







paper:Knowledge distillation: A good teacher is patient and consistent
official implementation:https://github.com/google-research/big_vision
本文的创新点
本文没有提出新的方法,而是提出了一些影响蒸馏性能的关键因素,这些因素在之前的蒸馏方法中常常被忽略,本文通过实验验证,指出正确的选择这些因素,可以大大提高现有蒸馏方法的性能。
首先,本文将知识蒸馏当做教师和学生之间的函数匹配,并发现了两个原则,一是教师和学生应该处理相同的输入,即相同的crop和数据增强;二是希望可以在大量的support points上进行函数匹配,从而具有更好的泛化性。
最后通过大量实验验证,作者指出一致的图像视图、更强的数据增强、非常长的迭代次数是实践中通过知识蒸馏进行模型压缩发挥良好作用的关键。
实验验证
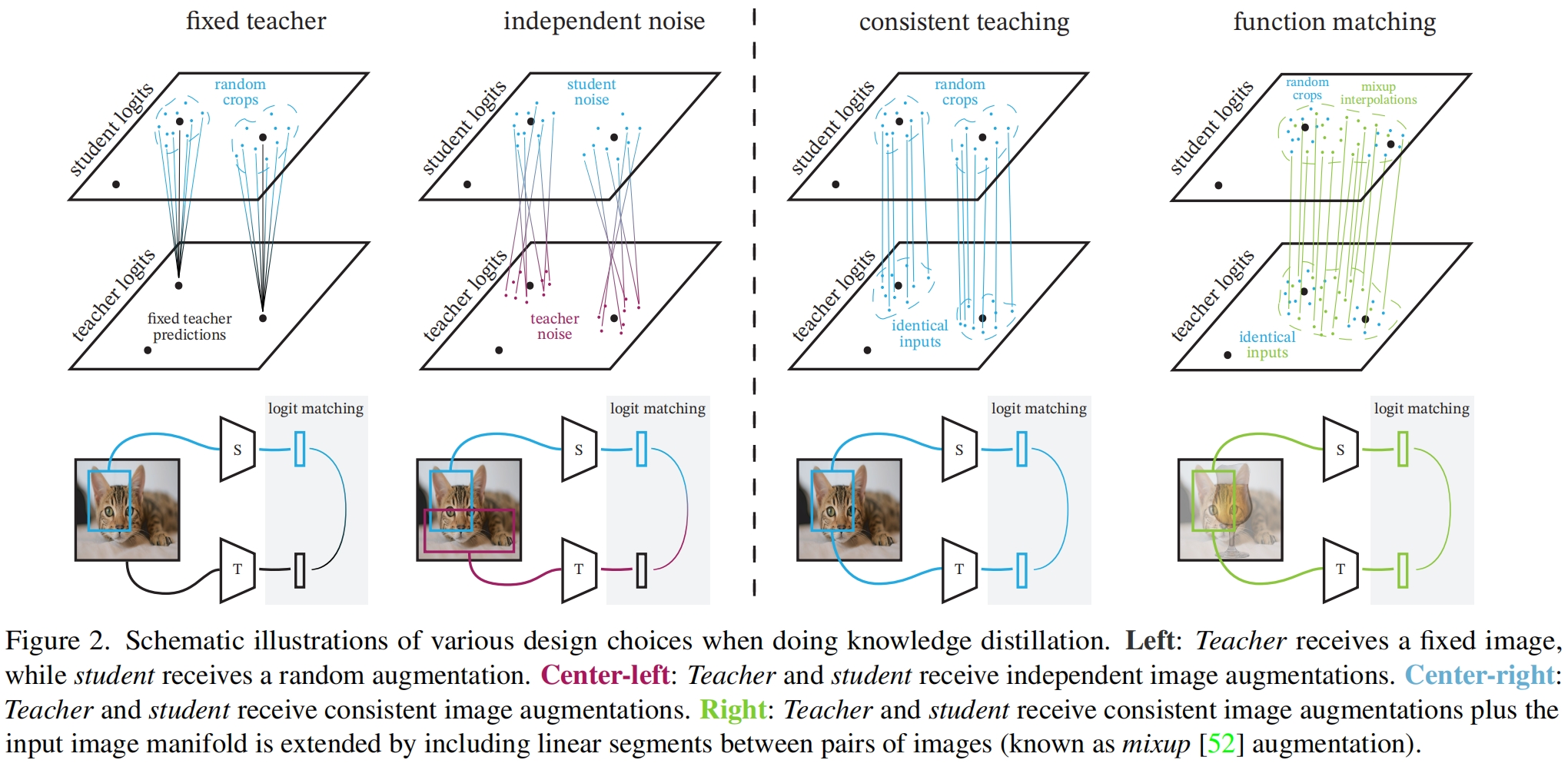
Investigating the "consistent and patient teacher" hypothesis
作者首先通过实验验证观点:当视为函数匹配时,蒸馏的效果是最好的。即当教师和学生的输入视图一致,通过相同的方式进行mix-up填充,并训练非常长的迭代次数,如图2所示。
Importance of "consistent" teaching
首先如图2所示,对于输入视图,作者采用了四种不同的方法:
- Fixed teacher. 固定教师的输入,即在蒸馏过程中对于同一张图片教师的输入是固定不变的。具体又包括几种不同的方式,首先是fix/rs,即教师和学生的输入都统一resize成224x224。然后是fix/cc,即教师采用固定的center crop,而学生采用random crop。最后是fix/ic_ens,即教师的预测是1000个crop预测的平均值。
- Independent noise. 分为两种,ind/rc 教师和学生分别采用random crop,ind/ic 采用更强的inception crop
- Consistent teaching. 这里只对图片进行一次随机剪裁,random crop(same/rc)或 inception crop(same/ic)都可以,然后作为教师和学生的输入。
- Function matching. 这里扩展了consistent teaching,通过mix-up对图片进行增强,然后分别输入教师和学生网络。
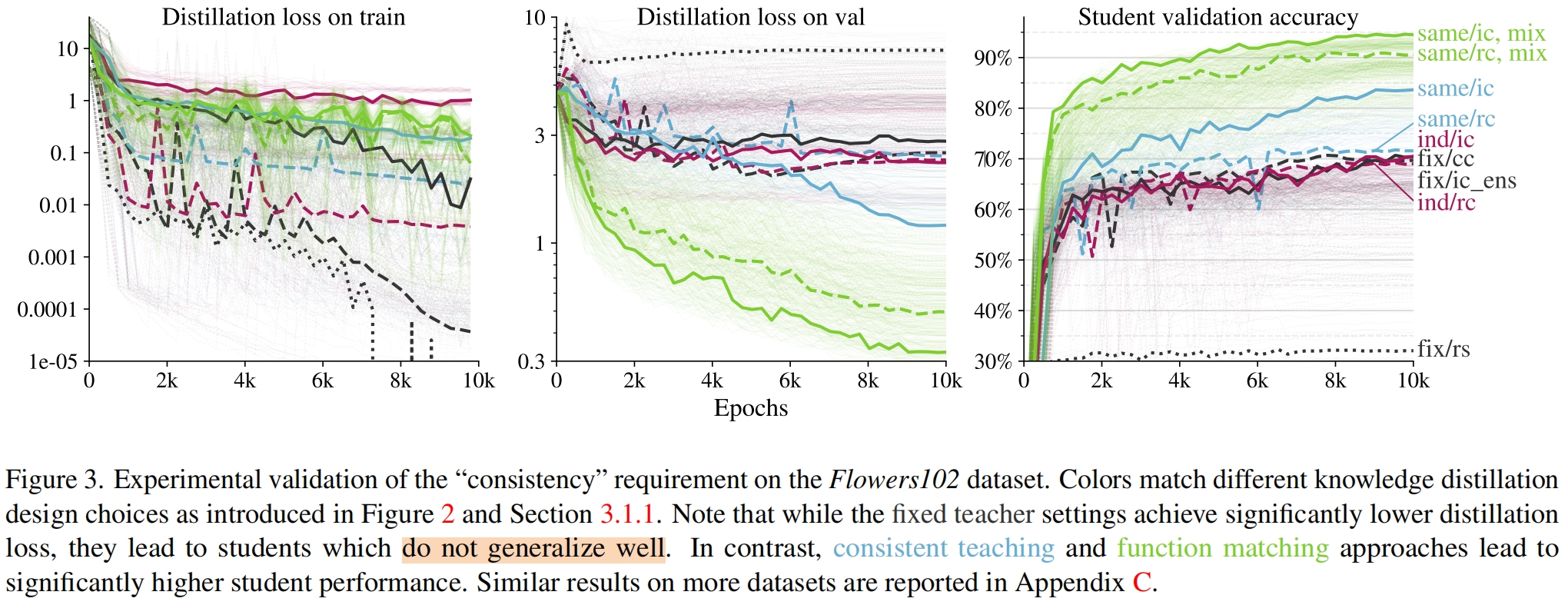
图3是在Flowers102数据集上上述各种配置10000个epoch的训练曲线,可以看出consistency是关键因素,所有inconsistent的配置最终的性能都更差。此外通过训练损失可以看出,对于这种小数据集,fixed teacher的设置会导致过拟合,相反函数匹配在训练集上的损失达不到这么低,但泛化性能好,在验证集上的精度更高。
Importance of "patient" teaching
我们可以把蒸馏当做监督学习的一种变体,其中标签Labels(soft)时由一个更强的教师模型提供的,同时也继承了监督学习的所有问题,比如过强的数据增强可能会扭曲实际的标签,而过弱的数据增强可能会导致过拟合。但当我们把蒸馏视作函数匹配,并且更重要的是确保教师和学生的输入一致,情况就不一样了。此时我们可以使用非常强的数据增强,即使输入图像被扭曲的非常厉害,对于这个输入进行函数匹配仍能取得很好的效果。这样我们就可以使用非常强的数据增强来避免过拟合,并优化非常久的时间知道学生的函数非常接近教师的函数。
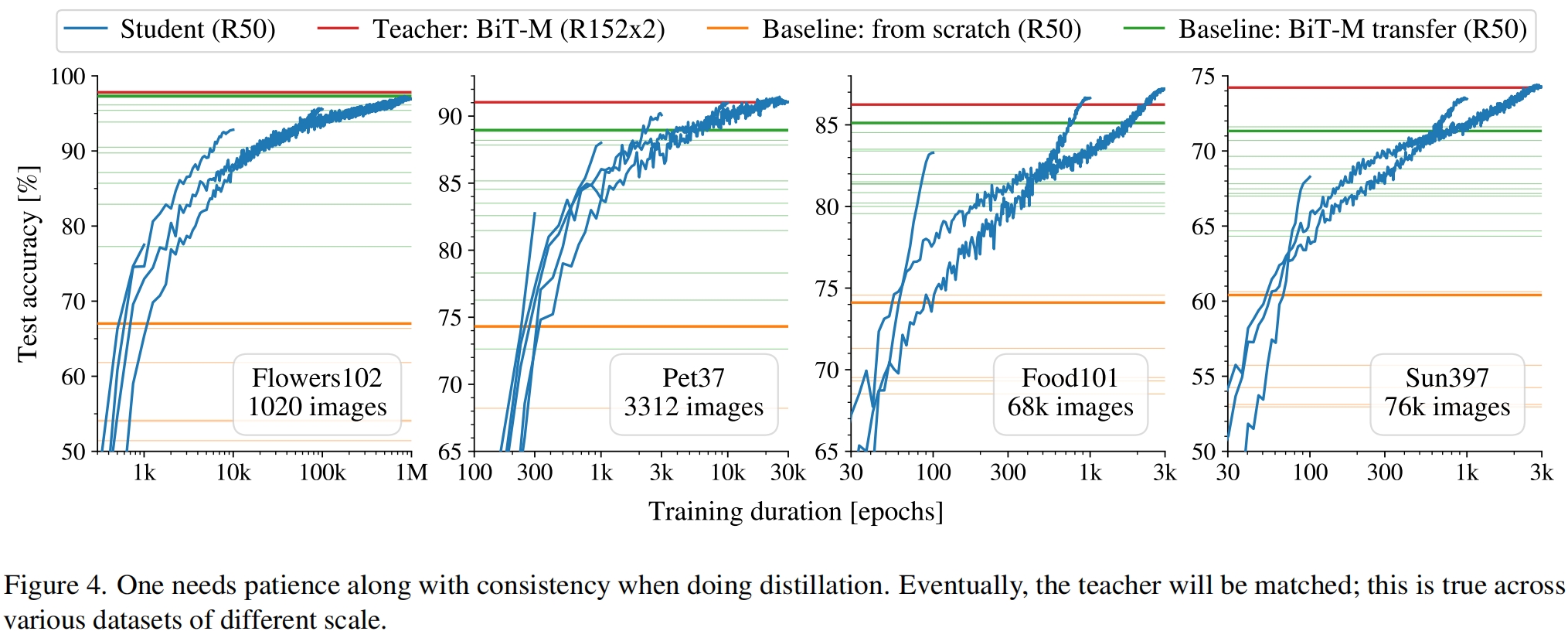
结果验证了作者的直觉如图4所示,其中展示了对每个数据集,在训练最佳funtion matching student(根据验证集)时测试精度的变化。其中教师是红线,在监督训练足够大的epoch后总是能到达。更重要的是即使训练了一百万个epoch,也没有过拟合。
结论
本文没有提出一种新的模型压缩方法,而是仔细研究了现有的常用的知识蒸馏过程,并确定如何使它在模型压缩中更有效。其中关键发现源于对知识蒸馏的一种特定解释:本文提出将其视为一个函数匹配任务。这不是常见的观点,因为它通常被视为“一个强大的教师模型产生更好的(软的)标签,有利于训练一个更好的、更小的学生模型”。
基于这种解释,本文确定了三个关键要素: (i)确保教师和学生总是得到相同的输入,包括噪声,(ii)引入积极的数据扩充,以丰富输入(通过mix-up),(iii)使用非常长的训练schedule。尽管每个要素看起来微不足道,但本文通过实验表明,同时应用三个要素可以得到最好的结果。















 1233
1233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











