







 BiSeNet是一种用于实时语义分割的网络,通过结合SpatialPath和ContextPath,平衡了空间细节和大感受野的需求。SpatialPath保持高分辨率特征,ContextPath获取大范围上下文信息。此外,AttentionRefinementModule增强特征表示,FeatureFusionModule有效融合两路径的特征。BiSeNet避免了传统方法中牺牲精度以换取速度的问题,适用于实时场景的高效分割任务。
BiSeNet是一种用于实时语义分割的网络,通过结合SpatialPath和ContextPath,平衡了空间细节和大感受野的需求。SpatialPath保持高分辨率特征,ContextPath获取大范围上下文信息。此外,AttentionRefinementModule增强特征表示,FeatureFusionModule有效融合两路径的特征。BiSeNet避免了传统方法中牺牲精度以换取速度的问题,适用于实时场景的高效分割任务。
paper:BiSeNet: Bilateral Segmentation Network for Real-time Semantic Segmentation
创新点
- 设计了一个下采样stride小的Spatial Path用来保存空间信息,生成高分辨率的特征
- 采用了一个具有快速下采样策略的Context Path用来获取足够大的感受野
- 引入了一种新的特征模块来有效的融合两个Path的特征
- 设计了一个Attention Refinement Module (ARM)
目前,现有的实时语义分割算法主要采用三种方法来实现模型加速
- 限制输入大小
- 减少网络通道数
- ENet丢弃模型的最后一个stage,使得模型结构更紧凑
但是这些方法为了追求速度都在一定程度上降低了精度,比如减小模型输入大小会造成空间细节的丢失;减少网络通道数(通常在浅层阶段)会降低模型的空间表达能力;ENet丢弃了模型的最后一个stage,因为同时丢弃了最后一个stage中的下采样操作,导致模型的感受野不足以覆盖较大的目标,从而导致模型的辨别能力较差。
为了弥补上述方法空间细节的损失,研究人员广泛采用U型模型结构,通过融合主干网络的特征,逐步提高空间分辨率,填补了一些缺失的细节。但这种结构也有两个缺点:(1)由于在高分辨率特征图上引入了额外的计算量,降低了模型的速度(2)在修剪过程中丢失的大部分细节信息无法通过融合浅层特征轻松地恢复
针对上述问题,作者提出了Bilateral Segmentation Network(BiSeNet),包含Spatial Path和Context Path两部分,分别用来应对空间信息的损失和感受野不够大的问题。对于Spatial Path,只包含三层卷积得到1/8大小的输出,保留了丰富的空间细节。对于Context Path,在Xception的最后加一个全局平均池化,获得了最大的感受野。如下图(c)所示
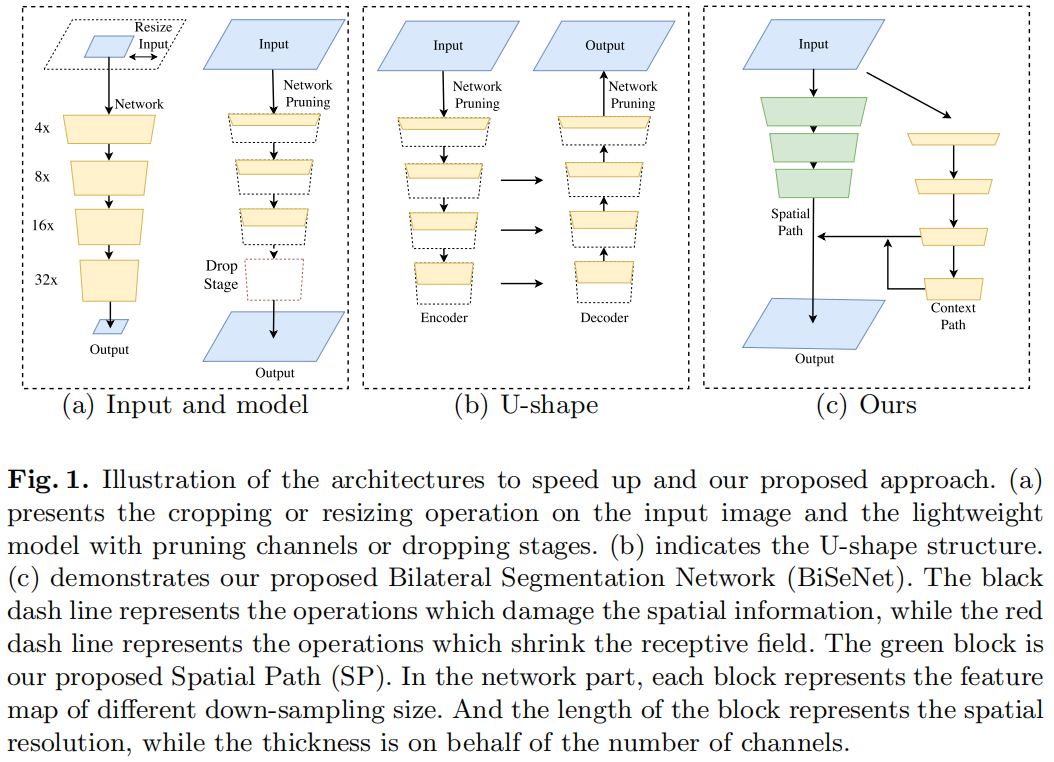
Bilateral Segmentation Network的完整结构
下图是BiSeNet的完整结构
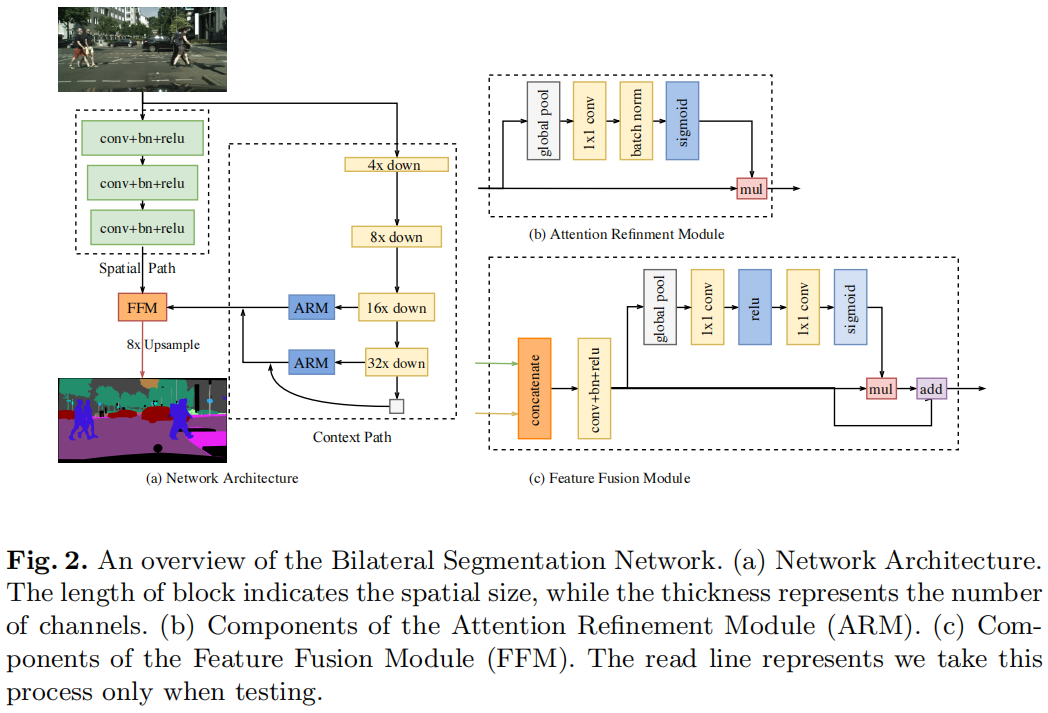
Spatial Path
spatial path共有三层,每一层包括一个stride=2的卷积后接BN和ReLU,输出特征图的大小是原始输入的1/8,由于较大的spatial size,其编码了丰富的空间信息,具体如上图(a)所示
Context Path
context path是为了获取足够大的感受野,以往的方法包括pyramid pooling module、atrous spatial pyramid pooling、"large kernel"计算量和内存消耗都比较大,因此速度比较慢。同时考虑到大感受野和速度,context path采用轻量模型Xception,其后接一个global average pooling,这样就获得了最大的感受野。然后仿照U-shape结构,将gap的输出上采样并与后两个stage的特征融合,具体如上图(c)所示
Attention refinement module
作者设计一个ARM模块可以更好的提炼每个stage的特征,这里借鉴了SENet中的se module,首先通过全局平均池化提取全局语义信息,然后学习一个attention vector来指导特征的学习。
Feature fusion module
因为两个path提取的特征是不同的,spatial path主要提取了丰富的空间细节特征,而context path则主要提取语义信息,因此不能直接通过简单的相加来融合两个path的输出。作者设计了特征融合模块,可以更好的融合两个path提取到的low-level和high-level特征。
实现细节
下面以MMSegmentation中的bisenet v1实现为例,介绍一下具体实现细节
假设batch_size=4,输入shape为(4, 3, 480, 480)。这里context path采用ResNet-50而不是文章中的Xception
spatial path
- 和文章中3个conv-bn-relu不同,这里采用了4个conv-bn-relu,分别为7x7-s2-p3、3x3-s2-p1、3x3-s2-p1、1x1-s1,输出channels为(256, 256, 256, 512),feature map维度为(4, 3, 480, 480) -> (4, 256, 240, 240) -> (4, 256, 120, 120) -> (4, 256, 60, 60) -> (4, 512, 60, 60)。
context path
- backbone采用resnet-50而不是Xception,得到4个stage不同下采样倍数的输出x_4, x_8, x_16, x_32,维度分别为(4, 256, 120, 120), (4, 512, 60, 60), (4, 1024, 30, 30), (4, 2048, 15, 15)
- x_32经过gap-1x1conv-bn-relu得到x_gap,(4, 2048, 15, 15) -> (4, 2048, 1, 1) -> (4, 512, 1, 1)
- x_32经过ARM module,arm module的具体实现:x_32经过3x3conv-bn-relu得到x: (4, 512, 15, 15),然后x经过gap-1x1conv-bn-sigmoid得到x_atten: (4, 512, 1, 1),然后x*x_atten得到arm module的输出x_32_arm: (4, 512, 15, 15)
- 然后x_gap + x_32_arm得到x_32_sum: (4, 512, 15, 15)。(这里x_gap的首先通过broadcast成(4,512,15,15)然后才能与x_32_arm相加,不知道这里的实现有没有问题)
- x_32_sum通过最近邻插值上采样resize成x_16大小得到(4,512,30,30),然后再经过3x3conv得到x_32_up: (4,512,30,30)
- x_16通过arm module得到x_16_arm: (4, 512, 30, 30)。然后与x_32_up相加得到x_16_sum: (4, 512, 30, 30)。然后通过'nearest'插值上采样得到(4, 512,60, 60),然后经过3x3conv得到x_16_up: (4, 512, 60, 60)。
- context path的最终输出即为x_16_up,即x_context8,因为实际是下采样8倍
feature fusion module
- ffm模块的输入为spatial path和context path的输出,shape都是(4, 512, 60, 60)
- 首先concatenate得到(4, 1024, 60, 60)
- 1x1conv-bn-relu得到x_fuse: (4, 1024, 60, 60)
- gap得到(4, 1024, 1, 1)
- 1x1conv-bn-relu-sigmoid得到x_atten: (4, 1024, 1, 1)
- x_fuse * x_atten得到(4, 1024, 60, 60),然后再与x_fuse相加得到ffm的最终输出x_fuse: (4, 1024, 60, 60)
decode head
- ffm的输出x_fuse经过3x3conv-bn-relu得到(4, 1024, 60, 60)
- 采用dropout,ratio=0.1
- 经过1x1conv得到模型最终输出(4, num_class, 60, 60)
loss
- decode head的输出通过双线性插值得到模型原始输入大小(4, num_class, 480, 480)
- 采用bce loss
Auxiliary head
- 在实际训练过程中作者还添加了两个辅助分支对模型中间的输出进行监督训练,这两个分支只在训练过程中会用到,测试时只用decode head的输出。
- 这两个分支的输入分别是context path中的x_32_up和x_16_up
- 辅助分支和decode分支一样采用的fcn head,具体包括3x3conv-bn-relu、dropout、1x1conv分别得到两个辅助分支的输出,然后通过上采样恢复原始输入大小,采用bce loss与ground truth计算损失
实现代码
这里的代码是MMSegmentation中的实现
# Copyright (c) OpenMMLab. All rights reserved.
import torch
import torch.nn as nn
from mmcv.cnn import ConvModule
from mmcv.runner import BaseModule
from mmseg.ops import resize
from ..builder import BACKBONES, build_backbone
class SpatialPath(BaseModule):
"""Spatial Path to preserve the spatial size of the original input image
and encode affluent spatial information.
Args:
in_channels(int): The number of channels of input
image. Default: 3.
num_channels (Tuple[int]): The number of channels of
each layers in Spatial Path.
Default: (64, 64, 64, 128).
Returns:
x (torch.Tensor): Feature map for Feature Fusion Module.
"""
def __init__(self,
in_channels=3,
num_channels=(64, 64, 64, 128),
conv_cfg=None,
norm_cfg=dict(type='BN'),
act_cfg=dict(type='ReLU'),
init_cfg=None):
super(SpatialPath, self).__init__(init_cfg=init_cfg)
assert len(num_channels) == 4, 'Length of input channels \
of Spatial Path must be 4!'
self.layers = []
for i in range(len(num_channels)):
layer_name = f'layer{i + 1}'
self.layers.append(layer_name)
if i == 0:
self.add_module(
layer_name,
ConvModule(
in_channels=in_channels,
out_channels=num_channels[i],
kernel_size=7,
stride=2,
padding=3,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg))
elif i == len(num_channels) - 1:
self.add_module(
layer_name,
ConvModule(
in_channels=num_channels[i - 1],
out_channels=num_channels[i],
kernel_size=1,
stride=1,
padding=0,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg))
else:
self.add_module(
layer_name,
ConvModule(
in_channels=num_channels[i - 1],
out_channels=num_channels[i],
kernel_size=3,
stride=2,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg))
def forward(self, x):
for i, layer_name in enumerate(self.layers):
layer_stage = getattr(self, layer_name)
x = layer_stage(x)
# (4,3,480,480)->(4,256,240,240)->(4,256,120,120)->(4,256,60,60)->(4,512,60,60)
return x
class AttentionRefinementModule(BaseModule):
"""Attention Refinement Module (ARM) to refine the features of each stage.
Args:
in_channels (int): The number of input channels.
out_channels (int): The number of output channels.
Returns:
x_out (torch.Tensor): Feature map of Attention Refinement Module.
"""
def __init__(self,
in_channels,
out_channel,
conv_cfg=None,
norm_cfg=dict(type='BN'),
act_cfg=dict(type='ReLU'),
init_cfg=None):
super(AttentionRefinementModule, self).__init__(init_cfg=init_cfg)
self.conv_layer = ConvModule(
in_channels=in_channels,
out_channels=out_channel,
kernel_size=3,
stride=1,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
self.atten_conv_layer = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
ConvModule(
in_channels=out_channel,
out_channels=out_channel,
kernel_size=1,
bias=False,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=None), nn.Sigmoid())
def forward(self, x):
x = self.conv_layer(x)
x_atten = self.atten_conv_layer(x)
x_out = x * x_atten
return x_out
class ContextPath(BaseModule):
"""Context Path to provide sufficient receptive field.
Args:
backbone_cfg:(dict): Config of backbone of
Context Path.
context_channels (Tuple[int]): The number of channel numbers
of various modules in Context Path.
Default: (128, 256, 512).
align_corners (bool, optional): The align_corners argument of
resize operation. Default: False.
Returns:
x_16_up, x_32_up (torch.Tensor, torch.Tensor): Two feature maps
undergoing upsampling from 1/16 and 1/32 downsampling
feature maps. These two feature maps are used for Feature
Fusion Module and Auxiliary Head.
"""
def __init__(self,
backbone_cfg,
context_channels=(128, 256, 512),
align_corners=False,
conv_cfg=None,
norm_cfg=dict(type='BN'),
act_cfg=dict(type='ReLU'),
init_cfg=None):
super(ContextPath, self).__init__(init_cfg=init_cfg)
assert len(context_channels) == 3, 'Length of input channels \
of Context Path must be 3!'
self.backbone = build_backbone(backbone_cfg)
self.align_corners = align_corners
self.arm16 = AttentionRefinementModule(context_channels[1],
context_channels[0])
self.arm32 = AttentionRefinementModule(context_channels[2],
context_channels[0])
self.conv_head32 = ConvModule(
in_channels=context_channels[0],
out_channels=context_channels[0],
kernel_size=3,
stride=1,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
self.conv_head16 = ConvModule(
in_channels=context_channels[0],
out_channels=context_channels[0],
kernel_size=3,
stride=1,
padding=1,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
self.gap_conv = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
ConvModule(
in_channels=context_channels[2],
out_channels=context_channels[0],
kernel_size=1,
stride=1,
padding=0,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg))
def forward(self, x):
x_4, x_8, x_16, x_32 = self.backbone(x)
# (4,256,120,120),(4,512,60,60),(4,1024,30,30),(4,2048,15,15)
x_gap = self.gap_conv(x_32) # (4,512,1,1)
x_32_arm = self.arm32(x_32) # (4,512,15,15)
x_32_sum = x_32_arm + x_gap
x_32_up = resize(input=x_32_sum, size=x_16.shape[2:], mode='nearest') # (4,512,30,30)
x_32_up = self.conv_head32(x_32_up) # (4,512,30,30)
x_16_arm = self.arm16(x_16) # (4,512,30,30)
x_16_sum = x_16_arm + x_32_up
x_16_up = resize(input=x_16_sum, size=x_8.shape[2:], mode='nearest') # (4,512,60,60)
x_16_up = self.conv_head16(x_16_up) # (4,512,60,60)
return x_16_up, x_32_up
class FeatureFusionModule(BaseModule):
"""Feature Fusion Module to fuse low level output feature of Spatial Path
and high level output feature of Context Path.
Args:
in_channels (int): The number of input channels.
out_channels (int): The number of output channels.
Returns:
x_out (torch.Tensor): Feature map of Feature Fusion Module.
"""
def __init__(self,
in_channels,
out_channels,
conv_cfg=None,
norm_cfg=dict(type='BN'),
act_cfg=dict(type='ReLU'),
init_cfg=None):
super(FeatureFusionModule, self).__init__(init_cfg=init_cfg)
self.conv1 = ConvModule(
in_channels=in_channels,
out_channels=out_channels,
kernel_size=1,
stride=1,
padding=0,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg)
self.gap = nn.AdaptiveAvgPool2d((1, 1))
self.conv_atten = nn.Sequential(
ConvModule(
in_channels=out_channels,
out_channels=out_channels,
kernel_size=1,
stride=1,
padding=0,
bias=False,
conv_cfg=conv_cfg,
norm_cfg=norm_cfg,
act_cfg=act_cfg), nn.Sigmoid())
def forward(self, x_sp, x_cp):
x_concat = torch.cat([x_sp, x_cp], dim=1) # (4,1024,60,60)
x_fuse = self.conv1(x_concat) # (4,1024,60,60)
x_atten = self.gap(x_fuse) # # (4,1024,1,1)
# Note: No BN and more 1x1 conv in paper.
x_atten = self.conv_atten(x_atten) # (4,1024,1,1)
x_atten = x_fuse * x_atten # (4,1024,60,60)
x_out = x_atten + x_fuse # (4,1024,60,60)
return x_out
@BACKBONES.register_module()
class BiSeNetV1(BaseModule):
"""BiSeNetV1 backbone.
This backbone is the implementation of `BiSeNet: Bilateral
Segmentation Network for Real-time Semantic
Segmentation <https://arxiv.org/abs/1808.00897>`_.
Args:
backbone_cfg:(dict): Config of backbone of
Context Path.
in_channels (int): The number of channels of input
image. Default: 3.
spatial_channels (Tuple[int]): Size of channel numbers of
various layers in Spatial Path.
Default: (64, 64, 64, 128).
context_channels (Tuple[int]): Size of channel numbers of
various modules in Context Path.
Default: (128, 256, 512).
out_indices (Tuple[int] | int, optional): Output from which stages.
Default: (0, 1, 2).
align_corners (bool, optional): The align_corners argument of
resize operation in Bilateral Guided Aggregation Layer.
Default: False.
out_channels(int): The number of channels of output.
It must be the same with `in_channels` of decode_head.
Default: 256.
"""
def __init__(self,
backbone_cfg,
in_channels=3,
spatial_channels=(64, 64, 64, 128),
context_channels=(128, 256, 512),
out_indices=(0, 1, 2),
align_corners=False,
out_channels=256,
conv_cfg=None,
norm_cfg=dict(type='BN', requires_grad=True),
act_cfg=dict(type='ReLU'),
init_cfg=None):
super(BiSeNetV1, self).__init__(init_cfg=init_cfg)
assert len(spatial_channels) == 4, 'Length of input channels \
of Spatial Path must be 4!'
assert len(context_channels) == 3, 'Length of input channels \
of Context Path must be 3!'
self.out_indices = out_indices
self.align_corners = align_corners
self.context_path = ContextPath(backbone_cfg, context_channels,
self.align_corners)
self.spatial_path = SpatialPath(in_channels, spatial_channels)
self.ffm = FeatureFusionModule(context_channels[1], out_channels) # 1024,1024
self.conv_cfg = conv_cfg
self.norm_cfg = norm_cfg
self.act_cfg = act_cfg
def forward(self, x):
# stole refactoring code from Coin Cheung, thanks
x_context8, x_context16 = self.context_path(x) # (4,512,60,60),(4,512,30,30)
x_spatial = self.spatial_path(x) # (4,512,60,60)
x_fuse = self.ffm(x_spatial, x_context8) # (4,1024,60,60)
outs = [x_fuse, x_context8, x_context16] # [(4,1024,60,60),(4,512,60,60),(4,512,30,30)]
outs = [outs[i] for i in self.out_indices] # (0,1,2)
return tuple(outs)
Ablation Study
下面是针对BiSeNet中各个模块消融实验的结果,可以看出Spatial Path、FFM、ARM、GP和对应的baseline相比都对精度有一定的提升
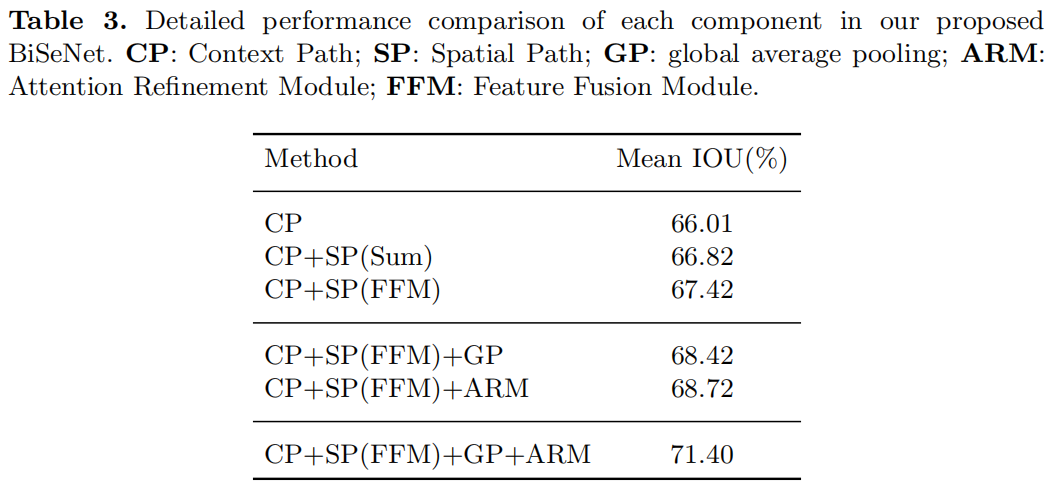
Experiment Results
下面是在一些公开数据集上和其它模型的结果
Cityscapes
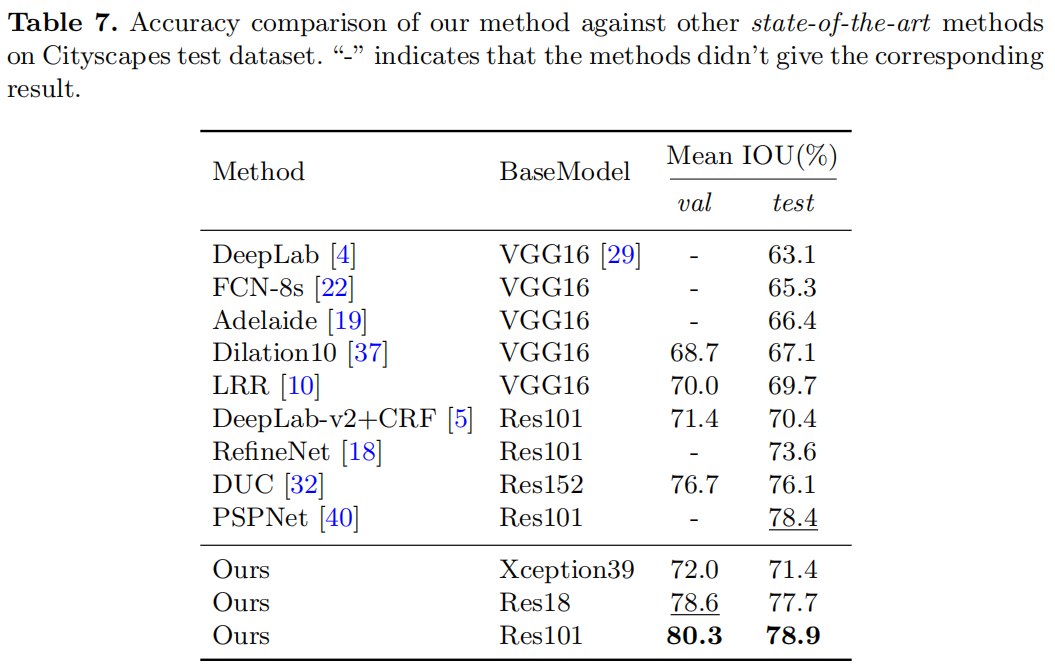
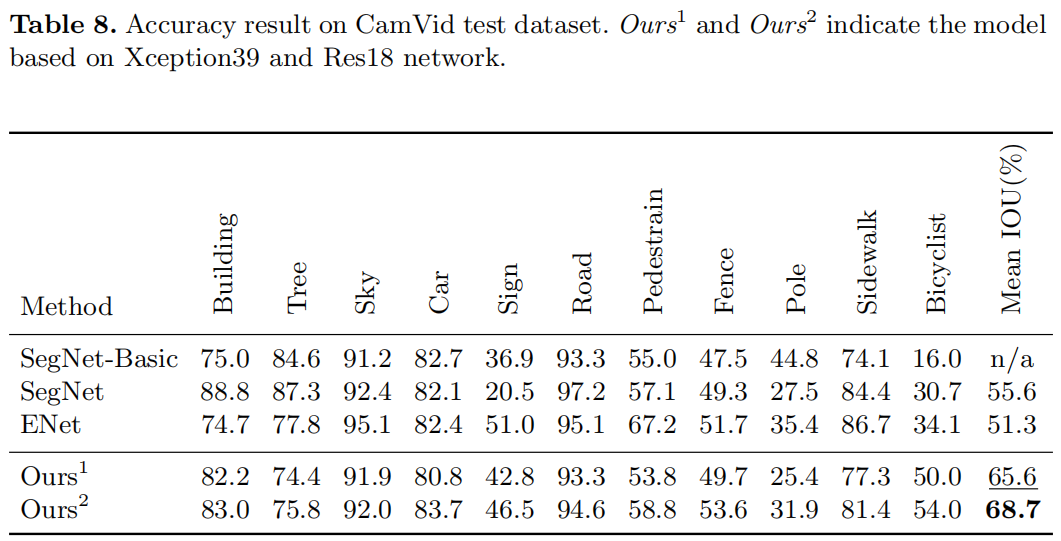
CamVid
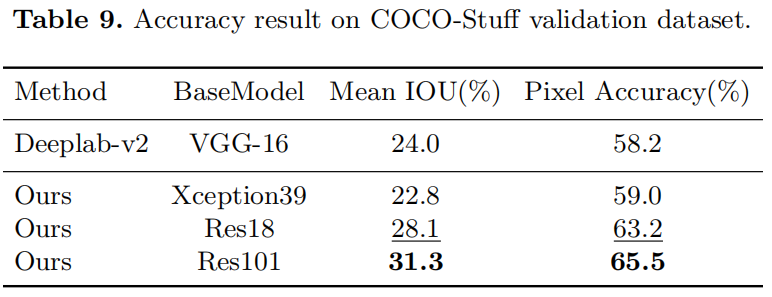
COCO-Stuff


















 845
845

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











