






BERT(Bidirectional Encoder Representations from Transformers)是Google AI语言研究人员发表的最新论文。 它通过在各种各样的NLP任务中展示最新结果而引起了机器学习社区的轰动,其中包括问答(SQuAD v1.1),自然语言推理(MNLI)等。
BERT的主要技术创新是将流行的attention model,Transformer的双向培训应用于语言建模。
这与以前的工作不同,后者从左到右 或 从左到右和从右到左的组合 训练查看文本序列。 论文的结果表明,经过双向训练的语言模型比单向语言模型具有更深的语言背景和流程感。 在论文中,研究人员详细介绍了一种称为Masked LM(MLM)的新技术,该技术允许在以前不可能的模型中进行双向训练。
背景
在计算机视觉领域,研究人员反复展示了transform学习的价值-使用训练有素的神经网络作为基础,在已知任务(例如ImageNet)上预先训练神经网络模型,然后执行微调。 新的特定用途模型。 近年来,研究人员已经表明,类似的技术可以在许多自然语言任务中有用。
基于功能的培训是一种不同的方法,它在NLP任务中也很流行,并且在最近的ELMo论文中得到了例证。 在这种方法中,预训练的神经网络会生成word embedding,然后将其用作NLP模型中的特征。
BERT如何工作
BERT利用Transformer(一种attention机制)来学习文本中单词(或子单词)之间的上下文关系。原始形式的Transformer包括两种独立的机制-读取文本输入的编码器和为任务生成预测的解码器。由于BERT的目标是生成语言模型,因此仅需要编码器机制。 Google在一篇论文中介绍了Transformer的详细工作原理。
与顺序读取顺序输入的文本(从左到右或从右到左)的定向模型相反,Transformer编码器一次读取整个单词序列。因此,尽管说它是非方向性的更为准确,但它被认为是双向的。此特征使模型可以根据单词的所有周围环境(单词的左右)来学习单词的上下文。
下图是对Transformer编码器的高级描述。输入是一系列令牌(单词),这些令牌首先embedding向量中,然后在神经网络中进行处理。输出是大小为H的向量序列,其中每个向量对应于具有相同索引的输入令牌。
在训练语言模型时,定义预测目标存在挑战。许多模型会按顺序预测下一个单词(例如“孩子从___回家”),这是一种定向方法,从本质上限制了上下文学习。为了克服这一挑战,BERT使用了两种训练策略:
Masked LM(MLM)
在将单词序列输入BERT之前,每个序列中15%的单词被替换为[MASK]令牌。 然后,该模型将根据序列中其他未屏蔽单词提供的上下文,尝试预测被屏蔽单词的原始值(完形填空)。 用技术术语来说,输出单词的预测需要:
在编码器输出的顶部添加分类层(一般是linear classfier)。
将输出向量与嵌入矩阵相乘,将其转换为词汇量。
用softmax计算词汇中每个单词的概率。
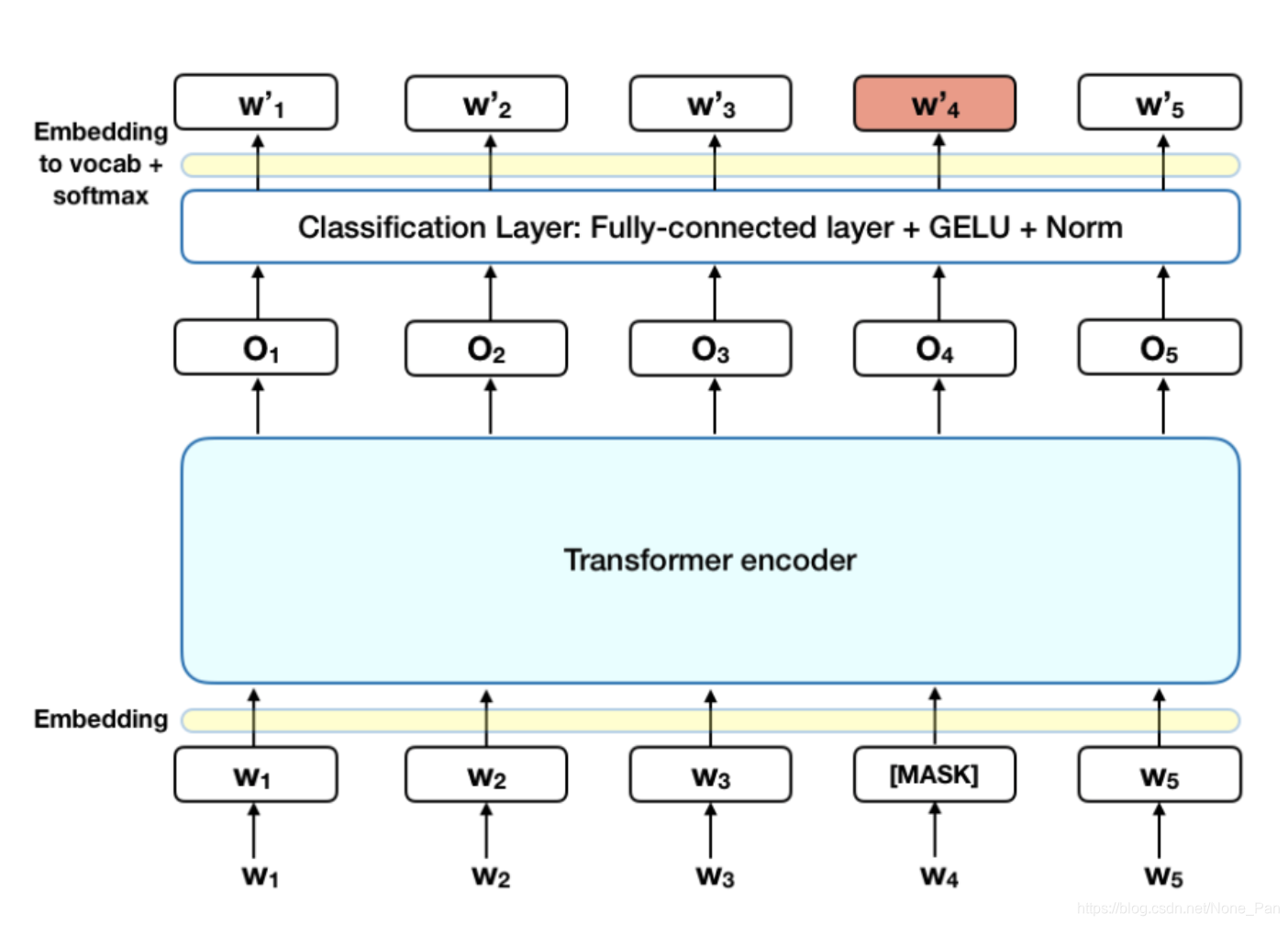
BERT损失函数仅考虑掩码值的预测,而忽略非掩码字的预测。 结果,该模型的收敛速度比方向模型慢,这一特征被上下文感知能力的提高所抵消。
Next Sentence Prediction (NSP)
在BERT训练过程中,模型接收成对的句子作为输入,并学习预测成对的第二句话是否是原始文档中的后续句子。在训练过程中,输入的50%是一对,其中第二个句子是原始文档中的后续句子,而在其他50%的输入中,从语料库中选择一个随机句子作为第二个句子。假定随机句子将与第一句断开。 (CLS用作判断是否是断开)
为了帮助模型区分训练中的两个句子,在输入模型之前,将以以下方式处理输入:
在第一个句子的开头插入一个[CLS]令牌,在每个句子的末尾插入一个[SEP]令牌。
将指示句子A或句子B的句子的embedding添加到每个标记。句子嵌入的概念类似于词汇量为2的令牌嵌入。
将位置嵌入添加到每个令牌以指示其在序列中的位置。
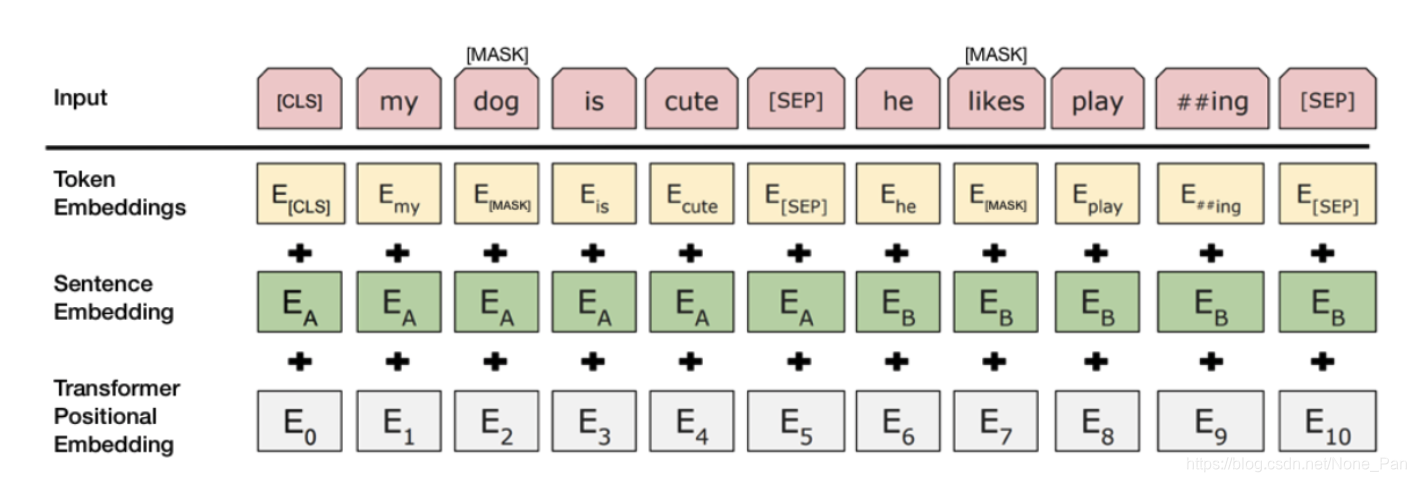
位置嵌入:BERT学习并使用位置嵌入来表达单词在句子中的位置。添加这些内容是为了克服Transformer的限制,与RNN不同,Transformer无法捕获“序列”或“顺序”信息
段嵌入:BERT也可以将一对句子作为任务的输入(问题答案)。因此,它为第一句话和第二句话学习了独特的嵌入,以帮助模型区分它们。在上面的示例中,所有标记为EA的标记都属于句子A(对于EB同样)
令牌嵌入:这些是从WordPiece令牌词汇表中为特定令牌学习的嵌入
https://www.bilibili.com/video/BV17441137fa?from=search&seid=5291431011422815882 38min开始
对于给定的令牌,其输入表示形式是通过将相应的令牌,段和位置嵌入相加来构造的。
这种全面的嵌入方案包含许多有用的模型信息。
这些预处理步骤的组合使BERT如此通用。这意味着无需对模型的体系结构进行任何重大更改,我们就可以轻松地对它进行多种NLP任务的培训。
要预测第二句话是否确实与第一句话相关(就是判断CLS 的T/F),需要执行以下步骤:
整个输入序列通过Transformer模型。
使用简单的分类层(权重和偏差的学习矩阵),将[CLS]令牌的输出转换为2×1形状的矢量。
用softmax计算IsNextSequence的概率。
在训练BERT模型时,将同时使用Masked LM和Next Sentence Prediction,目的是最小化这两种策略的组合损失函数。
如何使用BERT(微调)
将BERT用于特定任务相对简单:
BERT可用于多种语言任务,而仅在核心模型中添加一小层:
通过在[CLS]令牌(token)的Transformer输出顶部添加分类层,可以类似于“下一句分类”来完成诸如情感分析之类的分类任务。
在问答任务(例如SQuAD v1.1)中,软件会收到有关文本序列的问题,并需要在序列中标记答案。使用BERT,可以通过学习两个标记答案开头和结尾的额外矢量来训练问答模型。
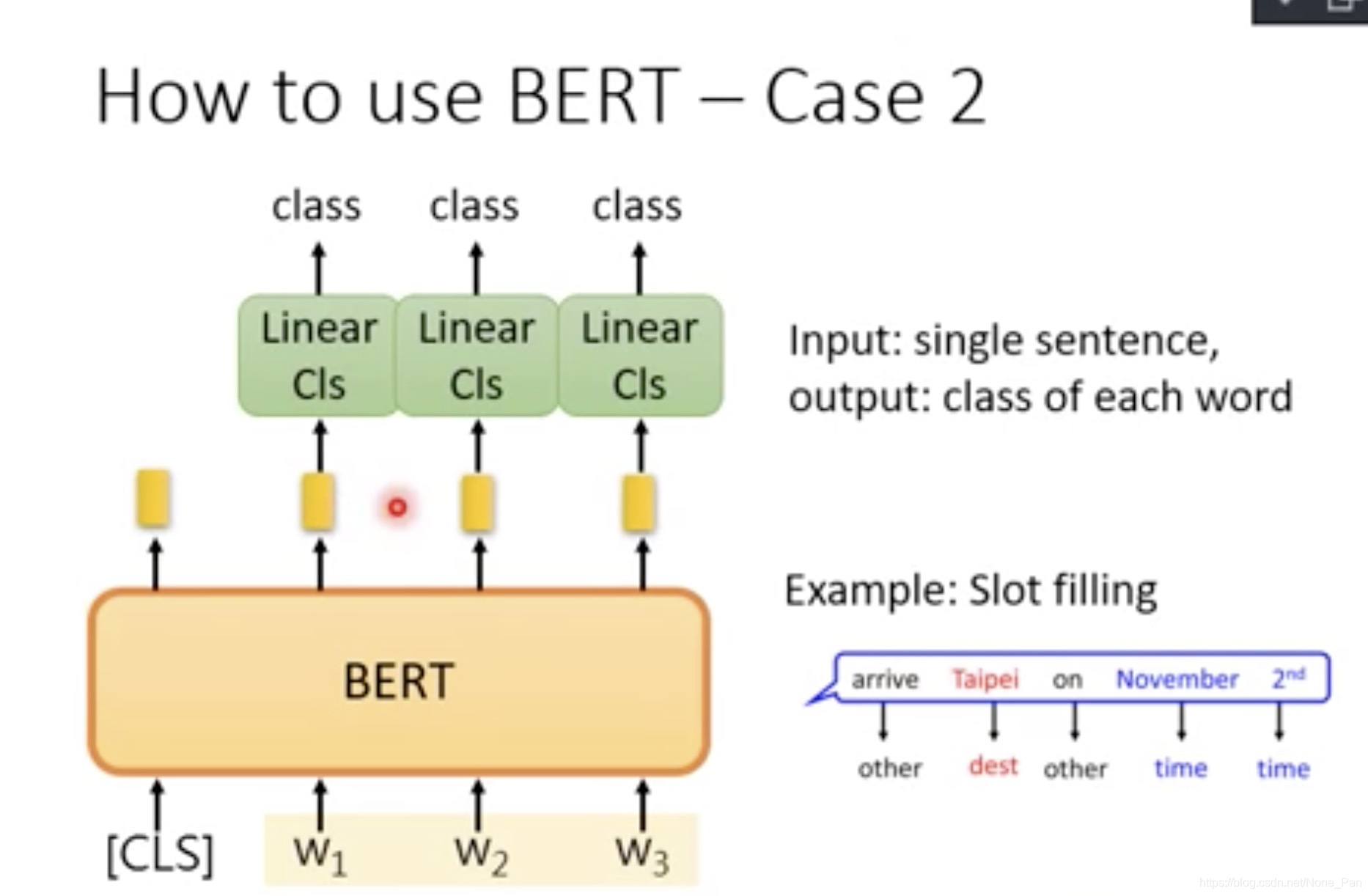
在“命名实体识别(NER)”中,该软件会接收文本序列,并且需要标记文本中出现的各种类型的实体(人,组织,日期等)。使用BERT,可以通过将每个令牌的输出向量馈入预测NER标签的分类层来训练NER模型。
结论
毫无疑问,BERT在使用机器学习进行自然语言处理方面取得了突破。 它平易近人并可以进行快速微调,这一事实很可能会在将来广泛应用。 在此摘要中,我们试图描述本文的主要思想,同时又不淹没过多的技术细节。 对于那些希望深入了解的人,我们强烈建议您阅读全文和其中引用的辅助文章。 另一个有用的参考是BERT源代码和模型,它涵盖了103种语言,并由研究团队慷慨地发布为开源。














 2150
2150











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









