









paper:Separable Self-attention for Mobile Vision Transformers
official implementation:https://github.com/apple/ml-cvnets
third-party implementation:https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/mobilevit.py
存在的问题
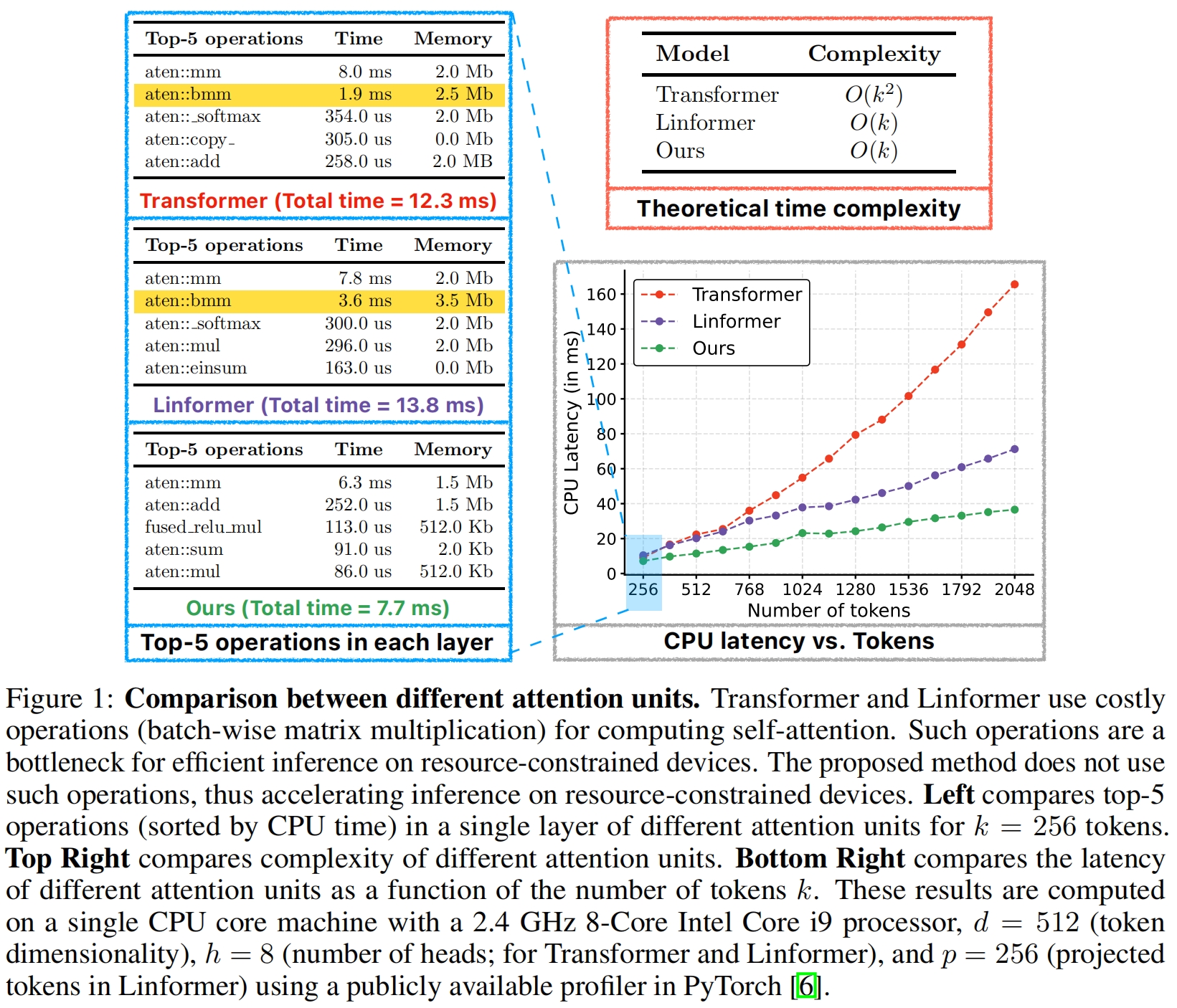
MobileViT在多个移动视觉任务中取得了SOTA的性能,虽然其参数较少,但和基于卷积的网络相比,延迟较高。MobileViT的主要效率瓶颈在于Transformer中的multi-head self-attention,它需要 \(O(k^2)\) 的时间复杂度(\(k\) 是token或patch的数量)。此外,MHA需要昂贵的操作比如batch-wise matrix mulplication来计算self-attention,从而影响资源受限设备上的延迟。
创新点
针对多头注意力高延迟和高计算成本的问题,本文提出了一种新的分离自注意力机制,通过逐元素操作计算自注意力,大大减少了计算复杂度和成本,将计算复杂度降至 \(O(k)\),使其更适合在资源受限的设备上运行。
在MobileViT的基础上,结合本文提出的separable self-attention,作者设计了一个新的网络MobileViT v2。通过实验,作者证明了MobileViT v2在多个任务(如ImageNet分类、MS-COCO目标检测、PASCAL VOC分割)上比MobileViT有显著的性能提升。 例如,MobileViTv2在ImageNet数据集上取得了75.6%的Top-1准确率,比MobileViT高出约1%,且在移动设备上的运行速度快了3.2倍。
方法介绍
分离自注意力和MHA类似,输入 \(\mathbf{x}\) 经过三个分支处理,即input \(\mathcal{I}\)、key \(\mathcal{K}\)、value \(\mathcal{V}\)。输入分支 \(\mathcal{I}\) 用一个权重为 \(W_{\mathbf{I}}\in \mathbb{R}^d\) 的线性层将 \(\mathbf{x}\) 中的每个维度为 \(d\) 的token映射为一个标量。权重 \(W_{\mathbf{I}}\) 作为图4b中的潜在节点latent node \(L\)。这个线性映射是一个内积运算,它计算了潜在节点 \(L\) 和 \(\mathbf{x}\) 之间的距离,得到一个 \(k\) 维的向量(这里的\(k\)是token的数量)。然后这个 \(k\) 维向量通过softmax得到一个上下文得分context score \(\mathbf{c}_{\mathbf{s}}\in \mathbb{R}^k\)。
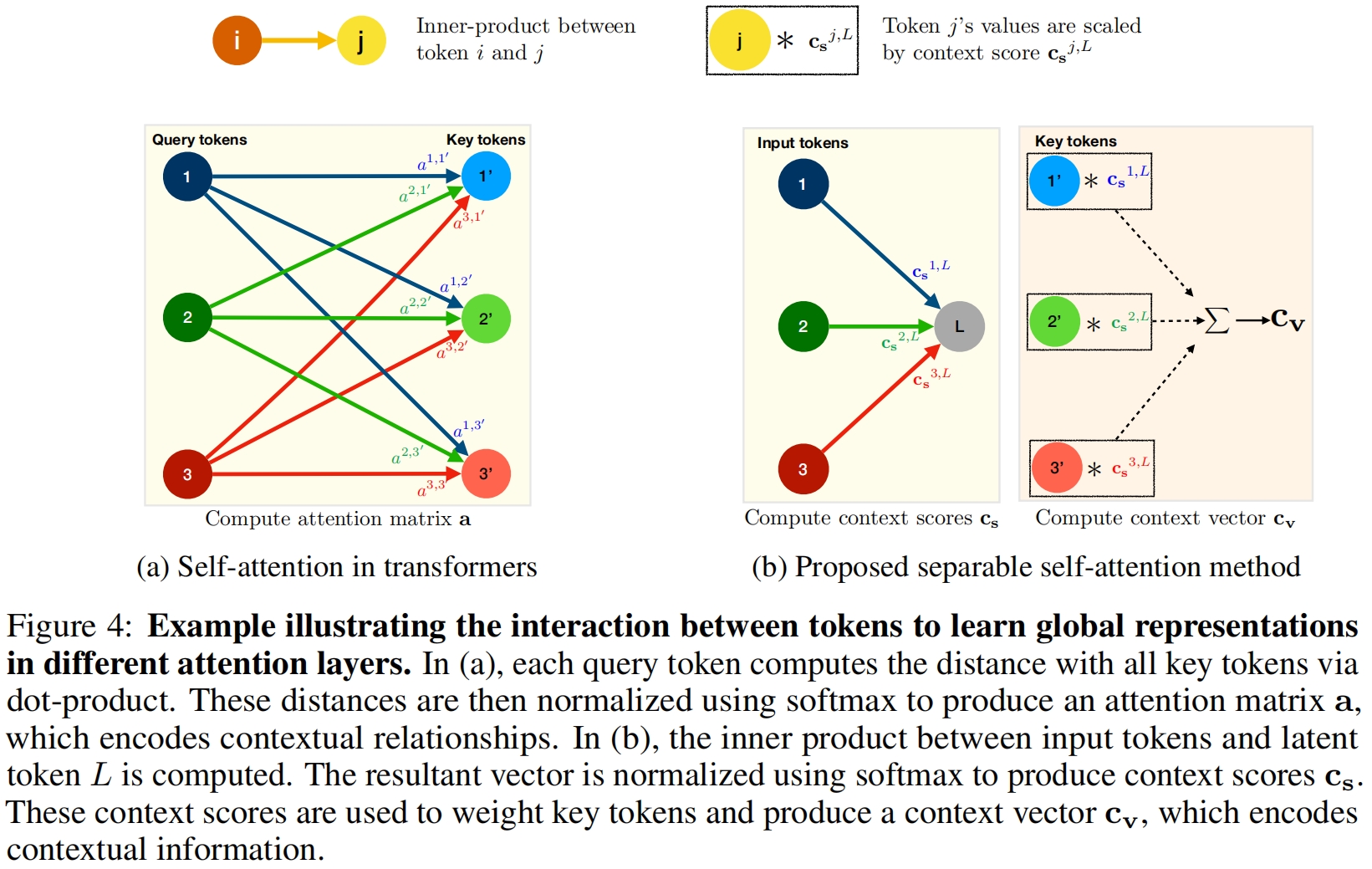
和transformer计算每个token和所有 \(k\) 个tokens之间的attention(或context)得分不同,本文提出的方法只计算和潜在token \(L\) 之间的context score。这将计算attention(或context)得分的成本从 \(O(k^2)\) 降到了 \(O(k)\)。
context score \(\mathbf{c}_{\mathbf{s}}\) 用来计算一个context向量 \(\mathbf{c}_{\mathbf{v}}\)。具体来说,输入 \(\mathbf{x}\) 首先通过权重为 \(\mathbf{W}_{\mathbf{K}}\in \mathbb{R}^{d\times d}\) 的key分支 \(\mathcal{K}\) 线性映射到一个 \(d\) 维空间得到输出 \(\mathbf{x}_{\mathbf{K}}\in \mathbb{R}^{k\times d}\)。然后用 \(\mathbf{c}_{\mathbf{s}}\) 对 \(\mathbf{x}_{\mathbf{K}}\) 加权求和得到context向量 \(\mathbf{c}_{\mathbf{v}}\in \mathbb{R}^d\)
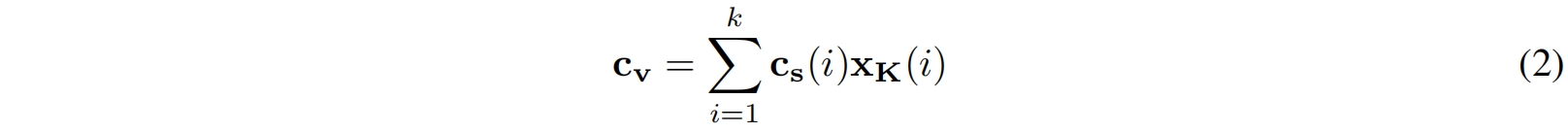
\(\mathbf{x}\) 中的所有token共享 \(\mathbf{c}_{\mathbf{v}}\) 中编码的上下文信息。输入 \(
\mathbf{x}\) 首先通过权重为 \(\mathbf{W}_{\mathbf{V}}\in \mathbb{R}^{d\times d}\) 的value分支 \(\mathcal{V}\) 线性映射到一个 \(d\) 维空间,然后接上一个ReLU激活得到输出 \(\mathbf{x}_{\mathbf{V}}\in \mathbb{R}^{k\times d}\)。\(\mathbf{c}_{\mathbf{v}}\) 中的上下文信息通过broadcasted element-wise相乘操作传播到 \(\mathbf{x}_{\mathbf{V}}\) 中。得到的输出经过另外一个权重为 \(\mathbf{W}_{\mathbf{O}}\in \mathbb{R}^{d\times d}\) 的线性层得到最终的输出 \(\mathbf{y}\in \mathbb{R}^{k\times d}\)。分离自注意力的完整公式如下
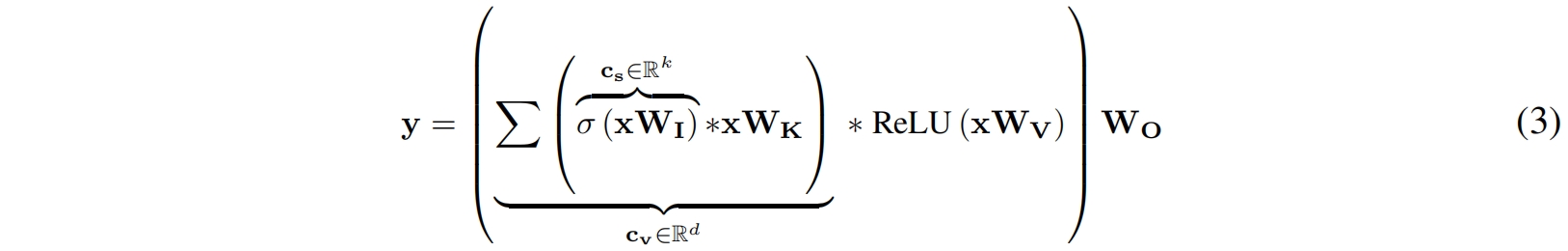
其中 \(*\) 和 \(\sum \) 分别是broadcastable element-wise的相乘和相加操作。
图1将分离自注意力与Transformer和Linformer进行了比较。由于self-attention的时间复杂度没有考虑用于实现这些方法的操作的成本,一些操作可能成为资源受限设备的瓶颈。为了整理理解,除了理论指标外,还测了单个CPU核心上不同 \(k\) 值的模块级延迟。与Transformer和Linformer中的MHA相比,本文提出的分离自注意力快速又高效。
实验结果
作者用分离自注意力替换MobileViT中的MHA得到了MobileViT v2,此外作者还去掉了MobileViT block中的skip-connection和fusion block因为它们对性能的提升很小。和MobileViT设计了XXS、XS、S三种架构不同 ,MobileViT v2采用了一个宽度缩放因子 \(\alpha\in \{0.5,2.0\}\) 来对模型均匀的缩放得到一系列的网络。
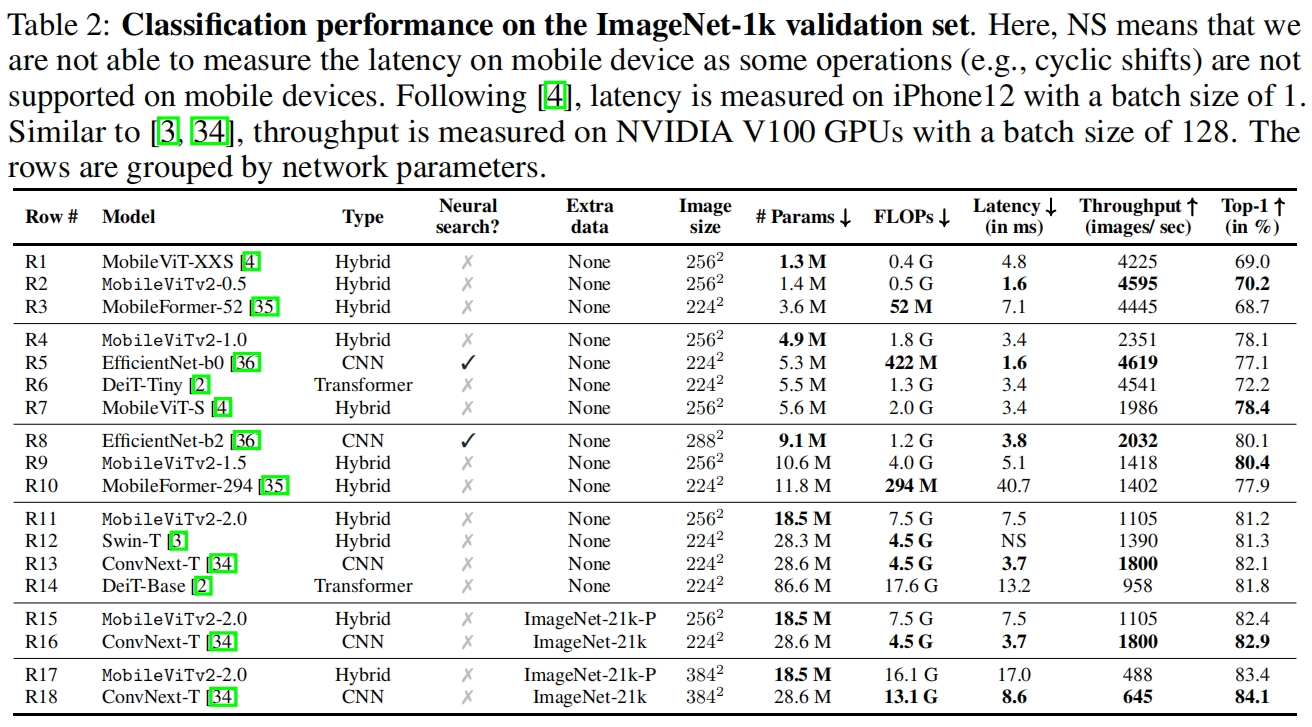
和其它模型在ImageNet上的分类结果如表2所示,可以看到相比于MobileViT v1,v2在相似的参数和下延迟大大降低,例如MobileViTv2-0.5和MobileViT-XXS相比,延迟下降了2/3,精度提高了1.2%。
代码解析
这里是timm中的实现。输入大小为(1, 3, 224, 224),模型选择"mobilevitv2_100"即mobilevitv2-1.0。分离自注意力的实现在类LinearSelfAttention中,我们来看forward函数,代码如下。
输入shape=(1, 128, 4, 256),分别表示batch_size、channel、patch_area、patch_num(token_num)。这里和v1中一样采用2x2的patch大小。接下来是self.qkv_proj就是上面提到的 \(\mathcal{I},\mathcal{K},\mathcal{V}\) 分支,输出通道数是2*embed_dim+1,split后分别得到query、key、value,对query取softmax就得到了 \(\mathbf{c}_{\mathbf{s}}\),key和value分别对应上文的 \(\mathbf{x}_{\mathbf{K}},\mathbf{x}_{\mathbf{V}}\)。24行的加权求和对应上文的式(2)得到 \(\mathbf{c}_{\mathbf{v}}\),最后对 \(\mathbf{x}_{\mathbf{V}}\) 取ReLU并与 \(\mathbf{c}_{\mathbf{v}}\) 乘对应式(3)得到最终的输出。
self.qkv_proj = nn.Conv2d(
in_channels=embed_dim,
out_channels=1 + (2 * embed_dim),
bias=bias,
kernel_size=1,
)
def _forward_self_attn(self, x: torch.Tensor) -> torch.Tensor:
# (1,128,4,256)
# [B, C, P, N] --> [B, h + 2d, P, N]
qkv = self.qkv_proj(x) # Conv2d(128, 257, kernel_size=(1, 1), stride=(1, 1)), (1,257,4,256)
# Project x into query, key and value
# Query --> [B, 1, P, N]
# value, key --> [B, d, P, N]
query, key, value = qkv.split([1, self.embed_dim, self.embed_dim], dim=1)
# (1,1,4,256),(1,128,4,256),(1,128,4,256)
# apply softmax along N dimension
context_scores = F.softmax(query, dim=-1) # (1,1,4,256)
context_scores = self.attn_drop(context_scores)
# Compute context vector
# [B, d, P, N] x [B, 1, P, N] -> [B, d, P, N] --> [B, d, P, 1]
context_vector = (key * context_scores).sum(dim=-1, keepdim=True) # (1,128,4,256)->(1,128,4,1)
# combine context vector with values
# [B, d, P, N] * [B, d, P, 1] --> [B, d, P, N]
out = F.relu(value) * context_vector.expand_as(value) # (1,128,4,256)
out = self.out_proj(out) # Conv2d(128, 128, kernel_size=(1, 1), stride=(1, 1)), (1,128,4,256)
out = self.out_drop(out)
return out

















 1396
1396

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











