







前言
在当今多模态大模型的研究与应用中,封神榜大模型团队的最新力作Ziya-Visual-Lyrics在多个方面实现了显著的技术突破。该模型综合了细粒度的视觉处理和先进的语言理解能力,为多模态人工智能领域带来了革命性的影响。
伴随着GPT4V、Gemini等模型的崛起,多模态大模型已经超越了传统的大语言模型范畴,涵盖图像、音频、视频等多种模态。这些模型不仅仅是技术上的飞跃,更开启了多模态大模型应用的新篇章。Ziya-Visual-Lyrics模型就是在这一背景下诞生的,它的出现预示着多模态技术的新高度。
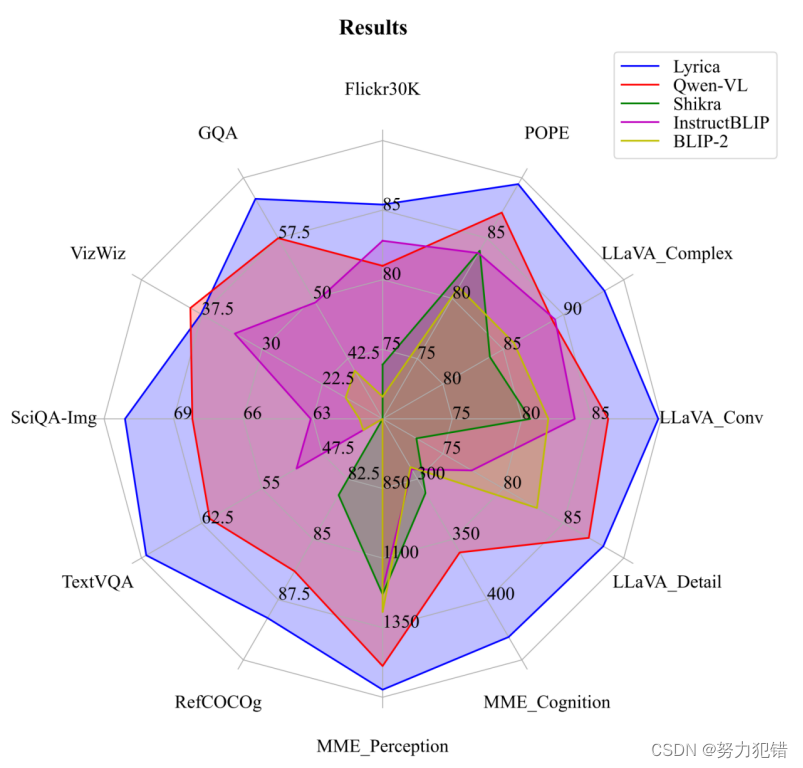
技术亮点
Ziya-Visual-Lyrics引入了视觉细化器,并采用了细粒度的两阶段视觉语言训练框架Lyrics,有效地促进了模型在处理视觉对象时的语义感知能力。该模型的视觉细化器包含图像标记、目标检测和语义分割模块,显著提升了模型对图像细节的理解能力。此外,Ziya-Visual-Lyrics还采用了多尺度Querying Transformer (MQ-Former) 结构来对齐视觉和语言特征,进一步提高了模型的处理效率和准确性。
-
Huggingface模型下载:https://huggingface.co/IDEA-CCNL/Ziya-Visual-Lyrics-14B
-
AI快站模型免费加速下载:https://aifasthub.com/models/IDEA-CCNL/Ziya-Visual-Lyrics-14B
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









