






BERT任务目标概述
1、需要熟悉word2vec,RNN网络模型,了解词向量如何建模
2、重点在于Transformer网络架构,BERT训练方法,实际应用
3、BERT开源项目都是现成的,直接套用
4、提供预训练模型,基本任务都能拿来用。
传统解决方案遇到的问题
1、基本组成依旧是机器翻译模型中常见的Seq2Seq网络
2、Transformer输入输出比较直观
3、传统的RNN网络模型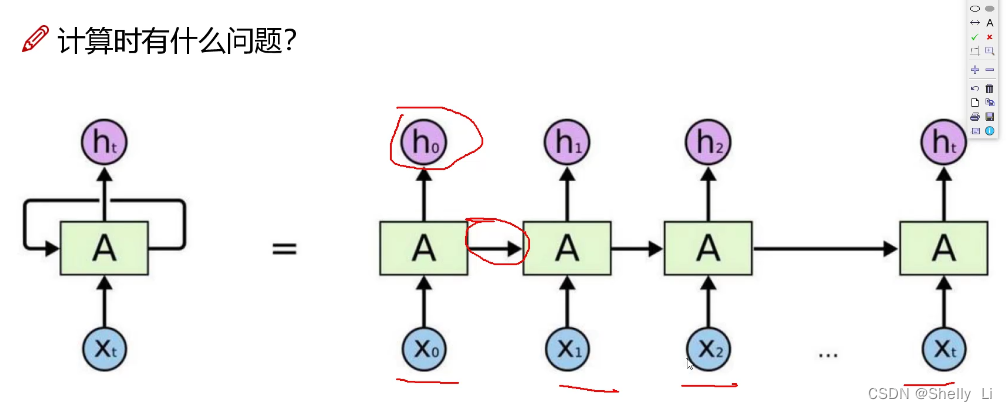 缺点:每一个下一步都会用到前一步中间的状态,不能并行运算
缺点:每一个下一步都会用到前一步中间的状态,不能并行运算
4、Transformer可以解决并行问题 、注意力问题

5、传统的word2vec
预训练好的向量永远不变了,那不同语境相同的词如何表达。例如:干哈呐表示在干嘛或者是叫你出去干点啥
BERT框架使得同一个词在不同语境下的意思不同
6、整体框架
如和编码
输出结果是什么
Attention的目的
怎样组合在一起
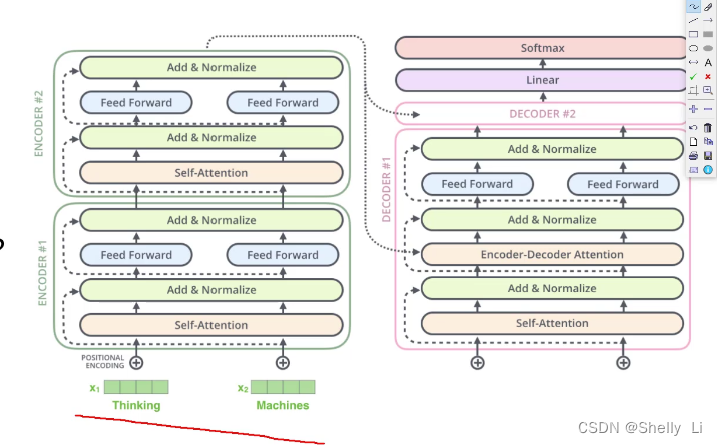
注意力机制问题(Self-Attention)
对于输入的数据,关注点是什么
(不仅仅可以用于文本提取,还可以用于视觉,不过大部分用于NLP)
如何才让计算机关注有价值的信息
根据数据来判断什么比较重要,不同的语句语境有不同的重要行程度

你需要知道这个it指代什么,将当前语境融入到词向量当中

计算方法
每一个词对于上下文每一个词的权重
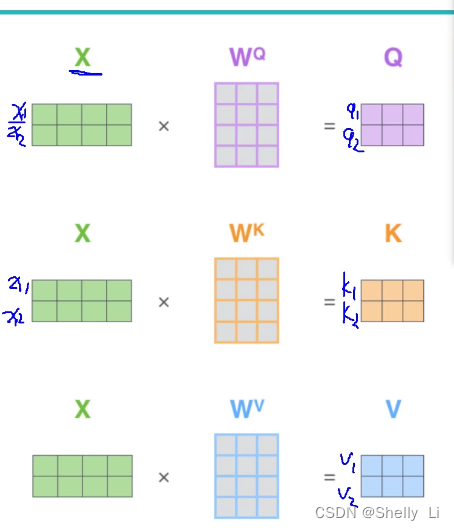
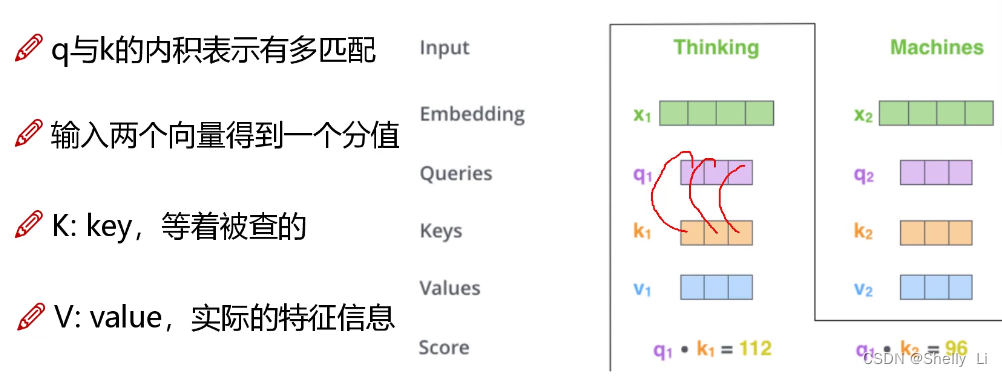
特征分配与softmax机制
得到的内积作为分值然后换算成比例形成权重百分值,其实就是归一化
















 969
969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









