




【更新日志】
Update: 2022年3月14日,增加D4RL安装过程报错问题。.
强化学习快速发展的主要原因在于有一个良好的模拟环境,最终得到一个最优的policy, 然而现实问题就是在实际落地应用中没有有效的环境,为了解决实验环境问题,本文主要对现有的离线强化学习数据集D4RL进行安装,并就出现的相关问题进行汇总。
文章目录
一、关于D4RL Benchmarks数据集
1.1 为什么选择 D4RL?
(1) D4RL 收集了大型数据集,包括交互式环境中智能体的记录(即自动驾驶Carla、AntMaze、Mujoco等),且有简单和复杂分类,种类非常丰富,例如:
- 通过人工演示或硬编码控制器生成的数据。
- 具有不同策略的异构混合的数据
- 数据观察智能体在同一环境中完成各种目标。

(2) D4RL提供了非常简单的API接口,方便于学习者直接去获取数据集完成智能体的训练。
import d4rl # Import required to register environments
env = gym.make('maze2d-umaze-v1')
dataset = env.get_dataset()
(3) D4RL定义了标准的衡量指标
n
o
r
m
a
l
i
z
e
d
s
c
o
r
e
=
100
%
∗
s
c
o
r
e
−
r
a
n
d
o
m
_
s
c
o
r
e
e
x
p
o
r
t
_
s
c
o
r
e
−
r
a
n
d
o
m
_
s
c
o
r
e
normalized score =100\%* \frac{score- random\_score}{export\_score-random\_score}
normalizedscore=100%∗export_score−random_scorescore−random_score
(4) D4RL提供了丰富的baseline基准,包括了常见的Offline算法,包括BCQ、BEAR、BRAC等等

1.2 D4RL数据集制作影响因素
D4RL数据集目前来说是离线强化学习涵盖数据集非常丰富的一个数据集,数据质量非常高。其中最主要的是数据的采集综合了6类因素
- Narrow and biased data distributions
- Undirected and multitask data
- Sparse rewards
- Suboptimal data.
- Non-representable behavior policies, non-Markovian behavior policies, and partial observ-
ability. - Realistic domains
二、D4RL安装与使用
2.1 官方安装指导(有坑)
D4RL 的安装相对来说比较容易,但其中也有很多的坑
git clone https://github.com/rail-berkeley/d4rl.git
cd d4rl
pip install -e .
另外一种简单的安装方法
pip install git+https://github.com/rail-berkeley/d4rl@master#egg=d4rl
其中会有很多坑,导致安装失败。
下面我们根据初始化安装文件setup.py分析安装
from distutils.core import setup
from platform import platform
from setuptools import find_packages
setup(
name='d4rl',
version='1.1',
install_requires=['gym',
'numpy',
'mujoco_py',
'pybullet',
'h5py',
'termcolor', # adept_envs dependency
'click', # adept_envs dependency
'dm_control' if 'macOS' in platform() else
'dm_control @ git+git://github.com/deepmind/dm_control@master#egg=dm_control',
'mjrl @ git+git://github.com/aravindr93/mjrl@master#egg=mjrl'],
packages=find_packages(),
package_data={'d4rl': ['locomotion/assets/*',
'hand_manipulation_suite/assets/*',
'hand_manipulation_suite/Adroit/*',
'hand_manipulation_suite/Adroit/gallery/*',
'hand_manipulation_suite/Adroit/resources/*',
'hand_manipulation_suite/Adroit/resources/meshes/*',
'hand_manipulation_suite/Adroit/resources/textures/*',
]},
include_package_data=True,
)
2.2 有效安装过程(避坑)
上述过程安装后我们会发现遇到很多问题,下面我就自己的安装过程以及遇到的问题一一列举
安装环境: Ubuntu18.04, anaconda3
第一步:安装mujoco210(针对没有安装mujoco)
# 下载地址 https://github.com/deepmind/mujoco/releases/tag/2.1.0
cd ~/Downloads/
wget https://github.com/deepmind/mujoco/releases/download/2.1.0/mujoco210-linux-x86_64.tar.gz
mv mujoco210-linux-x86_64.tar.gz mujoco210
tar -zxvf mujoco210-linux-x86_64.tar.gz
mkdir ~/mujoco
cp -r mujoco210 ~/mujoco
# 添加环境变量
sudo gedit ~/.bashrc
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HOME/.mujoco/mujoco210/bin
export MUJOCO_KEY_PATH=~/.mujoco${MUJOCO_KEY_PATH}
source ~/.bashrc
# 测试
cd ~/.mujoco/mujoco210/bin/
./simulate ../model/humanoid.xml

坑1:can’t find /.mujoco/lib/libmujoco.so.2.1.1(可能安装mujoco200的伙伴会遇到)
解决办法:
(1)下载mujoco211安装包,解压
(2)在mujoco210/lib下找到libmujoco.so.2.1.1,并复制在~/.mujoco/bin在~/.bashrc下
(3)添加环境变量并source
export MJLIB_PATH=~/.mujoco/lib/libmujoco.so.2.1.1
source ~/.bashrc
第二步:安装mujoco_py
# 本步跳过conda环境创建,直接进入虚拟环境(conda create -n d4rl python=3.7)
conda create -n d4rl python=3.7
conda activate d4rl
pip install mujoco_py
python
Python 3.7.11 (default, Jul 27 2021, 14:32:16)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import mujoco_py
>>>
# 备:没有报错表示安装成功
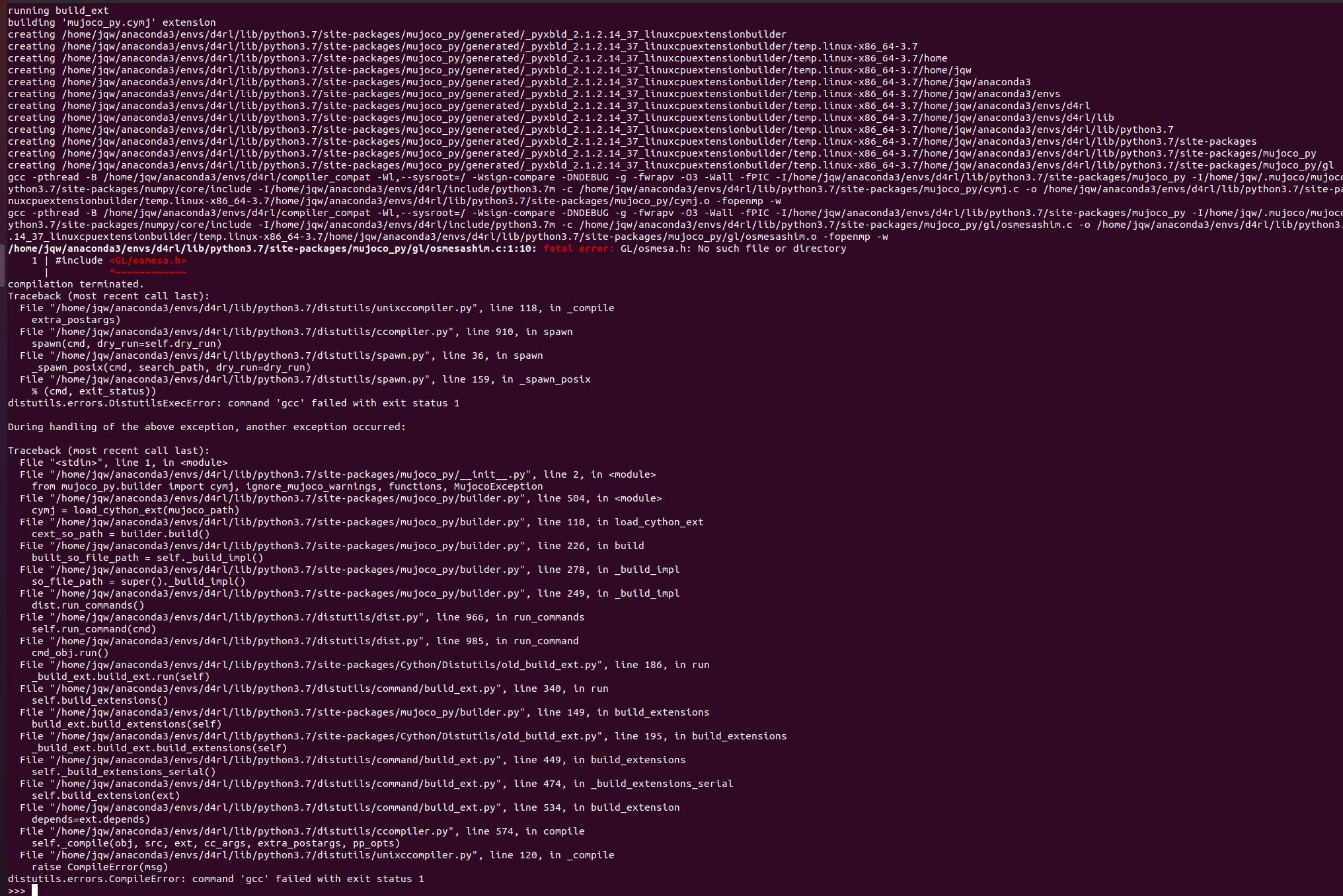
坑2: 如果是fatal error: GL/osmesa.h: No such file or directory,那就安装libosmesa6-dev
Python 3.7.11 (default, Jul 27 2021, 14:32:16)
[GCC 7.5.0] :: Anaconda, Inc. on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import mujoco_py
running build_ext
building 'mujoco_py.cymj' extension
gcc -pthread -B /home/jqw/anaconda3/envs/d4rl/compiler_compat -Wl,--sysroot=/ -Wsign-compare -DNDEBUG -g -fwrapv -O3 -Wall -fPIC -I/home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/mujoco_py -I/home/jqw/.mujoco/mujoco210/include -I/home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/numpy/core/include -I/home/jqw/anaconda3/envs/d4rl/include/python3.7m -c /home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/mujoco_py/cymj.c -o /home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/mujoco_py/generated/_pyxbld_2.1.2.14_37_linuxcpuextensionbuilder/temp.linux-x86_64-3.7/home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/mujoco_py/cymj.o -fopenmp -w
gcc -pthread -B /home/jqw/anaconda3/envs/d4rl/compiler_compat -Wl,--sysroot=/ -Wsign-compare -DNDEBUG -g -fwrapv -O3 -Wall -fPIC -I/home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/mujoco_py -I/home/jqw/.mujoco/mujoco210/include -I/home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/numpy/core/include -I/home/jqw/anaconda3/envs/d4rl/include/python3.7m -c /home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/mujoco_py/gl/osmesashim.c -o /home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/mujoco_py/generated/_pyxbld_2.1.2.14_37_linuxcpuextensionbuilder/temp.linux-x86_64-3.7/home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/mujoco_py/gl/osmesashim.o -fopenmp -w
/home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/mujoco_py/gl/osmesashim.c:1:10: fatal error: GL/osmesa.h: No such file or directory
1 | #include <GL/osmesa.h>
| ^~~~~~~~~~~~~
compilation terminated.
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/mujoco_py/__init__.py", line 2, in <module>
from mujoco_py.builder import cymj, ignore_mujoco_warnings, functions, MujocoException
File "/home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/mujoco_py/builder.py", line 504, in <module>
cymj = load_cython_ext(mujoco_path)
File "/home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/mujoco_py/builder.py", line 110, in load_cython_ext
cext_so_path = builder.build()
File "/home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/mujoco_py/builder.py", line 226, in build
built_so_file_path = self._build_impl()
File "/home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/mujoco_py/builder.py", line 278, in _build_impl
so_file_path = super()._build_impl()
File "/home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/mujoco_py/builder.py", line 249, in _build_impl
dist.run_commands()
File "/home/jqw/anaconda3/envs/d4rl/lib/python3.7/distutils/dist.py", line 966, in run_commands
self.run_command(cmd)
File "/home/jqw/anaconda3/envs/d4rl/lib/python3.7/distutils/dist.py", line 985, in run_command
cmd_obj.run()
File "/home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/Cython/Distutils/old_build_ext.py", line 186, in run
_build_ext.build_ext.run(self)
File "/home/jqw/anaconda3/envs/d4rl/lib/python3.7/distutils/command/build_ext.py", line 340, in run
self.build_extensions()
File "/home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/mujoco_py/builder.py", line 149, in build_extensions
build_ext.build_extensions(self)
File "/home/jqw/anaconda3/envs/d4rl/lib/python3.7/site-packages/Cython/Distutils/old_build_ext.py", line 195, in build_extensions
_build_ext.build_ext.build_extensions(self)
File "/home/jqw/anaconda3/envs/d4rl/lib/python3.7/distutils/command/build_ext.py", line 449, in build_extensions
self._build_extensions_serial()
File "/home/jqw/anaconda3/envs/d4rl/lib/python3.7/distutils/command/build_ext.py", line 474, in _build_extensions_serial
self.build_extension(ext)
File "/home/jqw/anaconda3/envs/d4rl/lib/python3.7/distutils/command/build_ext.py", line 534, in build_extension
depends=ext.depends)
File "/home/jqw/anaconda3/envs/d4rl/lib/python3.7/distutils/ccompiler.py", line 574, in compile
self._compile(obj, src, ext, cc_args, extra_postargs, pp_opts)
File "/home/jqw/anaconda3/envs/d4rl/lib/python3.7/distutils/unixccompiler.py", line 120, in _compile
raise CompileError(msg)
distutils.errors.CompileError: command 'gcc' failed with exit status 1
解决办法:
sudo apt install libosmesa6-dev
# 补充命令: sudo apt-get install libgl1-mesa-glx libosmesa6
坑3: 如果是fatal error: GL/glew.h: No such file or directory,那么就安装Glew库
解决办法
sudo apt-get install libglew-dev glew-utils
坑4: 如果是FileNotFoundError: [Errno 2] No such file or directory: ‘patchelf’: ‘patchelf’, 那就安装patchelf
解决办法:
sudo apt-get -y install patchelf
安装成功是这样的效果

第三步:安装dm_control
pip install dm_control
第四步: 安装d4rl
克隆D4RL仓库
git clone https://github.com/rail-berkeley/d4rl.git
找到到d4rl目录下的setup.py文件,注释mujoco_py, dm_control
install_requires=['gym',
'numpy',
# 'mujoco_py',
'pybullet',
'h5py',
'termcolor', # adept_envs dependency
'click', # adept_envs dependency
# 'dm_control' if 'macOS' in platform() else
# 'dm_control @ git+git://github.com/deepmind/dm_control@master#egg=dm_control',
'mjrl @ git+git://github.com/aravindr93/mjrl@master#egg=mjrl'],
然后直接安装并测试
# installing
pip install -e .
# 测试,创建test_d4rlpy.py并添加如下内容 vim test_d4rl.py
import gym
import d4rl # Import required to register environments
# Create the environment
env = gym.make('maze2d-umaze-v1')
# d4rl abides by the OpenAI gym interface
env.reset()
env.step(env.action_space.sample())
# Each task is associated with a dataset
# dataset contains observations, actions, rewards, terminals, and infos
dataset = env.get_dataset()
print(dataset['observations']) # An N x dim_observation Numpy array of observations
# Alternatively, use d4rl.qlearning_dataset which
# also adds next_observations.
dataset = d4rl.qlearning_dataset(env)
python test_d4rlpy.py
坑5:如果遇到:下面问题,那就单独安装mjrl
ERROR: Could not find a version that satisfies the requirement mjrl (unavailable) (from d4rl) (from versions: none)
ERROR: No matching distribution found for mjrl (unavailable)
安装命令
pip install git+https://github.com/rail-berkeley/d4rl@master#egg=d4rl
最后的D4RL安装结果结果

最后贴出我的~/.bashrc文件,欢迎参考
# cuda、anaconda等环境变量可以设置在本部分以前
# 环境变量次序也很重要
# mujoco(这里我安装了两部分)
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HOME/.mujoco/mujoco210/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:$HOME/.mujoco/mujoco211/bin
export MUJOCO_KEY_PATH=~/.mujoco${MUJOCO_KEY_PATH}
export MJLIB_PATH=~/.mujoco/lib/libmujoco.so.2.1.1
# nvidia
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/lib/nvidia
export LD_PRELOAD=~/anaconda3/envs/d3rlpy/lib/python3.7/site-packages/d3rlpy/dataset.cpython-37m-x86_64-linux-gnu.so
# export LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libGLEW.so:/usr/lib/nvidia-465/libGL.so
export LD_PRELOAD=/usr/lib/x86_64-linux-gnu/libGLEW.so
更多的坑大家可以参阅issue: https://github.com/rail-berkeley/d4rl/issues
坑6: 有的伙伴可能会用pycharm去运行mujoco会出现一个问题就是:有nvidia的环境变量没有mujoco的,有mujoco的没有nvidia的
Exception:
Missing path to your environment variable.
Current values LD_LIBRARY_PATH=
Please add following line to .bashrc:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/jqw/.mujoco/mujoco210/bin
# 或者这样的
Exception:
Missing path to your environment variable.
Current values LD_LIBRARY_PATH=LD_LIBRARY_PATH:/usr/lib/nvidia
Please add following line to .bashrc:
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/home/jqw/.mujoco/mujoco210/bin
解决办法:
直接在pycharm运行配置中修改环境变量: python文件上右键后进入 Modify Run Configuration

重点就是两个变量之间用 冒号隔开":“,不是分号”;", 然后就ok了
PYTHONUNBUFFERED=1;LD_LIBRARY_PATH=LD_LIBRARY_PATH:/usr/lib/nvidia:$LD_LIBRARY_PATH:/home/jqw/.mujoco/mujoco210/bin
参考文献
[1]. https://sites.google.com/view/d4rl/home
[2]. https://github.com/rail-berkeley/d4rl
[3]. Justin Fu, Aviral Kumar, Ofir Nachum, George Tucker, Sergey Levine, “Datasets for Deep Data-Driven Reinforcement Learning”,2019


















 1710
1710

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











