






1.Triton 简介
OpenAI Triton paper 中的介绍是 “An Intermediate Language and Compiler for Tiled Neural Network Computations”,其中几个关键词应该能够代表其特点:
- Intermediate Language, 目前是基于 Python 的 DSL
- Compiler ,是一个经典的 Compiler 的架构
- Tiled Computation,面向 GPU 体系特点,自动分析和实施 tiling
简而言之,Triton 提供了一套针对 GPU Kernel 的开发的 Language(基于 Python) 和 高性能 Compiler。因此,就层次而言,Triton的 DNN 开发能力与 CUDA 的部分(也就是说算子层面)相对应,但与TVM、XLA等直接面向 DL 的 Domain compiler 无法完全对应。TVM、XLA这些深度学习编译器拥有从构图到 auto fusion 等端到端的能力,而Triton则是面向偏底层的也是最通用的 Kernel 开发问题(OpenAI triton分享:Triton概述_哔哩哔哩_bilibili)。
2.Triton代码的架构
Triton 架构总体上如下图所示:

总体分为三部分:
- Frontend(前端),将用户的 Python kernel code 转换为 Triton IR,以及维护 kernel launch 的 Runtime;
- Optimizer,通过各类 pass 将 Triton IR 逐步转换为优化过的 TritonGPU IR;
- Backend(后端),将 TritonGPU IR 逐步转换为 LLVM IR,并最终通过硬件平台后端支持,生成对应的可执行文件,如nvidia上是通过ptxas 编译为 cubin执行。
贯穿这三部分的核心表示是 Triton 的 IR,分为两个层次:
- Triton Dialect,表示计算逻辑,硬件无关的表达;
- TritonGPU Dialect,GPU 相关的计算表示。
这两者都是基于 MLIR 的自定义 dialect,除此之外,Triton 也复用了很多社区的 dialect 来进行宏观的表示,包括:
std dialect: tensor, int, float 等数据类型;
arith dialect:各类数学操作;
scf dialect:if, for 等控制流;
nvvm dialect:获取 thread_id等少量操作;
gpu dialect:printf 等少量操作。
Triton 中IR转换过程(nvidia平台为例)如下图所示:
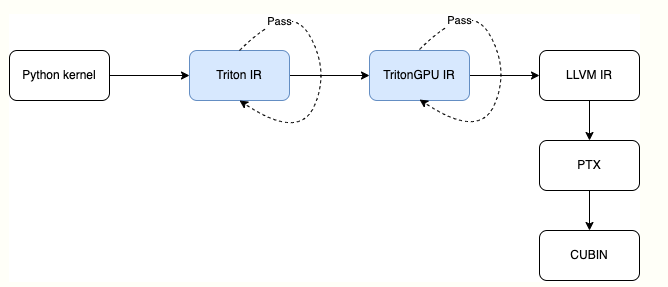
蓝色的两部分主要是 MLIR 体系涉及的部分,随后 MLIR 会转换为 LLVM IR,之后 Triton 会调用 NVPTX 转换为 PTX Assembly,随后由 CUDA 的 ptxas 编译器编译为 cubin(OpenAI triton分享:triton编译流程_哔哩哔哩_bilibili)。

















 723
723

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









