









official implementation:GitHub - micronDLA/MobileViTv3
出发点
MobileViT v1通过结合CNN和ViT的优势,已经取得了竞争性的结果,但其内部的融合块(fusion block)在模型扩展时存在挑战,并且学习任务复杂。本文提出改进MobileViT v1中的融合块,以解决扩展性和简化学习任务的问题。
创新点
- 改进MobileViT v1 block:提出了四点改进:
(1)fusion block中用1x1卷积代替3x3卷积,简化特征融合任务
(2)local representation block中用depthwise 3x3卷积替换原来的3x3卷积,减少参数和计算量。
(3)fusion block中添加输入特征,形成残差连接,有助于深层模型的优化。
(4)fusion block中融合局部(CNN)和全局(ViT)特征,而不是输入和全局特征。 - 扩展性:改进后的MobileViT v3 block允许模型通过增加宽度(层的通道数)来扩展,创建了新的MobileViTv3-S, XS和XXS架构。
- 性能提升:MobileViT v3在保持类似参数和FLOPs的情况下,相比于MobileViT v1和MobileViT v2,在多个数据集上取得了更高的准确率。
效果
- MobileViTv3-XXS和MobileViTv3-XS在ImageNet-1K数据集上分别超过了MobileViTv1-XXS和MobileViTv1-XS 2%和1.9%。
- 在MobileViTv2的基础上,通过引入提出的融合块,创建了MobileViTv3-0.5, 0.75和1.0模型,这些模型在ImageNet-1k, ADE20K, COCO和PascalVOC2012数据集上的准确率也超过了MobileViTv2。特别是在ImageNet-1K数据集上,MobileViTv3-0.5和MobileViTv3-0.75分别超过了MobileViTv2-0.5和MobileViTv2-0.75 2.1%和1.0%。
- 此外,MobileViTv3-1.0在ADE20K数据集和PascalVOC2012数据集上的分割任务中,相比于MobileViTv2-1.0,mIOU分别提升了2.07%和1.1%。
方法介绍
MobileViT v3相比于MobileViT v1和v2的改进如图2所示。
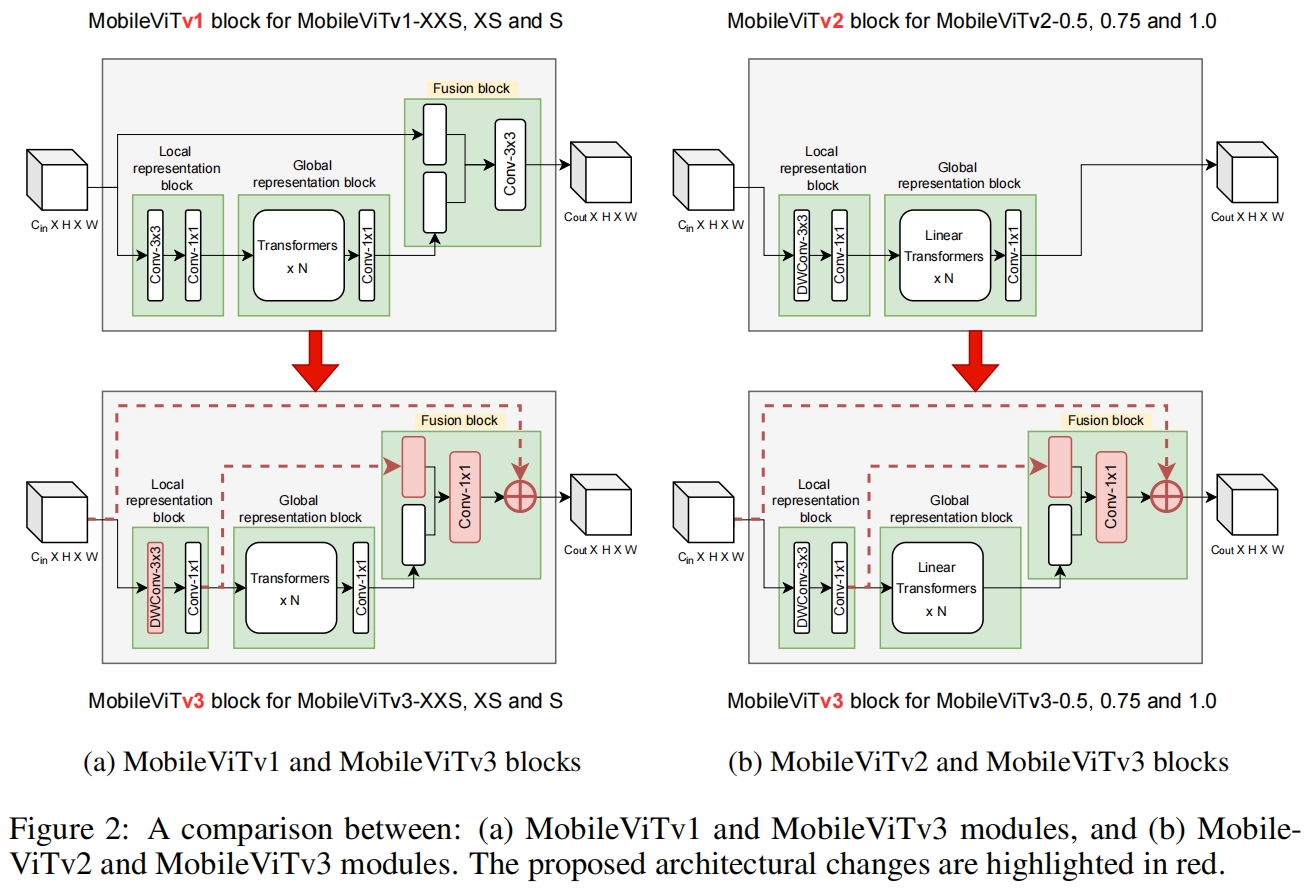
fusion block中用1x1卷积代替3x3卷积:在融合过程中替换3x3卷积主要有两个动机,一是融合独立于特征图中其他位置的局部特征和全局特征,以简化融合块的学习任务。从概念上讲,3x3卷积融合了输入特征、全局特征、其它位置的输入、感受野内的全局特征,这是一个复杂的任务。通过让fusion block只融合独立于其它位置的局部特征和全局特征,可以简化它的学习目标。第二个动机是消除MobileViT v1架构缩放的主要限制之一。将MobileViT v1从XXS扩大到S是通过改变网络的宽度同时保持深度不变来实现的。改变宽度(输入和输出通道数)会导致参数和FLOPs大幅增加。例如,如果MobileViT block的输入和输出通道翻倍,则fusion block中3x3卷积的输入通道将会变成4倍,输出变成2倍,这是因为3x3卷积的输入是输入特征和全局特征的拼接。使用1x1卷积避免了网络扩大时参数和FLOPs的大幅增加。
局部和全局特征融合:在融合层中,MobileViT v3 block将局部特征和全局特征concat到一起,而不是输入特征和全局特征。这是因为与输入特征相比,局部特征与全局特征的联系更为密切。
融合输入特征:输入特征被添加到fusion block中1x1卷积的输出中。这种残差连接在ResNet和DenseNet中已被证明是有助于更深的网络层的优化的。通过将输入特征加到fusion block的输出中,这里也引入了残差连接。
局部特征表示block中的深度卷积:为了进一步减少参数,用depthwise 3x3卷积替换local representation block中的3x3卷积。
实验结果
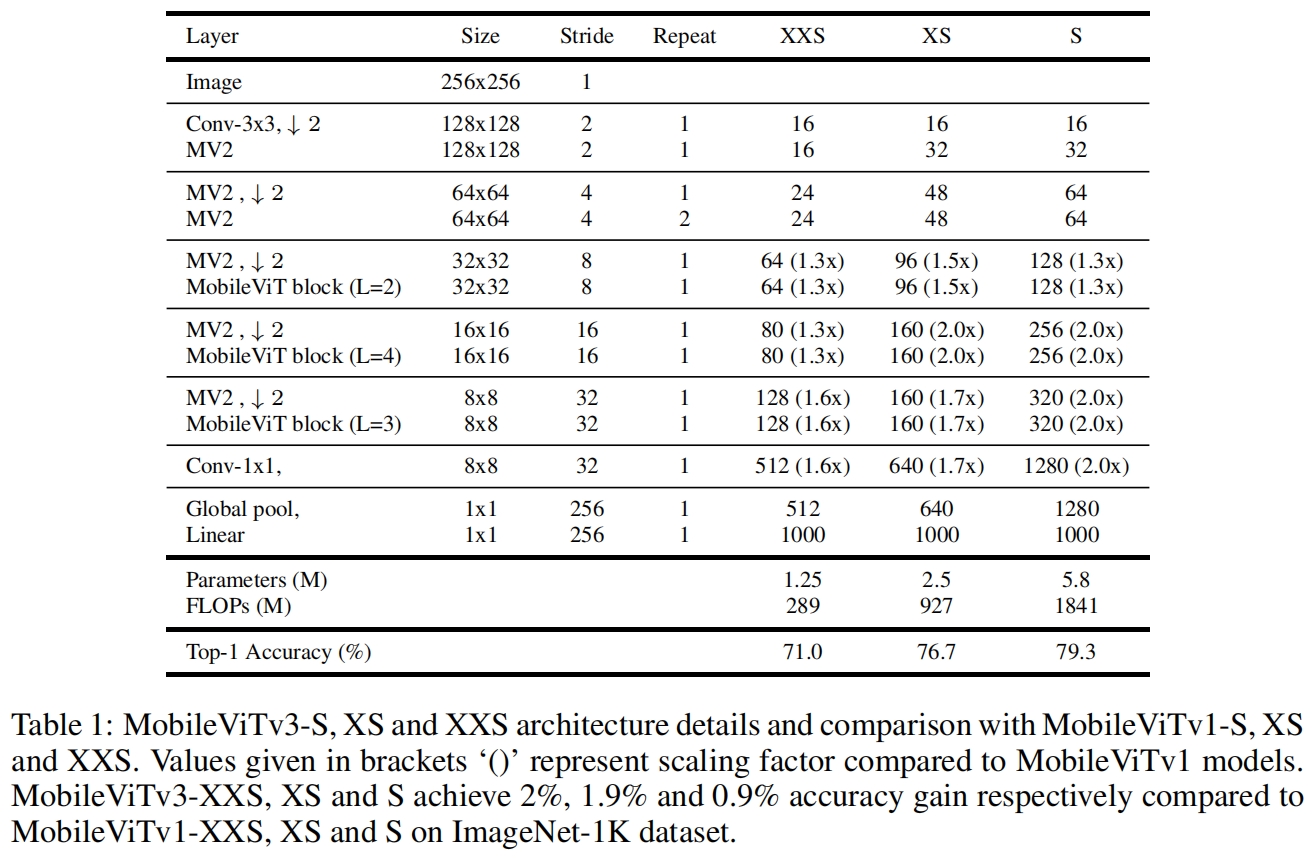
MobileViTv3-S,XS和XXS的配置,括号内是与MobileViTv1对应参数的scaling factor。在ImageNet-1k数据集上,MobileViTv3-XXS、XS和S相比于MobileViTv1-XXS、XS和S分别提升了2%、1.9%、0.9%。
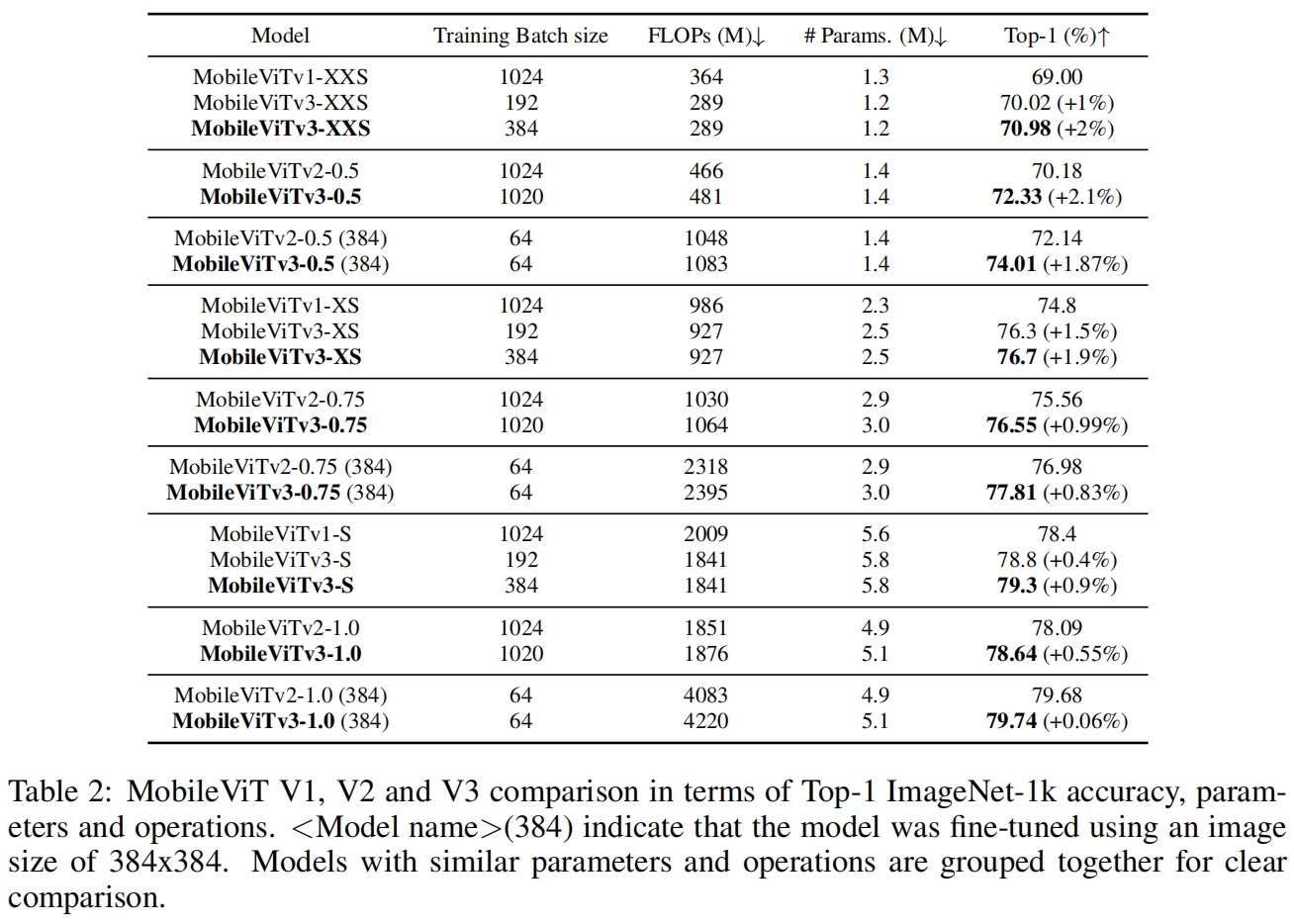
与MobileViT v2类似,作者也设计了MobileViTv3-1.0、0.75、0.5,MobileViTv1、v2、v3的对比如表2所示。可以看到在相似的参数量下,MobileViT v3的性能超过了v1和v2。
















 3518
3518

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











