






前言
近日Gradient公司在Crusoe Energy公司的算力支持下,开发了一款基于Llama-3的大型语言模型。这款新模型在原Llama-3 8B的基础上,将上下文长度从8000 token大幅扩展到超过104万token。
这一创新性突破,展现了当前SOTA大语言模型在长上下文学习方面的能力。Gradient团队通过合理调整RoPE,以及采用渐进式训练的方法,仅使用了原Llama-3不到0.01%的训练数据,就实现了这一飞跃。
-
Huggingface模型下载:https://huggingface.co/gradientai/Llama-3-8B-Instruct-Gradient-1048k
-
AI快站模型免费加速下载:https://aifasthub.com/models/gradientai
技术亮点
Gradient发布的这款超长上下文Llama-3模型,主要有以下几个技术特点:
-
大幅扩展的上下文长度
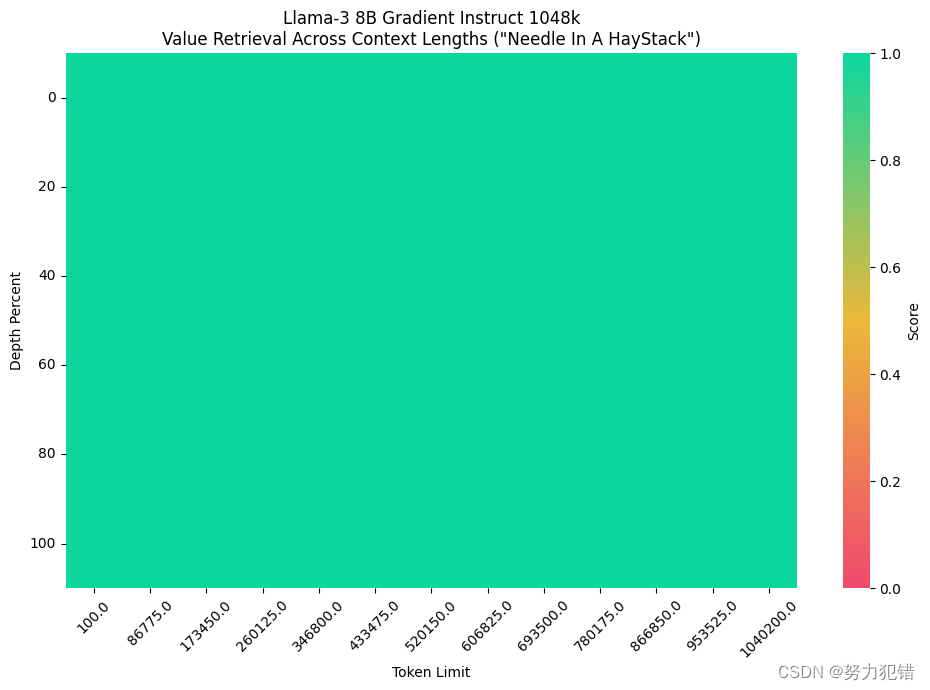
相比Llama-3 8B仅支持8000 token的上下文长度,新模型可处理超过104万token的长文本。这不仅可以更好地支持复杂的多轮对话,也为处理长篇文章、报告等提供了基础。
-
高效的分阶段渐进式训练
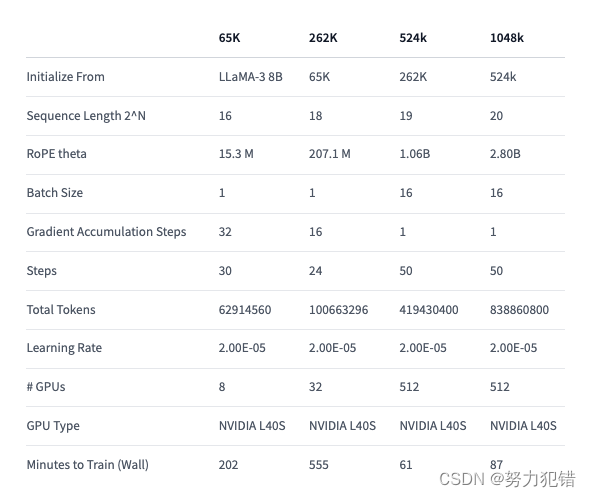
Gradient采用了类似"Large World Model"的分阶段渐进式训练方法。他们先在较短的上下文上进行预训练,然后逐步增加训练数据的上下文长度,直至达到104万token。这种策略可以有效提升模型在长上下文上的学习效果。
-
优化的RoPE
RoPE是Llama-3等模型用于编码位置信息的关键组件。Gradient团队采用了基于NTK(Neural Tangent Kernel)的插值方法,合理初始化RoPE theta参数,并进行后续经验性优化,进一步增强了模型在长上下文下的性能。
应用前景
凭借出色的性能和大幅扩展的上下文长度,Gradient发布的这款Llama-3超长上下文模型,在以下场景中具有广阔的应用前景:
-
对话式AI助手:100万token的上下文长度,可以帮助构建功能强大、记忆力持久的对话式AI助手。
-
智能问答系统:出色的常识理解和推理能力,可以提供更准确全面的信息回答。
-
编程助手:优秀的代码理解和生成能力,可以为程序员提供智能化的编码辅助。
-
内容生成:强大的语言理解和生成能力,可以辅助撰写报告、文章、剧本等各类内容创作。
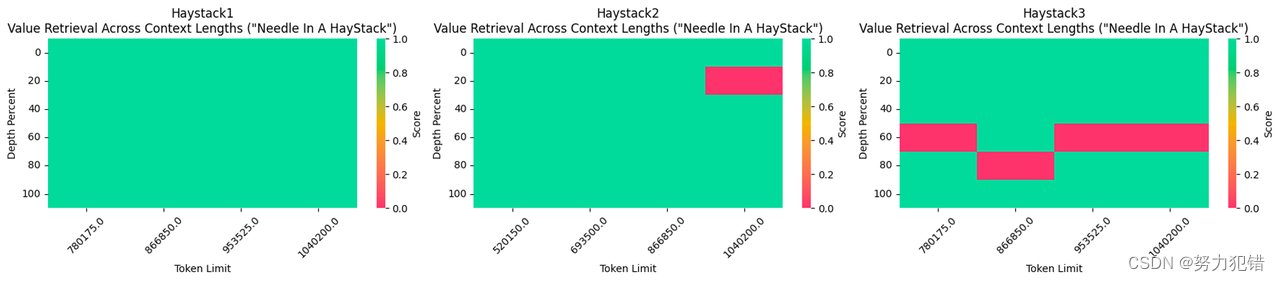
总的来说,Gradient发布的这款Llama-3超长上下文模型,必将为对话式AI、智能问答、编程辅助等领域带来新的发展机遇,为人工智能应用注入新的动力。
模型下载
Huggingface模型下载
https://huggingface.co/gradientai/Llama-3-8B-Instruct-Gradient-1048k
AI快站模型免费加速下载
https://aifasthub.com/models/gradientai














 712
712











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









