






参考代码
G的网络搭建
DIM=64
class Generator(nn.Module):
def __init__(self):
super(Generator, self).__init__()
preprocess = nn.Sequential(
nn.Linear(128, 4*4*4*DIM),
nn.ReLU(True),
)
block1 = nn.Sequential(
nn.ConvTranspose2d(4*DIM, 2*DIM, 5),
nn.ReLU(True),
)
block2 = nn.Sequential(
nn.ConvTranspose2d(2*DIM, DIM, 5),
nn.ReLU(True),
)
deconv_out = nn.ConvTranspose2d(DIM, 1, 8, stride=2)
self.block1 = block1
self.block2 = block2
self.deconv_out = deconv_out
self.preprocess = preprocess
self.sigmoid = nn.Sigmoid()
def forward(self, input):
output = self.preprocess(input)
output = output.view(-1, 4*DIM, 4, 4)
#print output.size()
output = self.block1(output)
#print output.size()
output = output[:, :, :7, :7]
#print output.size()
output = self.block2(output)
#print output.size()
output = self.deconv_out(output)
output = self.sigmoid(output)
#print output.size()
return output.view(-1, OUTPUT_DIM)
我们传一个128维的噪音进去,观察28*28图像的生成过程
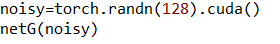

要想理解这个生成过程,必须知道普通的Conv2D网络output_size和input_size的计算方法:
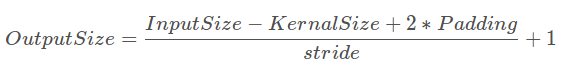
Conv2DTranspose是Conv2D的逆转,如果我们想要由Conv2DTranspose完成a*a->b*b的上采样,所需要的参数是b*b->a*a通过Conv2D进行上采样中所用的。
一开始我们传入一个长度为128的一维tensor,这个tensor在经过一层全连接层后,得到4*4*4*64个特征,这些特征是这样分布的:4*64作为深度,4*4作为size,这一步通过一次reshape(即view)实现。
通过输出,我们知道生成的是(2*64,8*8)的feature map,深度的变化是由Conv2DTranspose的深度决定的,而size是由kernal_size,padding和stride决定的,我们知道,这里第一层Conv2DTranspose采用的是kernal_size=5,padding=0(by default),stride=1(by default),如果这是个Conv2D层,他会将inputsize=8转化为(8-5+0)/1+1=4=outputsize,而这是个Conv2DT层,完成相反的工作,得到outputsize=8。
用类似的思路,我们可以计算所有的size变化。
W-GP-Loss的实现

1.



首先,我们只需要知道real_data_v和inputv是一个由real生成的[batchsize,(28,28)]的tensor,将其放入辨别器D,得到[batchsize]个[0,1]之间的得分。
然后,我们对其取均值(目的是将一个batch中的socre相加),作为loss做一次BP。
这里做BP的方法用到了backward的参数(grad_tensor),我们传入一个scalar tensor[-1],这个参数的意思是每一次梯度下降都乘上这个tensor,就形成了paper中的线性Loss,这里real传入-1,fake传入1,实际上倒过来(real传入1,fake传入-1)也是可以的,只要在下面训练G时对应。

GP函数

 传设入一个[50,28*28]real_tensor。一个[50,28,28]的fake_tensor。
传设入一个[50,28*28]real_tensor。一个[50,28,28]的fake_tensor。
1.融合得到[50,28,28]的alpha。
2.将alpha传入D得到[50,1]的score。
3.score对alpha求导得[50,28*28]的导数gradient,这里是只对传入的alpha求导。注意grad()的返回值加了[0],这是因为原返回值是一个len=1的tuple。
4.gradient.norm(2,dim=1)会对dim=1(即vector)求一次2-范数,这里实际上是对50个长为28*28的gradient_vector分别求了2范数,然后将其减1平方再求平均,得到一个scalar。
注意norm这个函数这里如果不传dim=1,会对这个[50,28*28]的矩阵求矩阵的二范数,而传dim=1之后是对50个vector求向量的二范数。















 2261
2261











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









