







看过李航老师的《统计学习方法》的同学都知道,机器学习(统计学习)的三要素为:模型、策略、和算法。其中,模型就是所要学习的条件概率分布或者决策函数。模型的假设空间包含所有可能的条件概率分布或决策函数。统计学习的目标在于从假设空间中选取最优模型。其中的两种选择最优模型的策略就是经验风险最小化和结构风险最小化。而算法负责根据策略求解出最优模型。
今天我尝试着给出《统计学习方法》第9页的“当模型是条件概率分布,损失函数是对数损失函数时,经验风险最小化就等价于极大似然估计。”的简单证明,有不对的地方请大家指正。
首先给出经验风险最小化的公式:
其中,F是假设空间,f是模型,L是损失函数,n是观察到的样本数。
下面引用一段其它博客的关于最大似然估计的内容:
**************************我是华丽的分割线***********************
最大似然估计中采样需满足一个很重要的假设,就是所有的采样都是独立同分布的。下面我们具体描述一下最大似然估计:
首先,假设 为独立同分布的采样,θ为模型参数,f为我们所使用的模型,遵循我们上述的独立同分布假设。参数为θ的模型f产生上述采样可表示为
为独立同分布的采样,θ为模型参数,f为我们所使用的模型,遵循我们上述的独立同分布假设。参数为θ的模型f产生上述采样可表示为

回到上面的“模型已定,参数未知”的说法,此时,我们已知的为 ,未知为θ,故似然定义为:
,未知为θ,故似然定义为:

在实际应用中常用的是两边取对数,得到公式如下:

其中 称为对数似然,而
称为对数似然,而 称为平均对数似然。而我们平时所称的最大似然为最大的对数平均似然,即:
称为平均对数似然。而我们平时所称的最大似然为最大的对数平均似然,即:

***********************我是华丽的分割线*********************
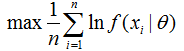
将需要求和的ln前面加上负号,也就是:
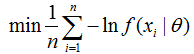
对比经验风险最小化公式:
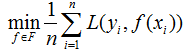
由于f( | )是模型,可以是条件概率分布模型,那么
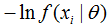















 401
401

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









