






一、介绍Yolo4
YOLO (You Only Look Once)是一种实时目标检测算法,YOLO v4是其第四个版本。它使用单个神经网络来同时预测多个物体的边界框和类别。YOLO v4通过引入一些新的技术和优化来提高检测性能和速度,如使用更大的模型、改进的骨干网络、更高效的数据增强和训练技巧等。
二、使用环境
·NVIDIA GeForce RTX 3050 Laptop GPU
·torch==1.2.0
·Python3.8
三、配置运行环境及安装相关依赖
该实验需要用到以下几种包:
scipy1.2.1
numpy1.17.0
matplotlib3.1.2
opencv_python4.1.2.30
torch1.2.0
torchvision0.4.0
tqdm4.60.0
Pillow8.2.0
h5py==2.10.0
在安装包的时候使用镜像源会安装较快,给出几种常用镜像源:
豆瓣(douban)
http://pypi.douban.com/simple/
清华大学
https://pypi.tuna.tsinghua.edu.cn/simple/
四、数据准备
(一)下载数据集
VOC数据集下载地址如下,里面已经包括了训练集、测试集、验证集(与测试集一样),无需再次划分:
链接: https://pan.baidu.com/s/19Mw2u_df_nBzsC2lg20fQA
提取码: j5ge
(二)下载权重
训练所需的yolo4_weights.pth可在百度网盘中下载。
链接: https://pan.baidu.com/s/1oXz13QwLx1lnXct538qL2Q
提取码: 16qc
yolo4_weights.pth是coco数据集的权重。
yolo4_voc_weights.pth是voc数据集的权重。
五、数据准备
我们需要准备所需的图片数据,并将这些图片放入原项目的VOCdevkit文件夹内的VOC2007文件夹下的JPEGImages目录中。接下来,对于所添加的图片数据,我们需要进行标注工作。在这个过程中,我采用了labelImg_exe这一工具来辅助完成标注任务。
完成图片的标注后,需要将所有生成的标签文件妥善存放,具体操作为:将这些标签文件放置在VOCdevkit文件夹下的VOC2007文件夹中的Annotation目录内。
六、训练过程
训练的过程主要包括以下步骤:
(一)训练VOC07+12数据集
-
数据集准备
首先,使用VOC格式进行训练需要下载VOC07+12数据集,并将其解压至项目的根目录。
-
数据集处理
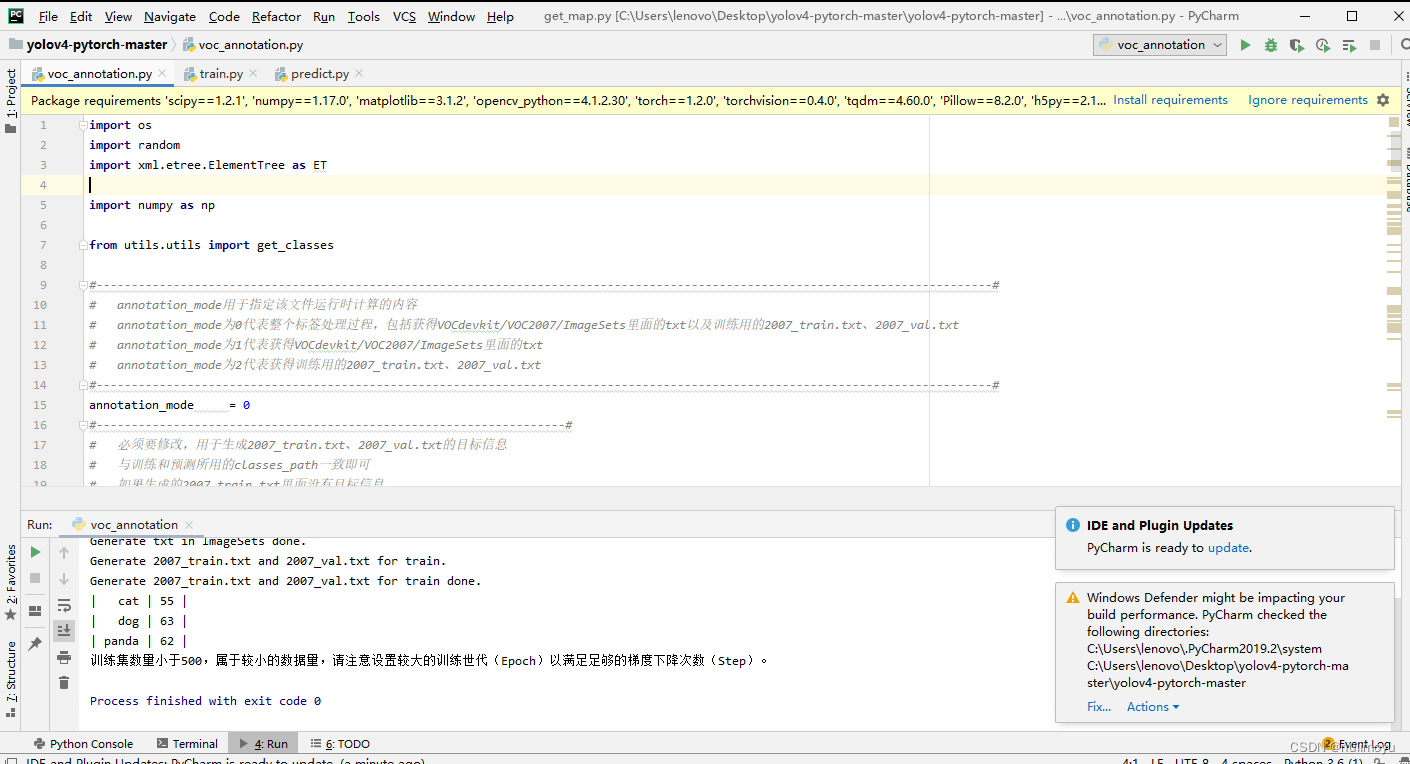
修改
voc_annotation.py中的annotation_mode为2,然后运行此脚本,以生成根目录下的2007_train.txt和2007_val.txt文件,这两个文件分别用于指定训练和验证的数据集。 -
开始网络训练
train.py脚本的默认参数已针对VOC数据集进行了配置,因此只需直接运行此脚本即可开始训练过程。 -
训练结果预测
在训练完成后,使用
yolo.py和predict.py进行结果预测。在yolo.py中,需要修改model_path和classes_path。model_path指向训练好的模型权重文件(通常位于logs文件夹内),而classes_path指向包含检测类别名称的文本文件。完成修改后,运行predict.py并输入待检测的图片路径即可进行预测。
(二)训练自己的数据集
-
数据集准备
若要使用自己的数据集进行训练,首先需要按照VOC格式制作数据集。这包括将图片文件放入
VOCdevkit/VOC2007/JPEGImages文件夹,以及将对应的标签文件放入VOCdevkit/VOC2007/Annotation文件夹。 -
数据集的处理
准备好数据集后,再次利用
voc_annotation.py脚本生成训练所需的2007_train.txt和2007_val.txt文件。此时,可能需要修改voc_annotation.py中的某些参数,尤其是classes_path,它应指向包含自己数据集类别的文本文件(例如model_data/cls_classes.txt)。在这个文件中,列出所有需要区分的类别,每个类别占一行。要修改
voc_annotation.py中的classes_path以使其对应cls_classes.txt文件,请按照以下步骤操作:打开voc_annotation.py文件。查找classes_path变量,它通常位于文件的开始部分,用于指定类别文件的路径。将classes_path的值更改为cls_classes.txt文件的完整路径或相对路径,确保指向正确的文件。保存并关闭voc_annotation.py文件。运行voc_annotation.py脚本,它将使用指定的classes_path生成训练和验证数据集的文本文件。
3.开始网络训练
训练过程涉及多个参数,这些参数均在train.py脚本中设置。请仔细阅读脚本中的注释,以了解每个参数的作用。其中,classes_path是一个关键参数,它用于指向包含检测类别名称的文本文件。当使用自己的数据集进行训练时,务必修改train.py中的classes_path,确保它指向与voc_annotation.py中相同的cls_classes.txt文件。这是确保训练过程中正确识别类别的重要步骤。修改完classes_path后,运行train.py脚本开始训练过程。在训练过程中,模型会经过多个epoch的迭代,训练后的权重文件将保存在logs文件夹中。
4.训练结果预测
为了进行训练结果的预测,你需要使用yolo.py和predict.py这两个文件。在yolo.py中,你需要修改model_path和classes_path两个参数。model_path应该指向logs文件夹中保存的训练好的权重文件。这是模型进行预测时所需的关键组件。classes_path则应该指向与训练和voc_annotation.py中相同的cls_classes.txt文件,以确保预测时能够正确识别类别。完成这些修改后,运行predict.py脚本进行预测。在脚本运行时,你需要输入待检测图片的路径,然后脚本将使用训练好的模型对图片进行预测并输出结果。
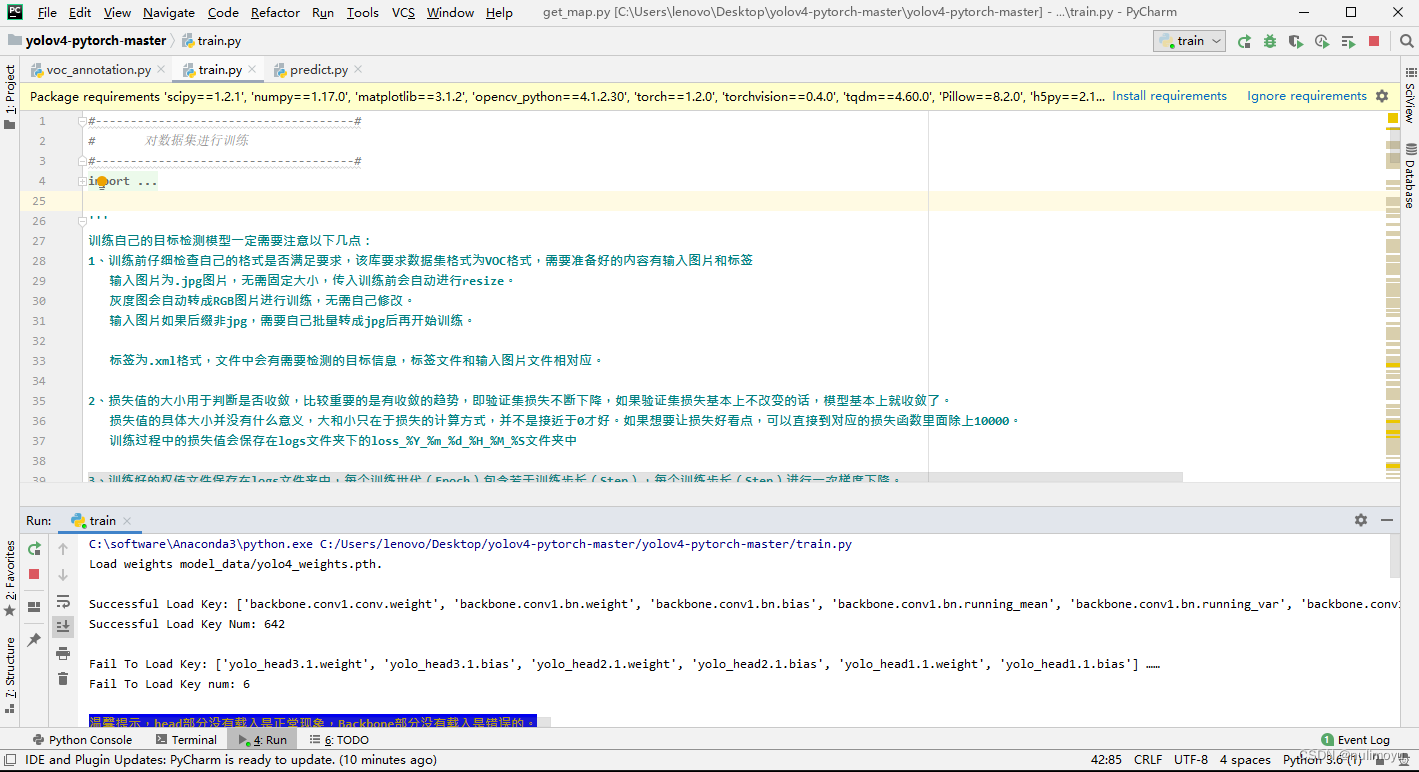 七、训练结果及预测
七、训练结果及预测
在运行predict.py文件后输入自己要预测图片的路径地址
如:
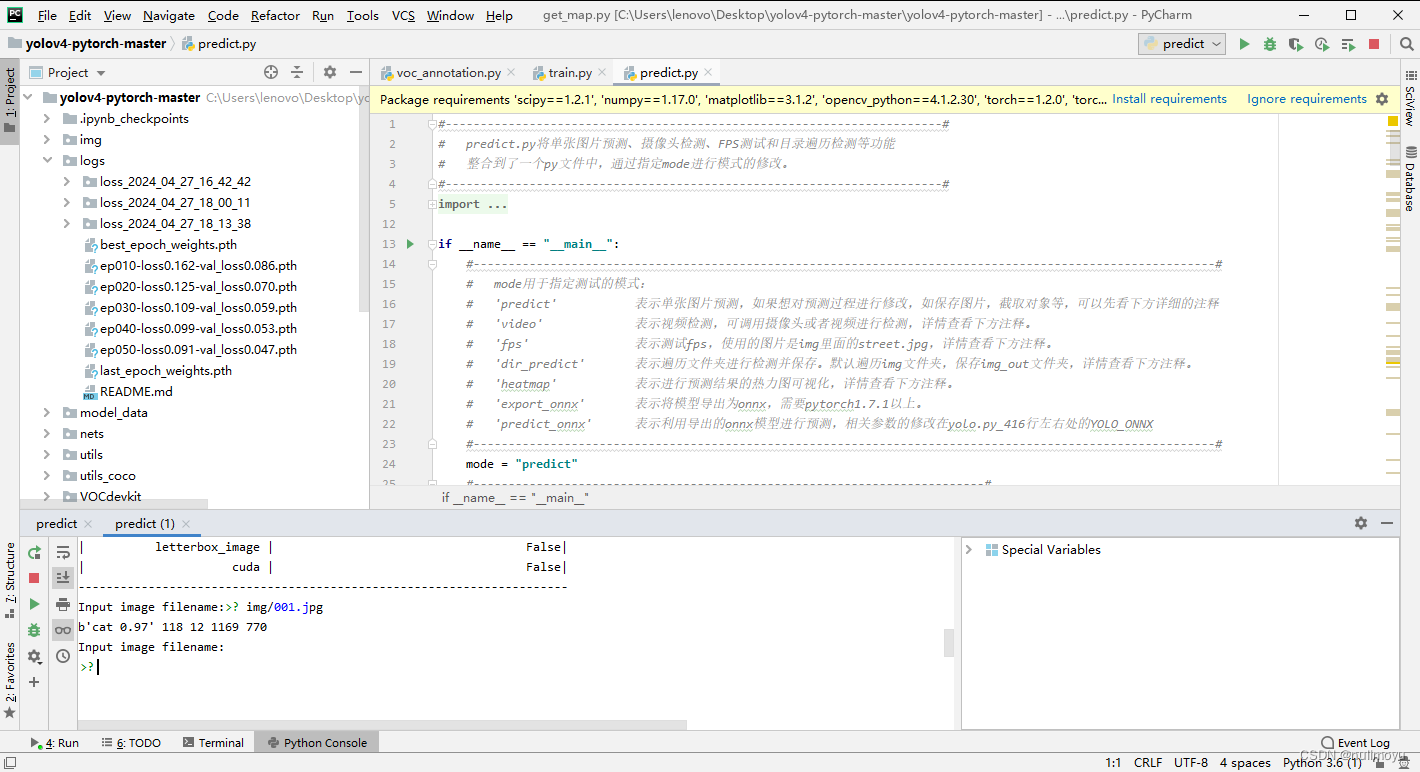
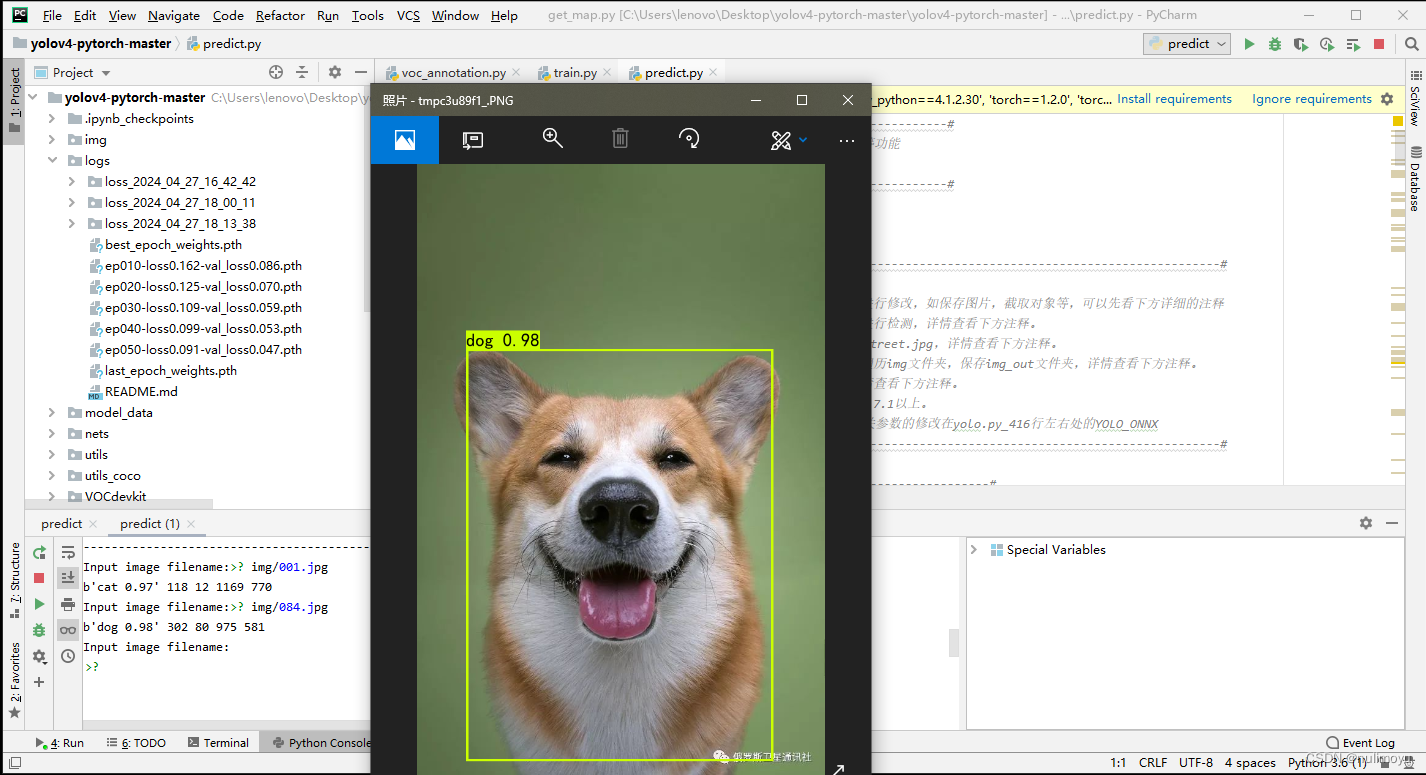
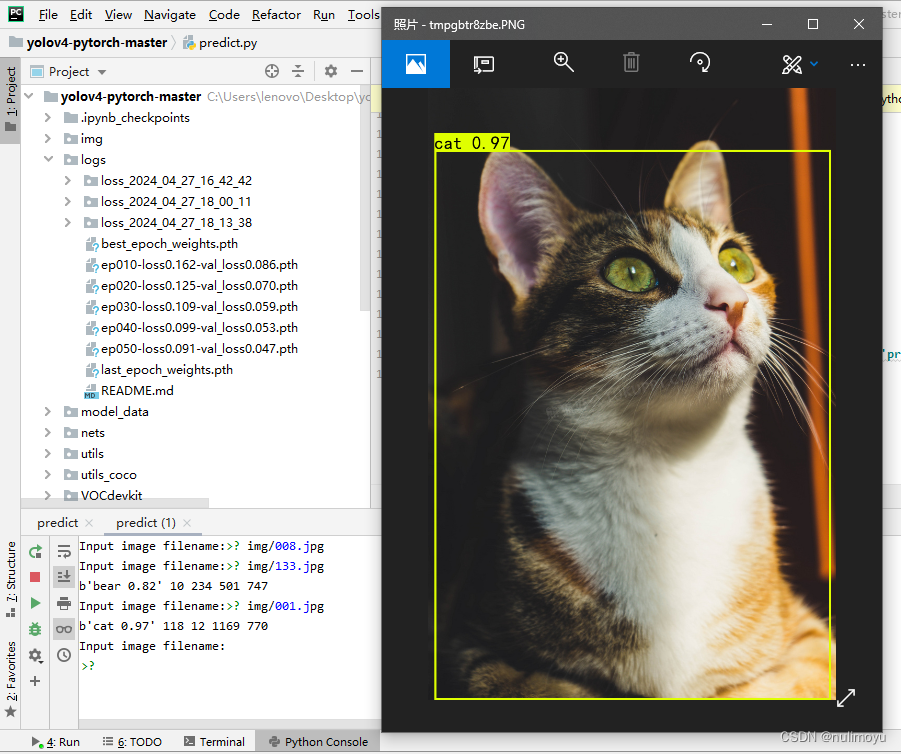
我设置了动物类的三个种类:cat、dog、panda其中cat和dog准确率较为高
以下是我的训练结果:
epoch_loss 损失曲线图:
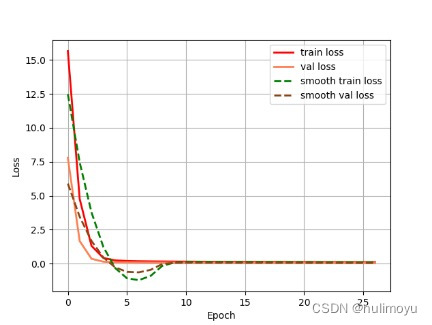
红色实线表示训练损失(train loss)。
橙色实线表示验证损失(val loss)。
绿色虚线表示平滑后的训练损失(smooth train loss)。
橙色虚线表示平滑后的验证损失(smooth val loss)。
横轴标记为“Epoch”,范围从0到25。
纵轴标记为“Loss”,范围从0.0到15.0左右。
epoch_map 平均精度曲线图:
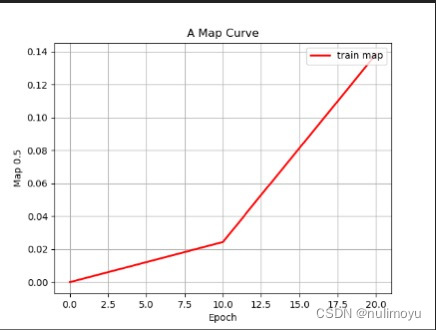
红色曲线代表“train_map”随“Epoch”变化的趋势。
横轴标记为“Epoch”,范围从0延伸至20.0。
纵轴标记为“mAP”,范围从0到0.14。
八、实验反思
在训练数据集过程,起初我的样本数量过小造成了测试时准确率不高,后来增加样本数量后又出现了训练时过于漫长,我设定的训练循环是三百次,七个小时仅训练了80次,后来在训练第八十次的 时候我暂停训练进行测试时,发现得到的准确率已经大多在82%-98%之间,如果训练循环次数足够多,数据集样本足够大则准确率会更高,但建议在时间充足的情况下进行训练。















 1188
1188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









