






BiSeNet升级版——BiSeNet V2
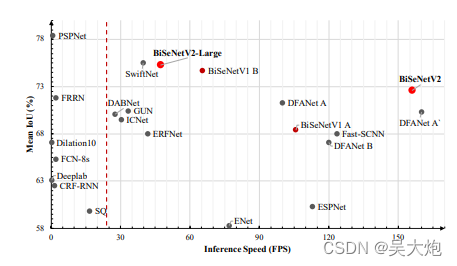
BiSeNet V2是BiSeNet的升级版,从论文中看效果肯定好,还是直接看相应的结构和代码吧😊
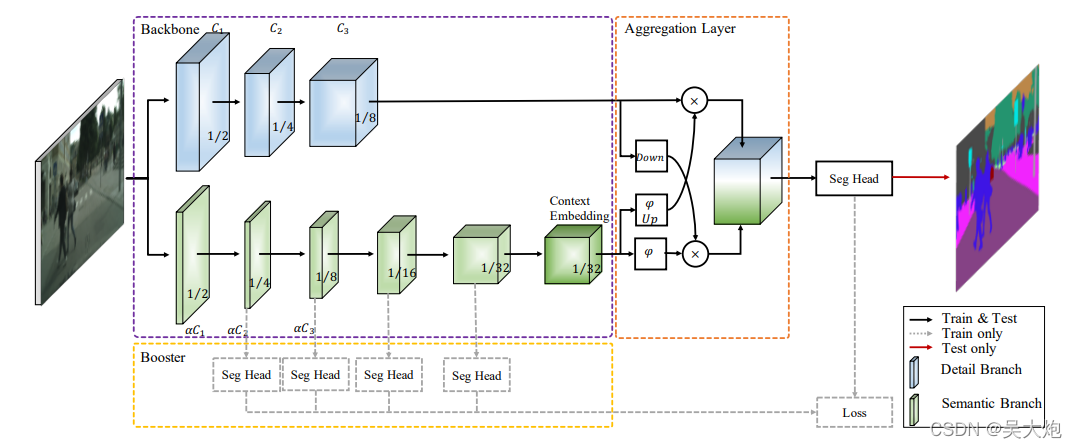
主要有三个组成部分:紫色虚线框内的双通道主干,橙色虚线框内的聚集层,黄色虚线框内的助推部分。双通道主干有一个细节分支(蓝色的数据集)和一个语义分支(绿色的数据集)。三个阶段支路分别有C1、C2、C3通道。相应阶段的渠道语义分支可以轻量级的因子λ(λ< 1)。语义分支的最后一个阶段是上下文嵌入块的输出。同时,立方体中的数字是特征映射大小与输入分辨率的比值。在聚合层部分,我们采用了双边聚合层。将采样操作表明,Up代表upsampling操作,ϕ是Sigmoid函数,和x意味着element-wise输出。此外,在推理部分,设计了一些辅助分割头,以提高分割性能,没有任何额外的推理成本
主要包括三个部分
detail branch
空间细节 浅层信息,遵循VGG设计的
细节分支为共有9个卷积层,一共下采样了八倍,总体来说是比较简单的结构
class DetailBranch(nn.Module):
def __init__(self):
super(DetailBranch, self).__init__()
self.S1 = nn.Sequential(
ConvBNReLU(3, 64, 3, stride=2),
ConvBNReLU(64, 64, 3, stride=1),
)
self.S2 = nn.Sequential(
ConvBNReLU(64, 64, 3, stride=2),
ConvBNReLU(64, 64, 3, stride=1),
ConvBNReLU(64, 64, 3, stride=1),
)
self.S3 = nn.Sequential(
ConvBNReLU(64, 128, 3, stride=2),
ConvBNReLU(128, 128, 3, stride=1),
ConvBNReLU(128, 128, 3, stride=1),
)
def forward(self, x):
feat = self.S1(x)
feat = self.S2(feat)
feat = self.S3(feat)
return feat
Semantic Branch
为了得到较大的感受野和加快计算效率,而设计语义分支,捕捉高层语义信息、与detail branch平行布置、参考了轻量级的网络结构
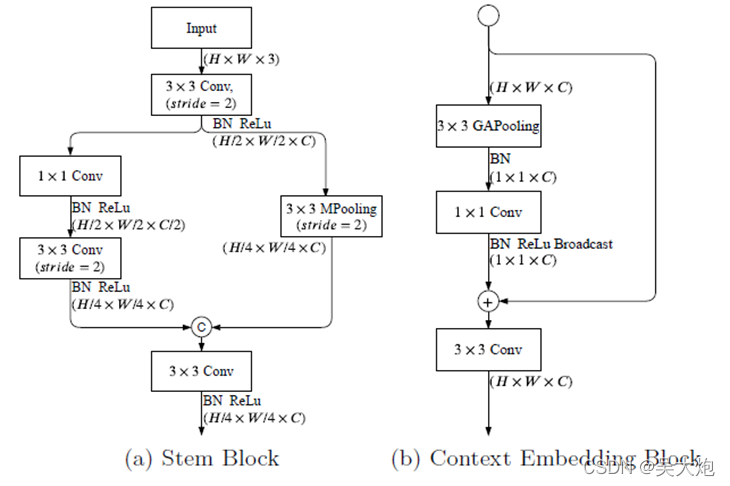
Stem block和context embedding block结构如图示。
(a) 是采用快速下采样策略的Stem块。该块有两个分支,它们以不同的方式对特征表示进行下采样。然后将两个分支的两个特征响应连接起来作为输出。
(b) 是上下文嵌入块。语义分支需要大的感受野。因此,我们设计了一个具有全局平均池的上下文嵌入块来嵌入全局上下文信息。GPooling是全局平均池。同时,1×1,3×3表示核的大小,H×W×C表示张量形状(高度、宽度、深度)。
Stem block代码如下:
class StemBlock(nn.Module):
def __init__(self):
super(StemBlock, self).__init__()
self.conv = ConvBNReLU(3, 16, 3, stride=2)
self.left = nn.Sequential(
ConvBNReLU(16, 8, 1, stride=1, padding=0),
ConvBNReLU(8, 16, 3, stride=2),
)
self.right = nn.MaxPool2d(
kernel_size=3, stride=2, padding=1, ceil_mode=False)
self.fuse = ConvBNReLU(32, 16, 3, stride=1)
def forward(self, x):
feat = self.conv(x)
feat_left = self.left(feat)
feat_right = self.right(feat)
feat = torch.cat([feat_left, feat_right], dim=1)
feat = self.fuse(feat)
return feat
context embedding block代码如下
Gather-and-Expansion Layer
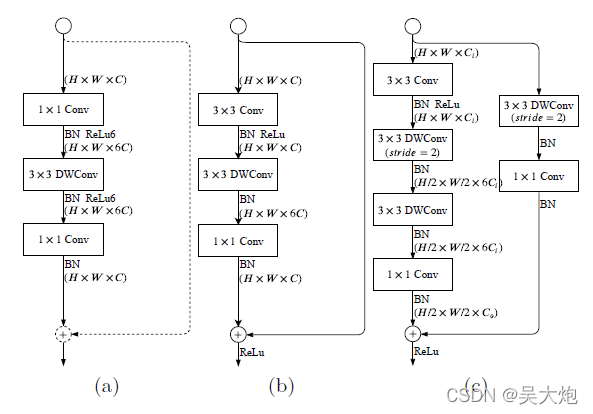
为了充分利用深度可分离卷积提出GE层
图中的(a)为mobilenetv2的结构,(b)、(c)为本文作者提出,看了源码之后,语义分支就是交替使用这两个GE层,
class GELayerS1(nn.Module):
def __init__(self, in_chan, out_chan, exp_ratio=6):
super(GELayerS1, self).__init__()
mid_chan = in_chan * exp_ratio
self.conv1 = ConvBNReLU(in_chan, in_chan, 3, stride=1)
self.dwconv = nn.Sequential(
nn.Conv2d(
in_chan, mid_chan, kernel_size=3, stride=1,
padding=1, groups=in_chan, bias=False),
nn.BatchNorm2d(mid_chan),
nn.ReLU(inplace=True), # not shown in paper
)
self.conv2 = nn.Sequential(
nn.Conv2d(
mid_chan, out_chan, kernel_size=1, stride=1,
padding=0, bias=False),
nn.BatchNorm2d(out_chan),
)
self.conv2[1].last_bn = True
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
feat = self.conv1(x)
feat = self.dwconv(feat)
feat = self.conv2(feat)
feat = feat + x
feat = self.relu(feat)
return feat
从代码中发现,GELayerS1结构为(b)中的结构,先经过一个3×3的conv,然后一个dwconv 再接一个1×1的conv,跳连相加
class GELayerS2(nn.Module):
def __init__(self, in_chan, out_chan, exp_ratio=6):
super(GELayerS2, self).__init__()
mid_chan = in_chan * exp_ratio
self.conv1 = ConvBNReLU(in_chan, in_chan, 3, stride=1)
self.dwconv1 = nn.Sequential(
nn.Conv2d(
in_chan, mid_chan, kernel_size=3, stride=2,
padding=1, groups=in_chan, bias=False),
nn.BatchNorm2d(mid_chan),
)
self.dwconv2 = nn.Sequential(
nn.Conv2d(
mid_chan, mid_chan, kernel_size=3, stride=1,
padding=1, groups=mid_chan, bias=False),
nn.BatchNorm2d(mid_chan),
nn.ReLU(inplace=True), # not shown in paper
)
self.conv2 = nn.Sequential(
nn.Conv2d(
mid_chan, out_chan, kernel_size=1, stride=1,
padding=0, bias=False),
nn.BatchNorm2d(out_chan),
)
self.conv2[1].last_bn = True
self.shortcut = nn.Sequential(
nn.Conv2d(
in_chan, in_chan, kernel_size=3, stride=2,
padding=1, groups=in_chan, bias=False),
nn.BatchNorm2d(in_chan),
nn.Conv2d(
in_chan, out_chan, kernel_size=1, stride=1,
padding=0, bias=False),
nn.BatchNorm2d(out_chan),
)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
feat = self.conv1(x)
feat = self.dwconv1(feat)
feat = self.dwconv2(feat)
feat = self.conv2(feat)
shortcut = self.shortcut(x)
feat = feat + shortcut
feat = self.relu(feat)
return feat
GELayerS2就是图中的(c),代码写的很清楚,这里不再赘述。
语义分支源码
class SegmentBranch(nn.Module):
def __init__(self):
super(SegmentBranch, self).__init__()
self.S1S2 = StemBlock()
self.S3 = nn.Sequential(
GELayerS2(16, 32),
GELayerS1(32, 32),
)
self.S4 = nn.Sequential(
GELayerS2(32, 64),
GELayerS1(64, 64),
)
self.S5_4 = nn.Sequential(
GELayerS2(64, 128),
GELayerS1(128, 128),
GELayerS1(128, 128),
GELayerS1(128, 128),
)
self.S5_5 = CEBlock()
def forward(self, x):
feat2 = self.S1S2(x)
feat3 = self.S3(feat2)
feat4 = self.S4(feat3)
feat5_4 = self.S5_4(feat4)
feat5_5 = self.S5_5(feat5_4)
return feat2, feat3, feat4, feat5_4, feat5_5
语义分支为了提取深层次的语义信息,对图像进行较大倍的下采样,BisenetV2的语义分支部分先经过stemblock,然后由GElayerS1和GElayerS2交叉堆叠而成,返回中间特征,作为辅助分类
Bilateral Guided Aggregation 主要用于将前两个分支进行融合,
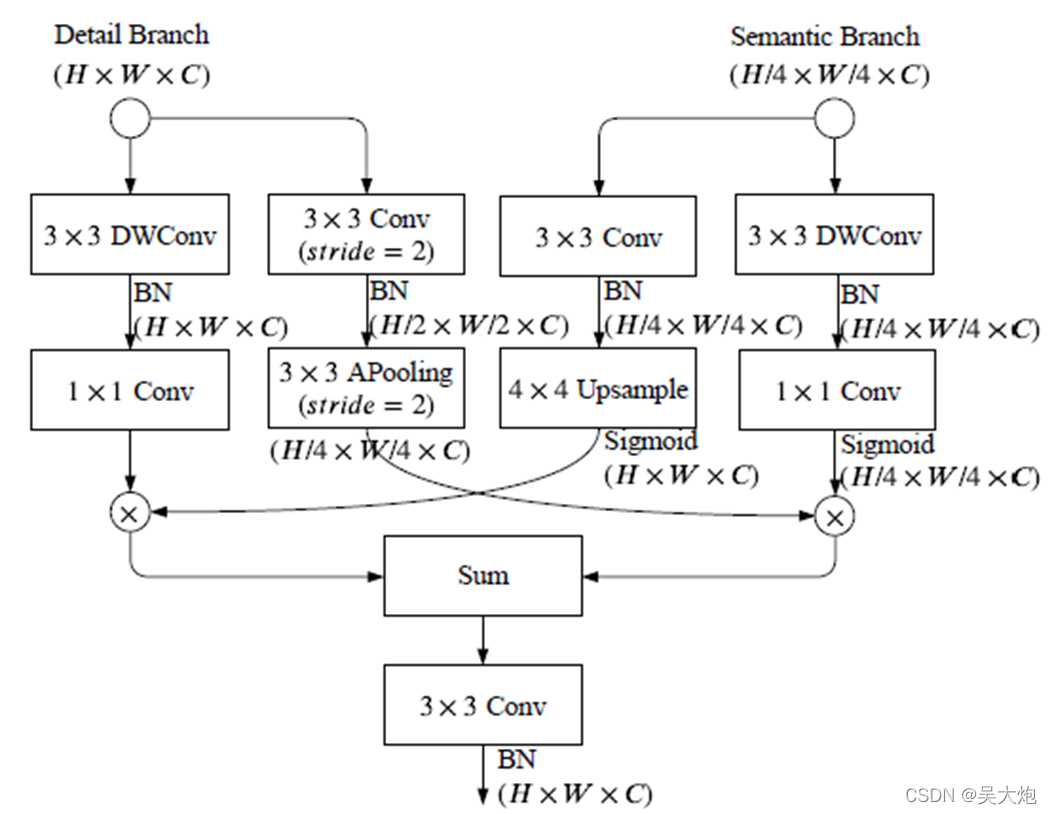
该结构代码如下:
class BGALayer(nn.Module):
def __init__(self):
super(BGALayer, self).__init__()
self.left1 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, groups=128, bias=False),
nn.BatchNorm2d(128),
nn.Conv2d(
128, 128, kernel_size=1, stride=1,
padding=0, bias=False),
)
self.left2 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=2,
padding=1, bias=False),
nn.BatchNorm2d(128),
nn.AvgPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False)
)
self.right1 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, bias=False),
nn.BatchNorm2d(128),
)
self.right2 = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, groups=128, bias=False),
nn.BatchNorm2d(128),
nn.Conv2d(
128, 128, kernel_size=1, stride=1,
padding=0, bias=False),
)
##TODO: does this really has no relu?
self.conv = nn.Sequential(
nn.Conv2d(
128, 128, kernel_size=3, stride=1,
padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True), # not shown in paper
)
def forward(self, x_d, x_s):
dsize = x_d.size()[2:]
left1 = self.left1(x_d)
left2 = self.left2(x_d)
right1 = self.right1(x_s)
right2 = self.right2(x_s)
right1 = F.interpolate(
right1, size=dsize, mode='bilinear', align_corners=True)
left = left1 * torch.sigmoid(right1)
right = left2 * torch.sigmoid(right2)
right = F.interpolate(
right, size=dsize, mode='bilinear', align_corners=True)
out = self.conv(left + right)
return out
最后的这个融合结构设计也是很巧妙,我都不理解这是怎么设计出来的。
下面给出整个网络模型的代码
class BiSeNetV2(nn.Module):
def __init__(self, n_classes):
super(BiSeNetV2, self).__init__()
self.detail = DetailBranch()
self.segment = SegmentBranch()
self.bga = BGALayer()
## TODO: what is the number of mid chan ?
self.head = SegmentHead(128, 1024, n_classes)
self.aux2 = SegmentHead(16, 128, n_classes)
self.aux3 = SegmentHead(32, 128, n_classes)
self.aux4 = SegmentHead(64, 128, n_classes)
self.aux5_4 = SegmentHead(128, 128, n_classes)
self.init_weights()
def forward(self, x):
size = x.size()[2:]
feat_d = self.detail(x)
feat2, feat3, feat4, feat5_4, feat_s = self.segment(x)
feat_head = self.bga(feat_d, feat_s)
logits = self.head(feat_head, size)
logits_aux2 = self.aux2(feat2, size)
logits_aux3 = self.aux3(feat3, size)
logits_aux4 = self.aux4(feat4, size)
logits_aux5_4 = self.aux5_4(feat5_4, size)
return logits, logits_aux2, logits_aux3, logits_aux4, logits_aux5_4
def init_weights(self):
for name, module in self.named_modules():
if isinstance(module, (nn.Conv2d, nn.Linear)):
nn.init.kaiming_normal_(module.weight, mode='fan_out')
if not module.bias is None: nn.init.constant_(module.bias, 0)
elif isinstance(module, nn.modules.batchnorm._BatchNorm):
if hasattr(module, 'last_bn') and module.last_bn:
nn.init.zeros_(module.weight)
else:
nn.init.ones_(module.weight)
nn.init.zeros_(module.bias)

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









