







业务介绍
业务背景
当HR/面试官看到一份简历的时候,通常会先从候选人的教育背景和公司背景开始看,那么通常来说,对于清北的学校或者BAT的公司,我们会比较熟悉,那么对于不熟悉的学校或者公司,我们如何能快速的了解这个学校公司的相关信息呢?
简历信息增强就是为了解决这个问题而提出的,我们的目标是避免HR和面试官跳出系统查询信息,而是在系统中一键查看学校和公司的相关信息。
业务形态


流程架构

策略算法
人工干预层
人工干预层位于整个匹配算法的最顶端,主要利用黑名单&白名单的机制实现对于线上问题的快速干预与解决,同时黑白名单的数据既可以作为模型优化的原始数据来使用,也是模型优化迭代的指导方向之一。
黑名单&白名单的数据大概形式如下:
| 类型 | query | value |
| 白名单 | 多点 | 多点新鲜(北京)电子商务有限公司 |
| 黑名单 | 某大型国有企业 | null |
Query理解
Query理解,主要对query进行预处理和成分解析,以及解析后对query的扩展查询,我们的Query理解拆分为了若干个模块,不同的模块负责相应的功能实现,以Pipeline的方式整合到一起,下面简单介绍一下各个模块的具体功能:
Query预处理
Query预处理这个模块相对比较简单,主要对query进行文本上的标准化,从而方便其他模块进行分析:
- 全半角转换;
- 大小写转换;
- 简繁体转换;
- 异形字转换;
- 去除html标记;
- 无意义符号移除;
- ...
Query成分识别
Query成分识别,属于比较典型的NER任务,在我们系统中主要对Query的各个子成分进行拆分,核心的算法主要是规则+NER模型来实现,我们先看两个例子:

规则到模型的演变:

成分识别的作用主要有两个:
- 去除无用的成分,保留抽取的有效信息,将query扩展为新的query进入到召回层;
- 抽取出来的成分,在排序层用于比较成分的相关性;
Query扩展
Query扩展其实就是成分识别的应用之一,不同于常规搜索系统中query扩展主要关注同义性,我们的扩展主要主要是针对冗余的无用信息以及高频公司的扩展,那么利用前面成分识别后的结果,提取有效成分,剔除无用成分组成新的query,一起进入后面的流程,下面是简单的几个例子:
- 北京邮电大学软件学院211硕士 -> 北京邮电大学 (针对学院类的成分,利用词典和规则来鉴别独立学院or二级学院,河北大学工商学院-> 河北大学工商学院)
- 杭州阿里巴巴技术部 -> 杭州阿里巴巴(剔除部门的无用成分)
- 字节跳动xxxx -> 字节跳动(高频扩展)
- ...
召回粗排
本层是真正进入到实体匹配中的第一环节,召回的作用主要是从海量级数据中,快速召回出包含目标结果的小批量数据,用于后面复杂的精排模型,所以对于召回算法不要求排序多么准确,只需要包含目标即可,但是性能速度要快。
目前我们召回的算法主要是利用ES来实现,核心就是BM25的算法,召回策略主要就是对query和实体名称、实体的别名,实体的英文名,实体的产品名等都进行相似度的计算,最终返回TOP-N结果。
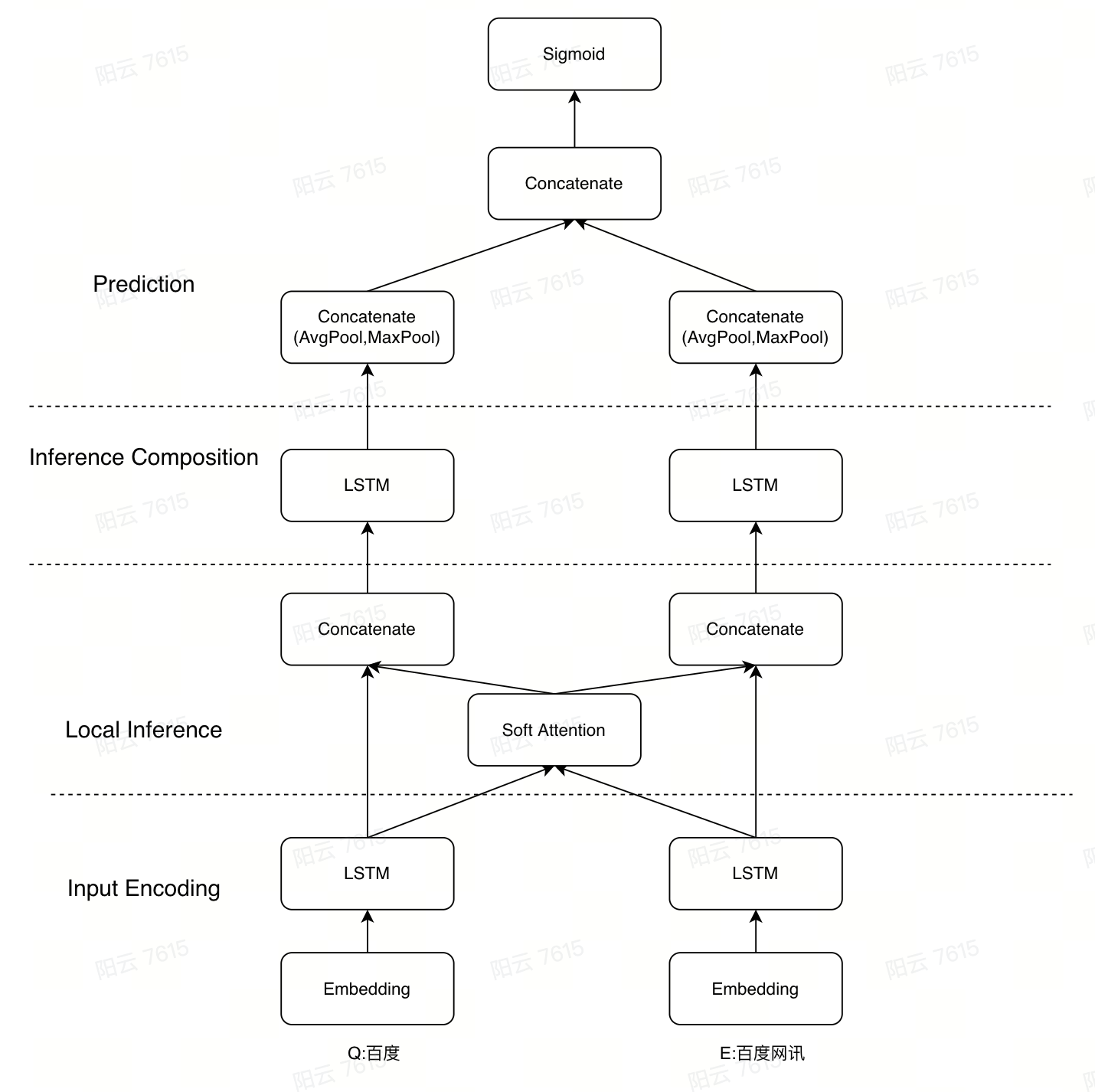
语义匹配
语义匹配的部分,主要是计算query-entity之间的相似度,由于我们的query和entity在名称上是属于同质的短文本,所以问题就变成了短文本匹配的问题。
我们采用了前Bert时代短文本匹配表现比较好的Esim模型(https://arxiv.org/abs/1609.06038),模型的大概结构如下:
模型的优化迭代也是经历了一些过程:
- 词向量 -> 字向量(压缩模型大小)
- 万级别标注数据 -> 千万级别增强数据
-
- 数据增强:
-
-
- 按照Pattern增强:公司-> 公司+部门;
- 噪音增强:学校 -> 学校+无意义后缀;
- 同义词替换增强;字节跳动科技有限公司 -> 字节跳动技术有限公司;
-
-
- 负采样:
-
-
- 随机负采样:随机采取负例样本;
- 近似负采样:根据ES寻找近似实体,采取负样本;
- 比例负采样;根据不同freq设定不同采样比例;
-
- 模型结构改变:合并一些冗余的Dense层,替换LSTM为GRU
核心精排
精排层的设计我们试验了两种思路:
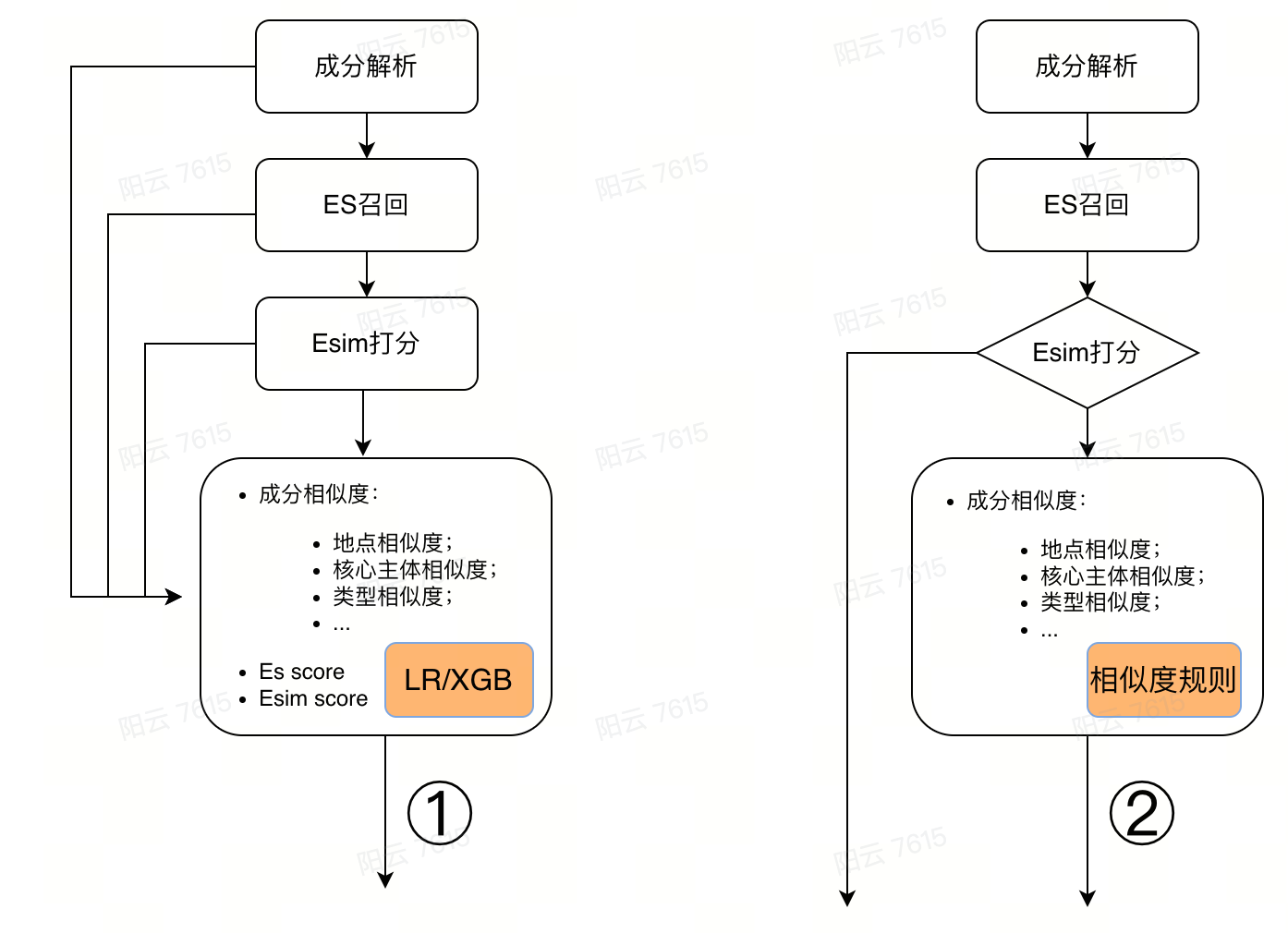
第一种思路的思想就是比较正常的pointwise的思路,就是综合Esim打分的语义相似度,ES打分的文本相似度,以及通过NER成分解析的成分之间的相似度,将这些特征组合在一起,学习一个打分模型,实验之后发现结果并不是绝对提升,即对于原来没有召回的数据,既有表现较好的正确召回,也有表现较差的误召回,分析之后得到的主要原因是训练数据的分布不一致,我们的训练数据是从历史的标注数据中整理来的,这些数据的pattern分布并不能满足模型学到所有可能的情形,导致表现不好,但是手动构造或者标注所有可能的分布也是一个巨大的挑战,于是我们换了一种思路。
第二种思路是这样的,根据我们历史数据的表现,以及分析第一种思路中的feature importance,发现我们的Esim打分的准确率已经是非常高的了,那么我们对于Esim打分符合阈值的结果就直接返回了,不走精排的流程,对于打分比较低的结果,再走一次成分相似度规则的比较来进行兜底召回;
成分相似度的规则主要是根据成分之间的重要度(重要度是人为来定义,比如主体成分>地点成分>类型成分等等,是符合人们来判断两个公司是否一致的直觉定义)来排序,主要排序规则如下:
- 核心主体成分必须equals,否则直接返回False;
- 地点成分比较,相同=同义>上下文关系(四川xx-成都xx)> 不明确关系(一个包含地点,一个不包含地点),否则直接返回False;
- 行业成分比较,编辑距离计算;
- 公司类型比较,编辑距离计算;
- 实体中存在子公司成分,或者部门成分,乘以衰减系数分;
最后按照打分排序,按照设定的最低阈值返回结果。
感知优化
前面的流程已经完成了实体匹配的核心策略,感知优化层的作用主要是业务规则的使用以及对用户使用体验上的提升,目前有几个方面:
- 中英文环境切换:我们会根据用户的环境,自动返回适合用户的语言;
- 地点过滤:过滤掉地点信息和query不一致相矛盾的实体;
- 屏蔽小初高:由于小初高的数据质量并不好,而且在招聘场景中相对意义不大,所以小初高类型的query不返回结果;















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









