






我会提供给你大概1亿条真实的互联网用户上网数据,至于来源,我先不告诉你,绝对是你在网络上无法找到的宝贵数据源。
此外,还会给你提供一个基于当前数据特点而设计的大数据处理方案。
当然,为了防止用户的隐私部分被泄露,我对一些关键字段进行了脱敏,如果说你有什么坏心思的话,暂时就别想了。但是即便如此,这份数据,我相信对你学习大数据的用处都是非常大的。
|数据源解读|数据API接口
这份数据长这样,有非常规整的9个字段(我都替你清洗过了),为了方便你们读取,我把它导出成CSV文件,其中第一行是schema。

为了方便大家获取,我把它放到了云盘上,原文件有12G,我通过压缩之后,也有3G,为了保证大家是真的用这份数据在学习,而不是干别的,这个下载地址需要你加我微信后告诉你。
现在来帮你解读下这份数据,一共个9个字段,其字段意义解释分别如下:
client_ip: 指上网用户的ip地址,你可以根据这个ip知道这个用户大概的位置信息,这个有专门的api可以查询;
domain:指上网人要上的网站地址,你可以根据该网站的性质来判断这个人的上网行为;
time:上网人的上网时间;
target_ip: 上网人要上的网站的目标ip地址;
rcode:网站返回状态码,0为正常响应,2为不正常;
query_type: 查询类型,几乎都是1,即正常上网行为;
authority_recode:网站服务器真正返回的域名,可能跟domain不一样,如果不一样的话,可能说明是个钓鱼网站之类的,你可以去分析分析;
add_msg: 附加信息,几乎都为空,你可以看看如果有内容的话,到底是什么玩意;
dns_ip:当前要上的这个网站由哪个DNS服务器给提供的解析,一般一个DNS服务器会服务一个区域,如果由同一个DNS服务器进行解析的,说明他们在同一片大的区域;
以上是对这份数据的字段解读,相信从这些解释中,你已经大概能了解这份数据的作用了。
|如何建大数据项目
既然数据源了解清楚了,也就知道了大概的业务场景。
那么接下来就是如何架构一个大数据项目,为了保证项目的完整性、紧凑性、和易上手性,我特意设计了一个时下最流行的lamda数据处理架构,供你参考:
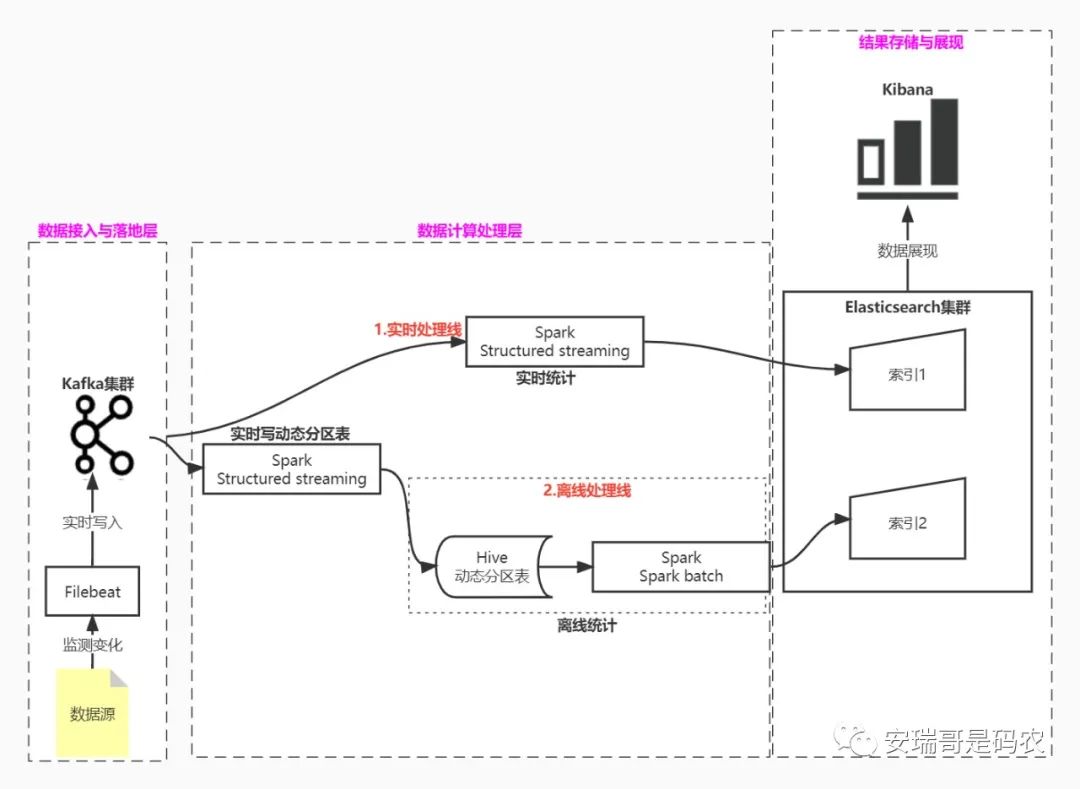
可以看到,该架构包含了完整的、任何大数据系统都具备的:数据接入、数据落地、数据计算、结果存储,以及最后的结果展现功能。
通过对这个有着完整功能的大数据系统进行实践和学习,如果你能把这套架构真正玩好的话,你会发现,市面上任何复杂的大数据架构在你眼里也不过尔尔,你会有种【万变不离其宗】的掌控感。
当然,这里我只是给你提供参考,具体实践还得看你具体情况,如果你已经有集群环境了,我希望你能尽可能去贴近我的这个架构,因为万一你在实践中出了什么问题,都可以来找我交流探讨。
|你要做哪些准备
数据给你了,架构也给你确定了,接下来你需要做的是:根据以上要求,搭建一套集群环境,这个集群你可以是自己的虚拟机,有条件也可以租个云服务器,然后构建4个节点的集群环境,具体配置建议如下:
| 节点角色 | 硬件配置 | 节点数量 |
| 主节点/客户端节点 | 4G以上内存、50G以上硬盘,4核以上CPU | 1 |
| 计算/存储节点 | 8G以上内存、100G以上硬盘,8核以上CPU | 3 |
当然,以上是建议配置,有人说我电脑配置不够怎么办?没事,你可以适当降低要求,配置可以再降低一点,节点数量最好不要低于3个,你需要知道一点的是,配置越低,你玩数据的自由度就越低,但是还是可以玩。
以上配置准备OK,那么接下来你就需要安装集群了,相信这个对于一个学习大数据的人来说,是最基础的一步了,因为只有你会安装了,才能建立起对各个大数据组件大概是个什么东东有个初步的了解。
根据我给的架构要求,你要安装以下这些组件:
1,Hadoop:HDFS+YARN,这个是集群的底座,hive、spark都依赖它;
2,Filebeat:数据源接入工具,这个用来监控数据源变化的,然后将新增的数据写入到kafka,我是觉得它好用,所以向你推荐,当然,如果你用别的工具也可以,那就用你喜欢的代替;
3,kafka:这个不多介绍,当前最流行的流式架构的当红炸子鸡,用来承载流式数据的落地;
4,spark:当今最流行的流批一体分布式计算引擎之一,用他来做数据分析处理;
5,hive:当今大数据的主流数仓组件,用来做离线数据存储和分析;
6,Elasticsearch:当下最流行的分布式搜索引擎,用来做全文检索非常的高效、方便,用来存储分析后的数据;
7,kibana:专门对Elasticsearch数据进行可视化展现的,用它,你可以直观的看到你最后分析的结果数据是个什么样子;
看着是不是很多?首先不要急,一个个安装,其实很快,网上有很多安装部署的教程,这里我就不赘述,你有问题了再找我交流。
其次呢,这些技术组件都是当下主流的,组合在一起,让你在一个实际项目中练手,对你非常有帮助,你试试就知道了。
至于安装的版本,我建议你们不要安装最新的,给你们参考我目前测试集群的版本:HDP3.1(hadoop3.1,kafka、hive都给你关联好) + Elasticsearch7.6。
如果你想部署跟我一样的版本,可以私信找我要安装包,我这全套都有。当然,跟我部署一样,还有个好处就是,你遇到任何技术问题,我应该都可以帮你搞定,因为我,可能都遇到过。
|最后
想告诉你的是,想要学好大数据,动手实践一定是最重要的,我相信你如果能够按照我的这个要求一步步,脚踏实地去做,你的大数据技能一定能得到一个质的飞跃。
不信,你来打我。
PS:可能有人会问,这些数据,基于什么业务要求去做开发呢?
来,给你点思路:
1,用wordcount的方式去统计每个client_ip的数量,看哪些ip上网的次数最多?批处理的方式,跟流式实时的方式都试一下,看结果是否一致?
2,看上网最多的,那几个ip,都上的什么网站,集中上网的时间点都是几点?
3,被上的最多的网站中对应的ip,跟上网最多的ip之间有多少是重合的?
4,哪些ip喜欢上一些类似钓鱼网站的网站;
5,....
怎么样?是不是思路一下子就打开了?















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









