







在Transformer in Transformer这篇文章中有一节内容是复杂度分析,关于TNT的介绍见Transformer iN Transformer(NeurIPS 2021)原理与代码解析-CSDN博客
这里先讲一下原文内容,然后再对计算细节展开一下 ,原文部分如下:
self-attention的输入 \(X\in \mathbb{R}^{n\times d}\) 首先线性转换为三个部分,即queries \(Q\in \mathbb{R}^{n\times d_k}\)、keys \(K\in \mathbb{R}^{n\times d_k}\)、values \(V\in \mathbb{R}^{n\times d_v}\),其中 \(n\) 是sequence length,\(d,d_k,d_v\) 分别是输入、queries(keys)和values的维度。则attention按下式计算
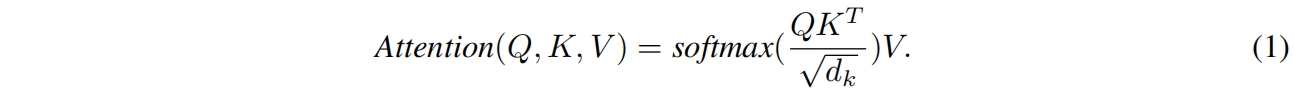
一个标准的transformer block包括两部分,即multi-head self-attention和MLP。MSA的FLOPs为 \(2nd(d_k+d_v)+n^2(d_k+d_v)\),MLP的FLOPs为 \(2nd_vrd_v\),其中 \(r\) 是MLP隐藏层维度的expansion ratio。总得来说,一个标准transformer block的FLOPs为
![]()
由于 \(r\) 通常设置为4,并且输入、key(query)和value的维度通常设置为相同的,则FLOPs的计算可以简化为
![]()
参数量为
![]()
TNT block包含三个部分:一个inner transformer block \(T_{in}\),一个outer transformer block \(T_{out}\) 和一个线性层。\(T_{in}\) 和 \(T_{out}\) 的计算复杂度分别为 \(2nmc(6c+m)\) 和 \(2nd(6d+n)\)。线性层的FLOPs为 \(nmcd\)。总的来说,TNT block的FLOPs为
![]()
同样,TNT block的参数量为
![]()
尽管我们在TNT block中又添加了两个组件,FLOPs的增加非常小因为 \(c\ll d\) 并且 \(\mathcal{O}(m)\approx \mathcal{O}(n)\)。例如在DeiT-S中,我们有 \(d=384,n=196\)。而在对应的TNT-S中,我们设置 \(c=24,m=16\)。从式(15)和式(17)我们可以得到 \(FLOP_{S_{T}}=376M,FLOP_{S_{TNT}}=429M\)。TNT block的FLOPs是标准transformer block的1.14倍。同样参数量的比例约为1.08倍。随着计算和内存成本的小幅增加,TNT block可以有效地建模局部结构信息并在精度和复杂度之间实现更好的平衡。
以上是TNT原文中对TNT block和标准transformer block计算量和参数量进行对比部分的阐述。接下来我们对其中的计算过程再进一步展开,把细节讲清楚方便大家理解。
输入 \(X\in \mathbb{R}^{n\times d}\),其中 \(n\) 是sequence length,\(d\) 是feature dim。
输入 \(X\) 分别与矩阵 \(W_Q\in \mathbb{R}^{d\times d_k}, W_K\in \mathbb{R}^{d\times d_k}, W_V\in \mathbb{R}^{d\times d_v}\) 相乘线性变换得到 \(Q\in \mathbb{R}^{n\times d_k}, K\in \mathbb{R}^{n\times d_k}, V\in \mathbb{R}^{n\times d_v}\)。
这一步的计算量为 \(ndd_k+ndd_k+ndd_v\),参数量为 \(dd_k+dd_k+dd_v\)。
第二步是计算注意力 \(attention=softmax(\frac{q\cdot k^T}{\sqrt{d_k}})v\),结果 \(attention\in\mathbb{R}^{n\times d_v}\),这一步计算量为 \(nd_kn+nd_vn\),参数量为0。
最后还有一层线性映射层,权重矩阵 \(W\in \mathbb{R}^{d_v\times d}\),这一步计算量为 \(nd_vd\),参数量为 \(dd_v\)。
最后总计算量三者相加 \((ndd_k+ndd_k+ndd_v)+(nd_kn+nd_vn)+nd_vd=2nd(d_k+d_v)+n^2(d_k+d_v)\) 就是式(14)的前两部分。
总参数量为 \((dd_k+dd_k+dd_v)+dd_v\)。
然后是MLP包含两个全连接层,输入的维度为 \(\mathbb{R}^{n\times d}\),第一层的dimension expansion ratio \(r\) 一般为4,则计算量为 \(nddr+nddr=2nddr\),参数量为 \(ddr+ddr=2ddr\)。将MLP的FLOPs和上述attention的FLOPs相加,即得到了完整的式(14)
一般情况下 \(d_q=d_k=d_v=d,r=4\)
则式(14)的总计算量为 \(2nd\times 2d+n^2\times 2d+2nd^2\times 4=4nd^2+2n^2d+8nd^2\),即 \(12nd^2+2n^2d=2nd(6d+n)\) 就是式(15)
而参数量为 \((dd_k+dd_k+dd_v)+(dd_v)+(2ddr)=12dd\) 就是式(16)。
以上就是标准transformer block的FLOPs和参数量的计算过程。
而TNT是由inner transformer block、outer transformer block和一个线性层构成,transformer block可以直接套用公式(15)(16),外层的计算量和参数量不变就是(15)(16)式。内层block的sequence length用 \(m\) 替换 \(n\),特征维度用 \(c\) 替换 \(d\) 分别带入式(15)(16)就得到了 \(2mc(6c+m)\) 和 \(12cc\),注意前者还要乘以 \(n\) 因为外层的每个patch都由内层的 \(m\) 个patch组成,或者可以理解成外层的每个句子都由内层的 \(m\) 个单词组成而外层一共有 \(n\) 个patch或句子,所以要乘以 \(n\),这样就得到了式(17)的第一项。
TNT中还有一个线性层,这里的线性层是为了将内层的embedding映射为外层的embedding,即代码
patch_embed = self.norm2_proj(self.proj(self.norm1_proj(pixel_embed.reshape(B, self.num_patches, -1))))中的self.proj,它的定义如下
self.proj = nn.Linear(num_pixel * inner_dim, embed_dim) # 16x24=384, 384因此它的参数量为 \(mcd\),计算量为 \(nmcd\),加上这两个就得到了完整的(17)(18)式。
















 984
984

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











