







背景
稀疏模式自动编码是深度学习神经网络的一个拓展,也是深度学习常见的一个理论。学习稀疏模式自动编码首先需要了解神经网络的背景知识,包括网络结构,fp和bp。不同于常规的有监督神经网络,稀疏模式自动编码是一种不需要标记样本的算法,在算法中样本的标记设为其自身, y(i)=x(i)。换句话说,该算法尝试通过学习网络参数,使得最后的假设h(x)=x。
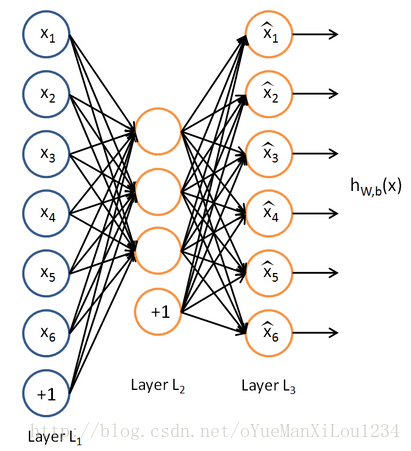
算法思想
稀疏模式自动编码的目标在于希望能够通过添加一些限制条件发现网络中一些有趣的东西。这个限制条件可能有两种,第一,网络中隐含层的单元数很小,而且远远小于输入层,那么就需要对输入层做一个压缩,这看起来非常困难的。但是,如果输入的特征值是有关联的,那么就可以通过这些关联性来压缩输入值,这看起来跟PCA有点像。第二,在网络中加一个稀疏性约束。定义
隐含层的激活为:
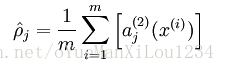
我们的目标是使得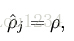 其中
其中  是稀疏参数,通常为0.05。可以看出这是一个很小的数,如果要达到这个目标那么隐含层的激活中大多数的神经单元的激活要接近于0。下一步是计算 和
是稀疏参数,通常为0.05。可以看出这是一个很小的数,如果要达到这个目标那么隐含层的激活中大多数的神经单元的激活要接近于0。下一步是计算 和  的距离,该算法用的是KL距离,该距离可以用来度量两个伯努利随机变量的分布,这两个伯努利分布的均值分别为 和 。
的距离,该算法用的是KL距离,该距离可以用来度量两个伯努利随机变量的分布,这两个伯努利分布的均值分别为 和 。
其中 是稀疏参数,通常为0.05。可以看出这是一个很小的数,如果要达到这个目标那么隐含层的激活中大多数的神经单元的激活要接近于0。下一步是计算 和 的距离,该算法用的是KL距离,该距离可以用来度量两个伯努利随机变量的分布,这两个伯努利分布的均值分别为 和 。

KL距离可以通过一下的公式计算
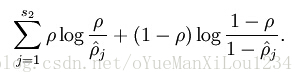
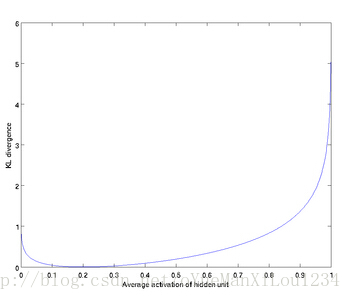
当=0.2时,KL距离如下图所示,当和越近,KL距离越小。
=0.2时,KL距离如下图所示,当和越近,KL距离越小。
在原来的损失函数的基础上添加一个稀疏惩罚项,损失函数可以表达为:
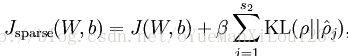
 是稀疏惩罚项的权重。那么隐含层的残差可以计算为:
是稀疏惩罚项的权重。那么隐含层的残差可以计算为: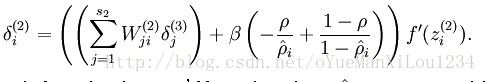
算法求解
最后还是通过梯度下降法求解系数:
















 72
72

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









