} = W_{i,t}^{\text{att}} V W_i^v oi,t=Wi,tattVWiv
其中 ( W i v ∈ R d m × d h W_i^v \in \mathbb{R}^{d_m \times d_h} Wiv∈Rdm×dh ) 是值投影矩阵。
最后,通过输出投影矩阵 ( W i o ∈ R d h × d m W_i^o \in \mathbb{R}^{d_h \times d_m} Wio∈Rdh×dm ) 将结果映射回隐藏状态空间:
E i ( q t , K , V ) = o i , t W i o E_i(q_t, K, V) = o_{i,t} W_i^o Ei(qt,K,V)=oi,tWio
(2) 参数共享优化
为了进一步降低计算复杂度,MoA在所有专家间共享 ( W k W^k Wk ) 和 ( W v W^v Wv ),仅让 ( W q W^q Wq ) 和 ( W o W^o Wo ) 在专家间独立。这种设计允许预计算 ( K W k K W^k KWk ) 和 ( V W v V W^v VWv ),从而显著减少矩阵乘法的开销。每个专家只需要计算查询投影 ( q t W i q q_t W_i^q qtWiq ) 和输出投影 ( o i , t W i o o_{i,t} W_i^o oi,tWio ),这对于大规模专家数量尤为重要。
4. 与标准MHA的区别
MoA与标准MHA的主要区别在于选择性激活和参数效率:
- 选择性激活:标准MHA对所有注意力头进行计算,而MoA通过路由网络为每个token选择 ( k k k ) 个专家,减少了计算量。
- 参数效率:MoA通过共享 ( W k W^k Wk ) 和 ( W v W^v Wv ),并利用稀疏激活,使得即使增加专家数量(即参数量),计算复杂度仍可控。论文中的计算复杂度分析(第4.4节)表明,当 ( k d h ≈ d m k d_h \approx d_m kdh≈dm ) 时,MoA的计算量低于MHA,而参数量也更少。
此外,MoA的专家选择机制赋予了模型更高的灵活性。不同token可以关注不同的注意力专家,这与研究中观察到的注意力头功能多样性(Voita et al., 2019)相呼应。论文通过点互信息(PMI)分析(表4)进一步展示了专家的专题化,例如某些专家专注于技术术语、位置名词或形容词。
实验结果与分析
MoA在机器翻译(WMT14 En-De和En-Fr数据集)和掩码语言建模(WikiText-103数据集)任务上进行了广泛实验。以下是关键发现:
- 机器翻译:MoA Base模型(8K8E128D)在En-Fr数据集上以69M参数取得了42.5的BLEU分数,超越了参数量更大的Transformer Big(210M,41.8 BLEU)。MoA Big模型(16K32E256D)进一步以200M参数和1220M MACs实现了29.4(En-De)和43.7(En-Fr)的BLEU分数,接近甚至超过更深的模型(如Admin 60L-12L),但计算成本仅为其一半。
- 掩码语言建模:MoA在WikiText-103上的困惑度(Perplexity)随着专家数量 ( E E E ) 和头维度 ( D D D ) 的增加而持续下降。例如,8K64E256D模型以179.91M参数达到了4.21的困惑度,优于标准Transformer的4.95。
这些结果表明,MoA通过动态选择注意力头,不仅提升了性能,还在参数和计算效率上实现了显著优化。
MoA的优点与局限性
优点
- 高效性:MoA通过稀疏激活和参数共享大幅降低了计算复杂度,适合大规模模型。
- 可扩展性:增加专家数量(( E E E ))可在不显著增加计算成本的情况下提升性能。
- 可解释性:专家的专题化(如表4所示)为分析注意力机制提供了新视角。
局限性
- 扩展极限:论文仅测试了最多64个专家,而FFN-MoE模型可扩展至数千个专家。MoA的扩展极限尚待探索。
- 实现优化:当前实现存在内存拷贝开销,影响运行时间。未来需在CUDA内核级别进行优化。
- 超参数敏感性:与Transformer类似,MoA需要仔细调参以达到最佳性能。
总结
Mixture of Attention Heads (MoA) 是一种创新的注意力机制,通过将MoE的条件计算思想引入多头注意力,实现了按token动态选择注意力头的目标。其路由网络和共享参数设计显著提升了计算和参数效率,同时保持甚至超越了标准MHA的性能。对于熟悉MoE的研究者而言,MoA不仅提供了一种新的Transformer优化思路,还通过专家专题化为模型可解释性研究开辟了新方向。未来,优化MoA的实现并探索其在大规模场景下的潜力,将是值得深入研究的方向。
后记
2025年5月14日于上海,在grok 3大模型辅助下完成。

















 240
240

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









