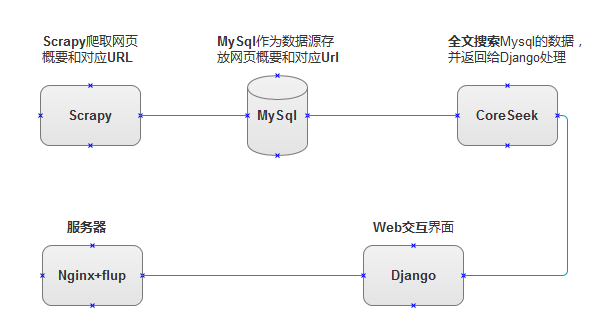
项目架构: 流程分析: Scrapy引擎不断爬取网页的概要信息和对应URLMySql作为数据源,实时存放爬取到的数据CoreSeek全文搜索*MySql的数据,并与Django交互*Django作为交互Web页面Nginx和flup作为服务器








 1092
1092

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
























