







train, validation and test
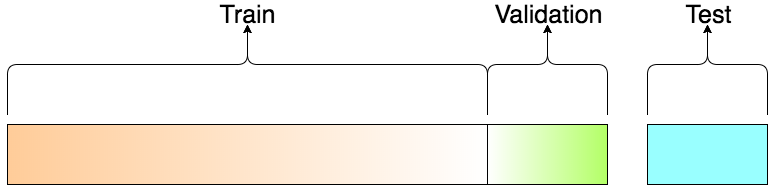
通常分为train和test,在train中分出一份validation,第二步骤重复n次(通常取10)。
Generally splits are done like this:
a) Train
b) Test
Generally, the train data is then split in n parts. n−1 of them are used for training and remaining 1 is used for validation. And, this process is repeated until all the n parts become validation sets once.
out of sample and in sample
| \ | out of sample data | in sample data |
|---|---|---|
| train | no | yes |
| validation | no | yes |
| test | yes | no |
in sample testing <-> purpose: high train accuracy<
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1526
1526

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









