






一 继往开来
-
提出Batch Normalization 加速训练(丢弃dropout):将一批数据的feature map转化为满足均值=0,方差=1的分布
-
提出了残差网络块(Residual):人为地让神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系。
在这之前,神经网络都是由卷积层+池化层堆叠而成。而且我们认为这种堆叠深度越深,抽取的图像特征越高级,效果也会最佳。 实际上,随着堆叠深度加深,出现了3种情况: 1. 梯度消失 当每一层的误差梯度小于1时,反向传播时,网络越深,梯度越趋近于0。 2. 梯度爆炸 当每一层的误差梯度大于1时,反向传播时,网络越深,梯度越来越大。 3. 退化问题 随着层数的加深,模型性能不升反退。 通过 Batch Normalization 解决情况1、2,通过 Residual 解决情况3。
接下来浅理解一下 Residual,如下图所示:
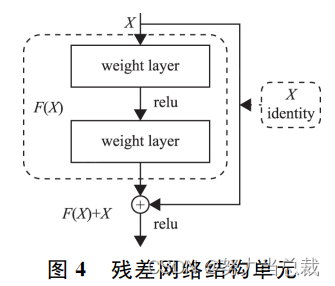
使用了一种shortcut的跳跃连接方式,我的理解就这么浅。
【注】ResNet系列网络是既有深度、又有精度的CNN网络。在实际落地项目中,很多都是基于ResNet作出伟大成就的!在此膜拜!!!
二 一窥究竟
首先请明确,ResNet50网络共有50层(1+9+12+18+9+1 = 50),
如下图所示:
stage1至stage4代表结构块,为了便于绘图,其中 Bottleneck V2 和 Bottlenexk V3 分别代表 stage2 和 stage3 中维度相同的残差块。

如果上图看得云里雾里,那我们在这里再从代码实现的角度理解一下:
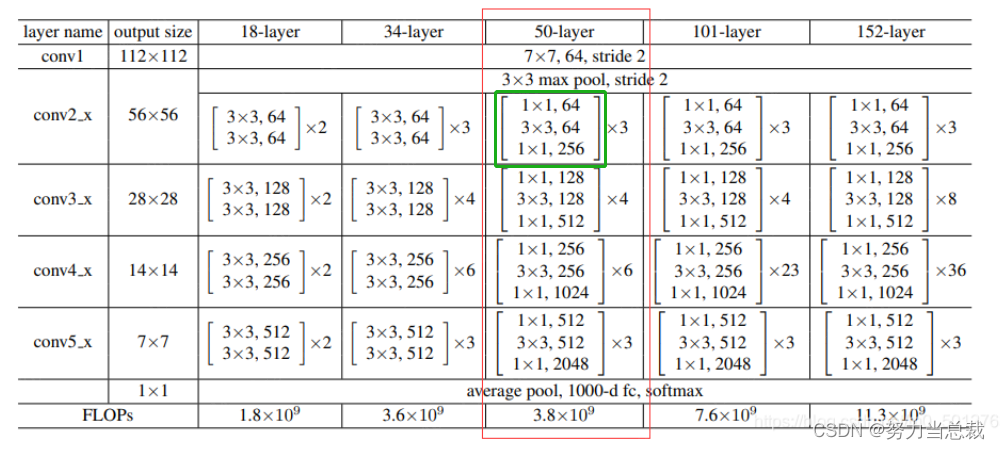
1 输入图像 [224, 224, 3] 代表意思为 [图像长度, 图像宽度, 图像通道数]
2 不管是18层、34层、50层、101层还是152层,有一个公共的stem 层,对输入图像进行卷积运算。
这一层的输出结果是 [112, 112, 64] ,为啥呢?因为当7×7 的卷积核,步长为 2 时,原图像的尺寸由 [224,224] 变为 [112,112],
卷积核的个数是 64 个,所以通道数由 3 变为 64
3 接下来紧跟一个池化层,输出的结果是 [56, 56, 64]
4 以 ResNet50为例,残差网络里有个计算公式 F(x) = F(x) + x,我的理解是:x 的数据结构 = [56, 56, 64] ;
F(x)的数据结构 = 三个卷积运算的结果;
展开细说:看上图中绿色框,第一个卷积层的输入为 [56, 56, 64] ,输出为 [56, 56, 64]
第二个卷积层的输入为 [56, 56, 64] ,输出为 [56, 56, 64]
第三个卷积层的输入为 [56, 56, 64] ,输出为 [56, 56, 256]
所以 F(x)的数据结构 = [56, 56, 256]
那么问题来了,既然 F(x) = F(x) + x ,两个数据结构不一致可以相加吗?不可以!所以要对 x 的数据结构做变换
再来一个卷积运算,输入的是 x 的数据结构 [56, 56, 64] ,输出为 [56, 56, 256]
这样一来,该残差块的 输入数据 和 运算结果 实现了相加,确保了浅层的特征能够持续性的传递到深层。
5 后续网络的无脑堆叠,就比较简单了,我们在代码中理解。
三 养兵千日 用兵一时
1、模型搭建
import torch
import torch.nn as nn
import torchvision
# 因为18/34层的网络结构中的残差块和50/101/152层的有所不同,所以这里我们就专门搭建50层之后的网络。
# 网络名称列表
__all__ = ['ResNet50', 'ResNet101','ResNet152']
# 公用的 stem 层,对输入图像进行的第一次卷积操作。
# 卷积核尺寸: 7×7 ,卷积核个数 64,填充值为 3, 步长为 2
# 最大池化核: 3×3 , 填充值为 1, 步长为 2
def Conv1(in_planes, places, stride=2):
# [224, 224, 3]
return nn.Sequential(
nn.Conv2d(in_channels=in_planes,out_channels=places,kernel_size=7,stride=stride,padding=3, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
# [112, 112, 64]
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
# [56, 56, 64]
)
# 残差块
# expansion = 4 为啥? 因为我们在上面的图中可以发现统一的规律:经过三层的卷积运算,输出结果的通道数是输入通道数的4倍。
# downsampling 用来判断是否需要进行数据结构转换,就是上面说的 F(x) = F(x) + x ,两个数据结构不一致不能相加。
class Bottleneck(nn.Module):
def __init__(self,in_places, places, stride=1,downsampling=False, expansion = 4):
super(Bottleneck,self).__init__()
self.expansion = expansion
self.downsampling = downsampling
self.bottleneck = nn.Sequential(
# 第一个卷积层:卷积核尺寸: 1×1 ,填充值为 0, 步长为 1
nn.Conv2d(in_channels=in_places,out_channels=places,kernel_size=1,stride=1, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
# 第二个卷积层:卷积核尺寸: 3×3 ,填充值为 1, 步长为 1
nn.Conv2d(in_channels=places, out_channels=places, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(places),
nn.ReLU(inplace=True),
# 第三个卷积层:卷积核尺寸: 1×1 ,填充值为 0, 步长为 1
nn.Conv2d(in_channels=places, out_channels=places*self.expansion, kernel_size=1, stride=1, bias=False),
nn.BatchNorm2d(places*self.expansion),
)
# 判断 x 的数据格式(维度)是否和 F(x)的一样,如果不一样,则进行一次卷积运算,实现升维操作。
# 卷积核尺寸: 1×1 ,个数为原始特征图通道数的4倍, 填充值为 0, 步长为 1
if self.downsampling:
self.downsample = nn.Sequential(
nn.Conv2d(in_channels=in_places, out_channels=places*self.expansion, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(places*self.expansion)
)
self.relu = nn.ReLU(inplace=True)
# 建立网络层运算结果的前向传递关系
def forward(self, x):
# 将输入赋值给 residual
residual = x
# 基础模块的运算结果
out = self.bottleneck(x)
# 如果x 的数据格式(维度)是和 F(x)不一样,则进行一次卷积运算,并将计算结果更新至residual
if self.downsampling:
residual = self.downsample(x)
# 最终结果的求和(汇总)
# 一部分是经过三层卷积运算的结果,另一部分是输入特征/输入特征的升维结果
# out = out + redidual
out += residual
out = self.relu(out)
return out
# 构建一个ResNet类,内部调用上面的 stem 层和类 Bottleneck
# 参数 blocks 列表为50/101/152层中各 stage 中残差块的个数
class ResNet(nn.Module):
def __init__(self,blocks, num_classes=1000, expansion = 4):
super(ResNet,self).__init__()
self.expansion = expansion
# 调用 stem 层
self.conv1 = Conv1(in_planes = 3, places= 64)
# stage 1-4
self.layer1 = self.make_layer(in_places = 64, places= 64, block=blocks[0], stride=1)
self.layer2 = self.make_layer(in_places = 256,places=128, block=blocks[1], stride=2)
self.layer3 = self.make_layer(in_places=512,places=256, block=blocks[2], stride=2)
self.layer4 = self.make_layer(in_places=1024,places=512, block=blocks[3], stride=2)
# 均值池化
self.avgpool = nn.AvgPool2d(7, stride=1)
# 全连接层
self.fc = nn.Linear(2048,num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
# 每一个stage中的第 1个残差块需要downsampling =True,后面都不需要,因为后面的输入数据结构和输出是一致的
# 以stage1为例,共有3个残差块,从头至尾的输入输出依次是 [56,56,64]→[56,56,64]→[56,56,256](既是第一个残差块的输出,也是第二个残差块的输入)
# →[56,56,64]→[56,56,64]→[56,56,256]
# →[56,56,64]→[56,56,64]→[56,56,256]
# 会发现残差块的连接处输入通道变成了输出通道的4倍,所以就有 places*self.expansion
def make_layer(self, in_places, places, block, stride):
layers = []
layers.append(Bottleneck(in_places, places,stride, downsampling =True))
for i in range(1, block):
layers.append(Bottleneck(places*self.expansion, places))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def ResNet50():
return ResNet([3, 4, 6, 3])
def ResNet101():
return ResNet([3, 4, 23, 3])
def ResNet152():
return ResNet([3, 8, 36, 3])
if __name__=='__main__':
#model = torchvision.models.resnet50()
model = ResNet50()
print(model)
input = torch.randn(1, 3, 224, 224)
out = model(input)
print(out.shape)
【注】其他部分代码参考其他模型,包括 “数据集加载”、“模型训练”……
pytorch逐行搭建CNN系列(一)AlexNet















 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











