






提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
前言
在文字生成领域,GPT-2无疑是一个分水岭。2018年GPT-2的推出,标志着能够生成连贯、语法正确的文本段落的新时代。虽然性能一般,但它为后续的模型发展奠定了基础。
四年后,GPT-4已经能够执行串联思维这种复杂任务。
而今天,Sora已经也意味着这样的时刻。
一、背景
Sora有两个超能力:
1、精准地理解人类指令;
2、执行复杂的人类指令。
在视觉领域的分水岭应该是图像检测人员将Transformer架构与视觉组件相结合,提出了视觉Transformer(ViT)和Swin Transformer。与此同时,扩散模型在图像与视频生成领域也取得了突破。
二、原理
1.核心
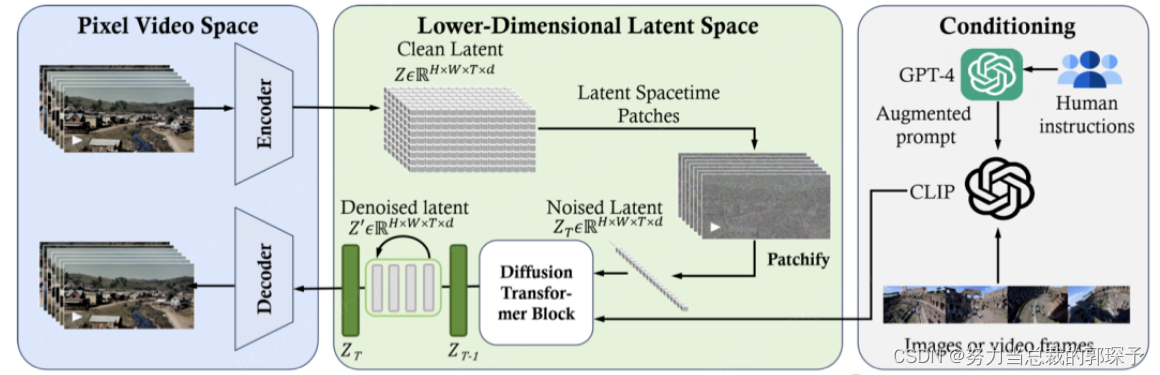
Sora是Diffusion Transformer,能够精准处理不同维度的数据。
- 时空压缩器会把原始视频转映射到潜空间中。
- ViT 模型会对已经被分词的潜表征进行处理,并输出去除噪声后的潜表征。
- 类CLIP模型类根据用户的指令(已经通过大语言模型进行了增强)和潜视觉提示,引导扩散模型生成具有特定风格或主题的视频。在经过多次去噪处理之后,会得到生成视频的潜表征,然后通过相应的解码器映射回像素空间。
2.原理
-
数据预处理
··· 可变的分辨率和高宽比

··· 统一的视觉表征Sora首先将视频压缩到「低维潜空间」,然后再将表征分解成「时空patches」 其目的是为了有效处理各种各样的视觉输入,比如不同长度、清晰度和画面比例的图片和视频··· 视频压缩网络(视觉编码器)
其目的是为了降低输入数据的维度,并输出经过时空压缩的潜表征。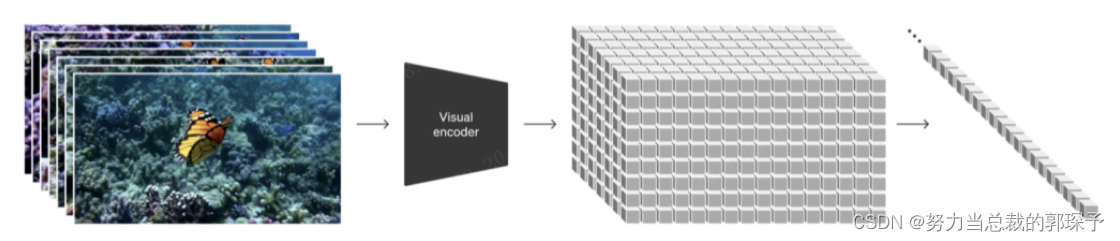
但是在此之前,必须要进行图像的大小调整和裁剪,因为压缩技术(VAE)很难将不同尺寸的视觉数据映射到一个统一且大小固定的潜空间中。有以下两种方案:-
空间patches压缩
将视频帧转换成固定大小的patches,然后再将其编码到潜空间中。与ViT和MAE模型采用的方法相似。

-
总结
未完待更
















 2111
2111











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











