







paper:Masked Autoencoders Are Scalable Vision Learners
official implementation:https://github.com/facebookresearch/mae
third-party implementation:https://github.com/open-mmlab/mmpretrain/blob/main/mmpretrain/models/selfsup/mae.py
背景
深度学习在计算机视觉领域取得了显著进展,但随着模型规模的增长,对数据的需求也在增加。在自然语言处理(NLP)领域,通过自监督预训练的方法(如BERT和GPT)成功解决了数据需求问题,这些方法通过预测数据中被遮蔽的部分来训练模型。然而,在计算机视觉领域,尽管存在相关研究,自监督学习方法的发展仍然滞后于NLP。
存在的问题
作者首先探索了masked autoencoding在视觉和语言之间的区别。具体如下
- 架构差异:在过去十年中,卷积神经网络(CNN)在计算机视觉领域占主导地位,但这种架构不易整合诸如mask token或position embedding等概念。
- 信息密度差异:语言信号是高度语义化且信息密度高的,而图像信号具有很高的空间冗余性。例如,缺失的图像块可以通过邻近块轻松恢复,导致模型只需低级别的图像统计信息即可完成任务,而不是深入理解图像内容。
- 解码器扮演角色的差异:语言信号是高度语义化且信息密度高的,而图像信号具有很高的空间冗余性。例如,缺失的图像块可以通过邻近块轻松恢复,导致模型只需低级别的图像统计信息即可完成任务,而不是深入理解图像内容。
创新点
- 引入ViT和非对称encoder-decoder架构:对于架构的差异,随着ViT的引入,不再构成障碍。此外,作者设计了一个非对称编码器-解码器架构。编码器只处理可见的图像块(没有掩码标记),而解码器则负责从编码表示和掩码标记中重建原始图像。这种设计解决了CNN架构难以整合掩码标记的问题,并通过轻量级解码器大幅减少了计算量。
- 高比例掩码策略:作者发现, 通过对输入图像进行高比例(如75%)的随机mask,可以显著减少图像的空间冗余性,创建一个更具挑战性的自监督任务,迫使模型学习到更加有用和深入的特征。
- 轻量级解码器设计:解码器仅在预训练阶段用于重建图像,训练完成后,解码器被丢弃,编码器用于识别任务。由于解码器只处理掩码标记和编码表示,其计算负担很小。这种设计使得训练更高效,能够轻松扩展到大规模模型。
方法介绍
本文提出的masked autoencoder(MAE)是一种简单的autoencoder方法,它根据部分观察结果重建原始信号。和所有的autoencoder一样, MAE有一个将观察到的信号映射到一个潜在表示latent representation的编码器,和一个从潜在表示重构原始信号的解码器。和经典的autoencoder不同的是,MAE采用了一种非对称的设计,编码器只作用于部分观察到的信号(没有mask tokens),一个轻量级的解码器从潜在表示和mask tokens重构完整的信号。MAE的整体结构如图1所示
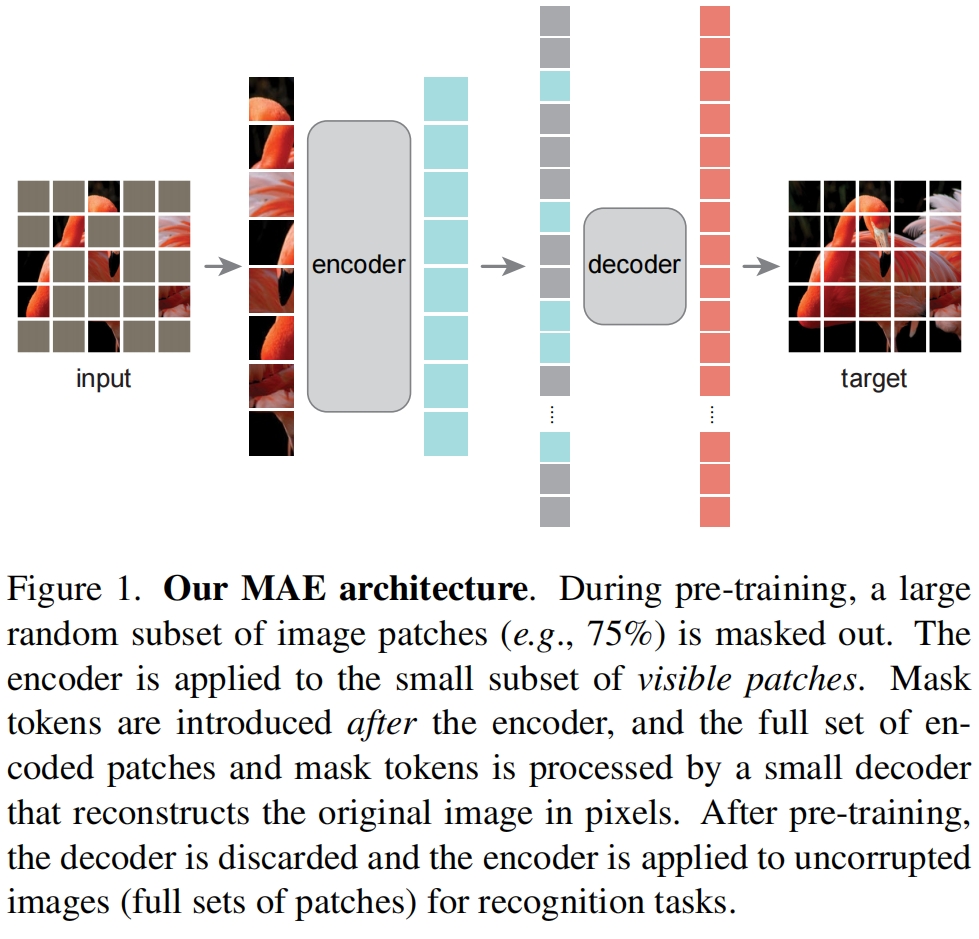
Masking. 和ViT一样,我们将图像分割成规则的不重叠的patch,然后从中采样一部分并mask剩余的部分。采样策略遵循均匀分布,因此称之为“random sampling”。用一个高的mask ratio进行随机采样很大程度上消除了冗余,这样得到的任务不容易通过从可见的相邻patch推测来解决。均匀分布防止了一个center bias即图像中心附近被mask的patch更多。
MAE encoder. 编码器采用了ViT,但只应用于可见的未被mask的patch。和ViT一样,编码器通过一个linear projection来embed patch并添加了位置编码,然后通过一系列的Transformer block进行处理。
MAE decoder. 解码器的输入是完整的token集和包括:1)encoded visible patches 2)mask tokens。每个mask token是一个共享的可学习的向量,表示一个缺失的patch待预测。我们对这个完整集和中的所有token都添加位置编码,如果不这样做,mask token就没有关于它们在原始图片中位置的信息。解码器包含另一系列Transformer block。
MAE decoder只在预训练期间执行图像重建任务(只有编码器用来得到用于下游识别任务的图像表示)。因此解码器的架构可以独立于编码器的架构进行灵活地设计,作者实验中采用了非常小的解码器,比编码器更窄更浅。例如默认的解码器每个token的计算量不到编码器的10%。通过这种不对称的设计,完整的token set只由轻量的解码器来处理,大大减少了预训练的时间。
Reconstruction target. MAE通过预测每个masked patch的像素值来重建输入。解码器的最后一层是一个linear projection,输出的通道数量是一个patch的像素数量。解码器的输出reshape回原始图像的大小,损失函数计算重构图像和原始图像之间的均方误差(MSE),和BERT一样,我们只计算masked patch的损失。
我们还研究了一个变体,它的construction target是每个patch归一化的像素值,具体来说,我们计算每个patch所有像素值的平均值和标准差,并用它们对这个patch进行归一化。在作者的实验中,使用归一化的像素值作为重建目标提升了表示的质量。
实验结果
作者在ImageNet比较了ViT-Large有监督从头训练和MAE finetune的结果,可以看到MAE finetune超越了有监督训练的效果。
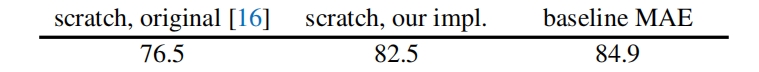
下面是一些消融实验,研究了MAE的架构中各个component对结果的影响。
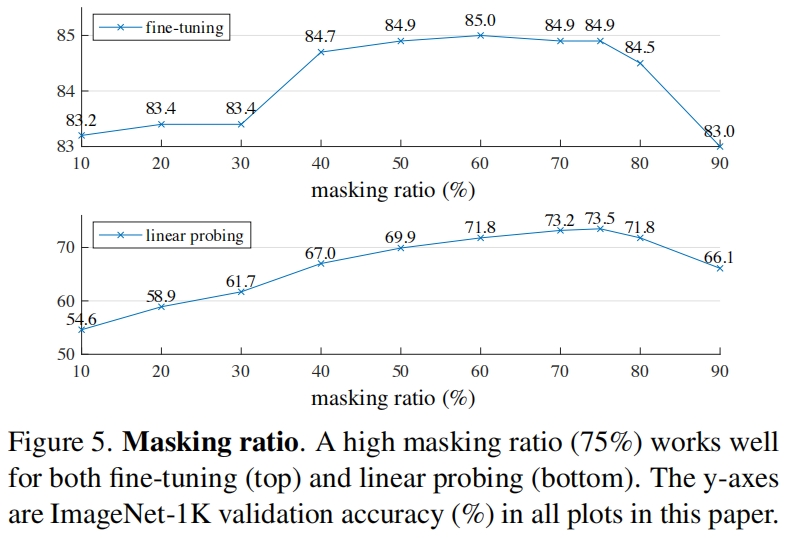
Masking ratio. 图5展示了masking ratio的影响,可以看到最优的ratio相当的高,其中75%同时有利于linear probing和finetune。这和BERT相反,其中最优的ratio为15%。
Decoder design. 解码器的设计如表1(a)(b)所示,可以看到一个足够深的decoder对于linear probing很重要,这可以用像素重建任务和识别任务之间的区别来解释:autoencoder的最后几层更专注于reconstruction,而与识别任务的相关性较低。图1(b)表明更窄的decoder就可以获得很好的finetune性能了。
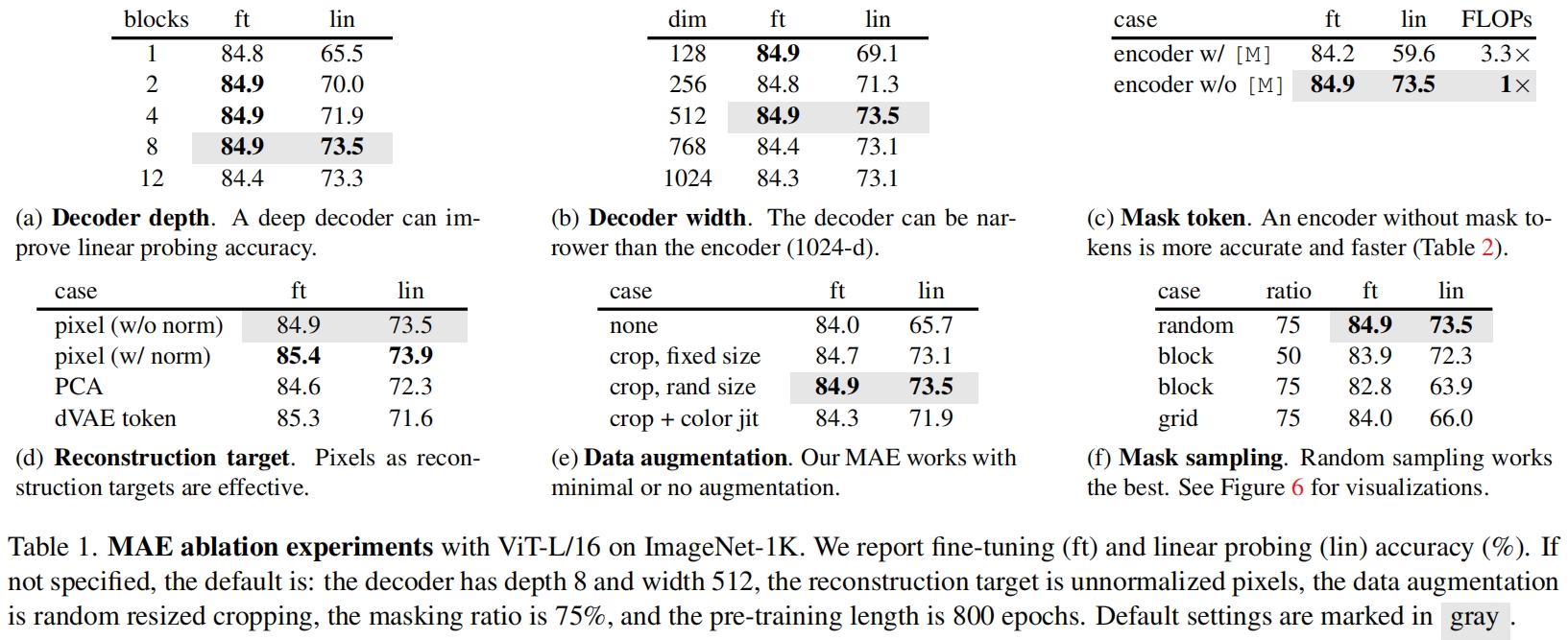
Mask token. MAE的一个重要设计是encoder部分跳过mask token,只在decoder部分使用,如表1(c)所示,如果encoder也使用mask token,linear probing的精度下降了14%。作者认为这是预训练和部署之间的差异造成的,在预训练的输入中有大量的mask token,这在未损坏的图像中是不存在的,这可能会降低部署时的性能。
Reconstruction target. 如表1(d)所示,才能归一化的像素值作为回归目标的效果要比直接重建原始像素值的效果更好。
Data augmentation. 结果如表1(e)所示,只用crop效果就很好了,如果用了color jittering效果反而会下降,作者解释在MAE中random masking本身就起到了数据增强的作用,因为每个iteration的mask都不同。
Mask sampling strategy. 作者还比较了不同mask策略的影响,除了默认的random mask,还有block mask和grid mask如图6所示,block mask在50%时效果还可以75%效果下降了,而grid mask使重建任务变简单了因此学习到的表示质量也变差了,对于MAE,random mask是最合适的。

代码解析
这里以mmpretrain中的实现为例进行讲解。输入shape为(2, 3, 224, 224),模型采用vit-base-p16。预训练部分的整体流程如下loss函数,backbone是encoder,neck是decoder,在head中计算重建损失。
class MAE(BaseSelfSupervisor):
"""MAE.
Implementation of `Masked Autoencoders Are Scalable Vision Learners
<https://arxiv.org/abs/2111.06377>`_.
"""
def extract_feat(self, inputs: torch.Tensor):
return self.backbone(inputs, mask=None)
def loss(self, inputs: torch.Tensor, data_samples: List[DataSample],
**kwargs) -> Dict[str, torch.Tensor]:
"""The forward function in training.
Args:
inputs (torch.Tensor): The input images.
data_samples (List[DataSample]): All elements required
during the forward function.
Returns:
Dict[str, torch.Tensor]: A dictionary of loss components.
"""
# ids_restore: the same as that in original repo, which is used
# to recover the original order of tokens in decoder.
latent, mask, ids_restore = self.backbone(inputs) # (2,50,768),(2,196),(2,196)
pred = self.neck(latent, ids_restore) # (2,196,768)
loss = self.head.loss(pred, inputs, mask)
losses = dict(loss=loss)
return losses我们先看encoder的实现,self.patch_embed和ViT中一样,这里patch_size=16,因此共有(224/16)x(224/16)=196个patch,每个patch的维度为16x16x3=768,得到的输出shape为(2, 196, 768)。然后加上位置编码,这里的self.pos_embed在初始化时加上了cls_token,因此这里取[:, 1:, :]。
def forward(
self,
x: torch.Tensor,
mask: Optional[bool] = True
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""Generate features for masked images.
The function supports two kind of forward behaviors. If the ``mask`` is
``True``, the function will generate mask to masking some patches
randomly and get the hidden features for visible patches, which means
the function will be executed as masked imagemodeling pre-training;
if the ``mask`` is ``None`` or ``False``, the forward function will
call ``super().forward()``, which extract features from images without
mask.
Args:
x (torch.Tensor): Input images, which is of shape B x C x H x W.
mask (bool, optional): To indicate whether the forward function
generating ``mask`` or not.
Returns:
Tuple[torch.Tensor, torch.Tensor, torch.Tensor]: Hidden features,
mask and the ids to restore original image.
- ``x`` (torch.Tensor): hidden features, which is of shape
B x (L * mask_ratio) x C.
- ``mask`` (torch.Tensor): mask used to mask image.
- ``ids_restore`` (torch.Tensor): ids to restore original image.
"""
if mask is None or False:
return super().forward(x)
else:
B = x.shape[0] # (2,3,224,244)
x = self.patch_embed(x)[0] # (2,196,768)
# add pos embed w/o cls token
x = x + self.pos_embed[:, 1:, :] # self.pos_embed.shape: (1,197,768), (2,196,768)
# masking: length -> length * mask_ratio
x, mask, ids_restore = self.random_masking(x, self.mask_ratio) # (2,49,768),(2,196),(2,196)
# append cls token
cls_token = self.cls_token + self.pos_embed[:, :1, :]
cls_tokens = cls_token.expand(B, -1, -1)
x = torch.cat((cls_tokens, x), dim=1) # (2,50,768)
for _, layer in enumerate(self.layers):
x = layer(x)
# Use final norm
x = self.norm1(x)
return (x, mask, ids_restore)然后是mae最核心的random masking部分,代码如下,这里mask_ratio=0.75。一共196个patch,mask掉0.75即保留0.25,这里len_keep=196x0.25=49。然后创建一个随机矩阵noise,通过argsort以升序的方式排序并得到索引矩阵ids_shuffle,取前len_keep个索引得到ids_keep就是所有196个patch中我们保存下来的patch的索引,其它的都mask掉。ids_restore又对ids_shuffle按升序的方式排序得到的索引可以用来恢复保存或mask的patch在原始图像中的位置,这里解释一下,原始196个patch的索引就是[0, 1, 2, ..., 195],ids_shuffle对原始索引随机采样比如得到[3, 25, 0, ..., 67],对ids_shuffle重新升序排序就又得到了[0, 1, 2, ..., 195],这样我们就可以通过ids_restore恢复通过ids_shuffle采样的输出的原本的顺序。
然后我们通过torch.gather和ids_keep从原始输入x中取出保存的那些patch,只有这些patch会经过encoder,torch.gather的用法具体见torch.gather() 用法解读_gather()怎么用-CSDN博客。然后我们再创建一个mask矩阵,其中保存的patch对应的值为0,masked patch的值为1,这里通过ids_restore恢复patch原本在图像中的顺序。这个mask用于后续经过encoder和decoder得到的输出和原始图片计算loss时,首先对前者进行处理,从而只计算masked patch的损失,而不计算那些保存下来的即可见的patch的损失。
def random_masking(
self,
x: torch.Tensor,
mask_ratio: float = 0.75
) -> Tuple[torch.Tensor, torch.Tensor, torch.Tensor]:
"""Generate the mask for MAE Pre-training.
Args:
x (torch.Tensor): Image with data augmentation applied, which is
of shape B x L x C.
mask_ratio (float): The mask ratio of total patches.
Defaults to 0.75.
Returns:
Tuple[torch.Tensor, torch.Tensor, torch.Tensor]: masked image, mask
and the ids to restore original image.
- ``x_masked`` (torch.Tensor): masked image.
- ``mask`` (torch.Tensor): mask used to mask image.
- ``ids_restore`` (torch.Tensor): ids to restore original image.
"""
N, L, D = x.shape # batch, length, dim, (2,196,768)
len_keep = int(L * (1 - mask_ratio)) # 49
noise = torch.rand(N, L, device=x.device) # noise in [0, 1]
# (2,196)
# sort noise for each sample
ids_shuffle = torch.argsort(
noise, dim=1) # ascend: small is keep, large is remove
# (2,196)
ids_restore = torch.argsort(ids_shuffle, dim=1) # (2,196)
# keep the first subset
ids_keep = ids_shuffle[:, :len_keep] # (2,49)
x_masked = torch.gather(
x, dim=1, index=ids_keep.unsqueeze(-1).repeat(1, 1, D)) # (2,49,768)
# generate the binary mask: 0 is keep, 1 is remove
mask = torch.ones([N, L], device=x.device) # (2, 196)
mask[:, :len_keep] = 0
# unshuffle to get the binary mask
mask = torch.gather(mask, dim=1, index=ids_restore) # (2,196)
return x_masked, mask, ids_restore我们再继续看encoder的forward部分,后续就是加上cls_token,然后经过若干个layer即Transformer block。
neck即decoder的实现如下,其中输入包括encoder学习到的潜在表示和ids_restore。首先self.decoder_embed就是一个线性映射将特征维度从768映射到512维。前面说过decoder的输入包括encoder的输出即学习到的潜在表示和mask token,这里mask token是可学习的向量。代码中mask_token定义为全0的可学习参数self.mask_token = nn.Parameter(torch.zeros(1, 1, decoder_embed_dim))并在函数init_weights中进行了权重初始化torch.nn.init.normal_(self.mask_token, std=.02)。然后将潜在表示和mask_token拼接起来并通过ids_restore恢复在原始图像中的顺序,即图1中间那列灰蓝相间的特征向量,其中蓝色表示潜在表示,灰色即使mask token,可以看到顺序和前面的Input中的顺序是一样的。
注意这里要再加一次位置编码即self.decoder_pos_embed,因为encoder只处理了保留的patch,而这里又加上了masked patch,处理的是完整的patch集和,所以需要加上完整的位置编码。然后经过若干decoder_blocks即Transformer block,最后的self.decoder_pred是一个linear projection,维度就是原始的特征维度,前面将768映射到了512这里再映射回去,因为这里包含了cls_token,最后再把cls_token去掉就得到了decoder的输出,可以看到和原始的输入维度是一样的。
def forward(self, x: torch.Tensor,
ids_restore: torch.Tensor) -> torch.Tensor: # (2,196)
"""The forward function.
The process computes the visible patches' features vectors and the mask
tokens to output feature vectors, which will be used for
reconstruction.
Args:
x (torch.Tensor): hidden features, which is of shape
B x (L * mask_ratio) x C.
ids_restore (torch.Tensor): ids to restore original image.
Returns:
torch.Tensor: The reconstructed feature vectors, which is of
shape B x (num_patches) x C.
"""
# embed tokens
x = self.decoder_embed(x) # (2,50,768)->(2,50,512)
# append mask tokens to sequence
mask_tokens = self.mask_token.repeat(
x.shape[0], ids_restore.shape[1] + 1 - x.shape[1], 1) # (1,1,512)->(2,147,512), 196+1-50=147
# ids_restore中没有考虑cls_token,而x中考虑了cls_token,这里实际应该是ids_restore.shape[1] - (x.shape[1] - 1)
x_ = torch.cat([x[:, 1:, :], mask_tokens], dim=1) # [(2,49,512),(2,147,512)]->(2,196,512)
# 下面的unshuffle是不包含cls_token的,所以这里也要把cls_token去掉,所以取1:
x_ = torch.gather(
x_,
dim=1,
index=ids_restore.unsqueeze(-1).repeat(1, 1, x.shape[2])) # unshuffle, (2,196,512)
x = torch.cat([x[:, :1, :], x_], dim=1) # (2,197,512), 再把cls_token加回去
# add pos embed
x = x + self.decoder_pos_embed # (2,197,512)+(1,197,512)->(2,197,512)
# apply Transformer blocks
for blk in self.decoder_blocks:
x = blk(x)
x = self.decoder_norm(x)
# predictor projection
x = self.decoder_pred(x) # (2,197,768)
# remove cls token
x = x[:, 1:, :]
return x最后是计算损失部分,代码如下
def loss(self, pred: torch.Tensor, target: torch.Tensor,
mask: torch.Tensor) -> torch.Tensor:
"""Generate loss.
Args:
pred (torch.Tensor): The reconstructed image.
target (torch.Tensor): The target image.
mask (torch.Tensor): The mask of the target image.
Returns:
torch.Tensor: The reconstruction loss.
"""
target = self.construct_target(target) # (2,3,224,224)->(2,196,768)
loss = self.loss_module(pred, target, mask)
return lossself.construct_target的代码如下,首先self.patchify和前面的patch_embed一样将输入从(2, 3, 224, 224)转换成(2, 196, 768),这样和pred的维度就一致了。当self.norm_pix=True时归一化每个patch的像素作为预测的target,就是target就是每个像素点原始的value。
def construct_target(self, target: torch.Tensor) -> torch.Tensor:
"""Construct the reconstruction target.
In addition to splitting images into tokens, this module will also
normalize the image according to ``norm_pix``.
Args:
target (torch.Tensor): Image with the shape of B x C x H x W
Returns:
torch.Tensor: Tokenized images with the shape of B x L x C
"""
target = self.patchify(target) # (2,196,768)
if self.norm_pix:
# normalize the target image
mean = target.mean(dim=-1, keepdim=True) # (2,196,1)
var = target.var(dim=-1, keepdim=True) # (2,196,1)
target = (target - mean) / (var + 1.e-6)**.5 # (2,196,768)
return target最后的self.loss_module就是torch.nn.MSELoss。


















 5031
5031

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











