







paper:SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
official implementation:GitHub - NVlabs/SegFormer: Official PyTorch implementation of SegFormer
third-party implementation:https://github.com/open-mmlab/mmsegmentation/tree/main/configs/segformer
出发点
尽管ViT和SETR在语义分割中取得了一定的成功,但它们存在一些限制,如输出单尺度低分辨率特征、高计算成本等。此外,现有方法大多关注Transformer编码器的设计,而忽视了解码器对进一步改进的重要性。因此,本文提出了SegFormer,一个同时考虑效率、准确性和鲁棒性的语义分割框架。
创新点
和SETR一样,也是将分类Transformer中的一些改进引入到语义分割中,比如PVT中的多层次特征以及spatial-reduction attention(具体介绍见Pyramid Vision Transformer, PVT(ICCV 2021)原理与代码解读_pyramid-type hierarchical transformer-CSDN博客),CPVT中用3x3卷积代替显式的位置编码(具体介绍见CPVT(ICLR 2023)论文解读_conditional position embedding (cpe)-CSDN博客)。
- 层次化Transformer编码器:SegFormer引入了层次化结构,使编码器能够生成高分辨率细节特征和低分辨率粗糙特征,提升了适应性。具体包括:
-
- Hierarchical Feature Representation:通过在每个stage都使用patch merging来降低特征图的分辨率,生成多尺度的特征表示,这对于语义分割任务至关重要。通过这种方式,编码器可以同时提供高分辨率的粗糙特征和低分辨率的精细特征,从而更好地捕捉不同尺度的上下文信息。
- Overlapped Patch Merging:为了在保持局部连续性的同时获得分层特征图,SegFormer采用了重叠patch merging技术。这种方法通过重叠的patch来合并特征,与不重叠的patch merging相比,可以生成相同大小的特征图,同时更好地保留局部信息。
- Sequence Reduction:SegFormer通过引入一个降维比例R来减少序列的长度,从而降低自注意力的计算复杂度。
- Mix-FFN:SegFormer提出了一种新颖的前馈网络结构,称为Mix-FFN,它结合了3x3深度卷积和MLP。这种结构可以有效地提供位置信息,而无需依赖于固定分辨率的位置编码。这使得模型在不同分辨率的输入下更加灵活,避免了因插值操作导致性能下降的问题。
- 轻量级全MLP解码器:该解码器利用Transformer生成的特征,将低层的局部注意力和高层的全局注意力结合起来,形成强大的表示能力,而不需要复杂的计算模块。
方法介绍
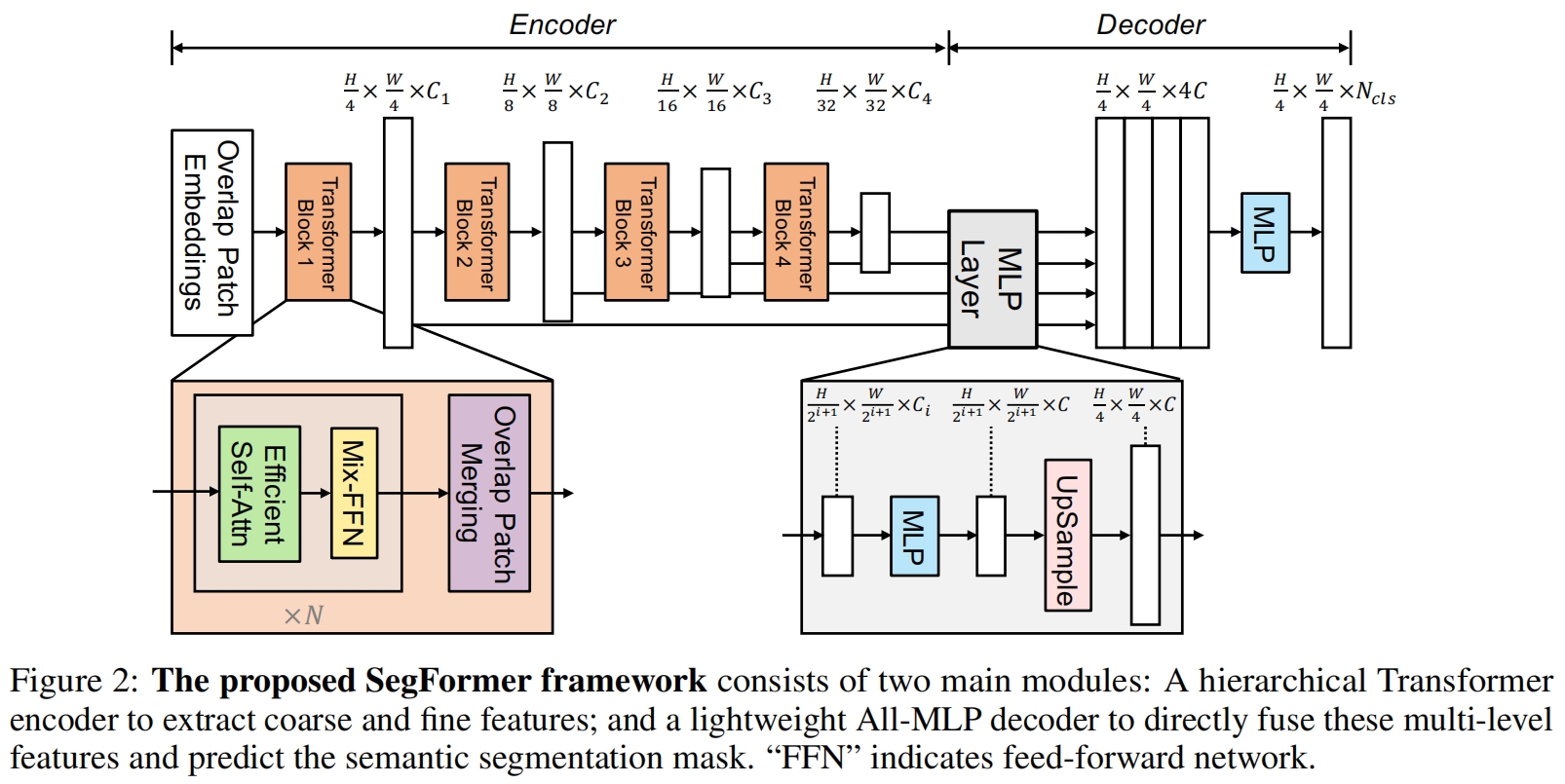
Hierarchical Transformer Encoder
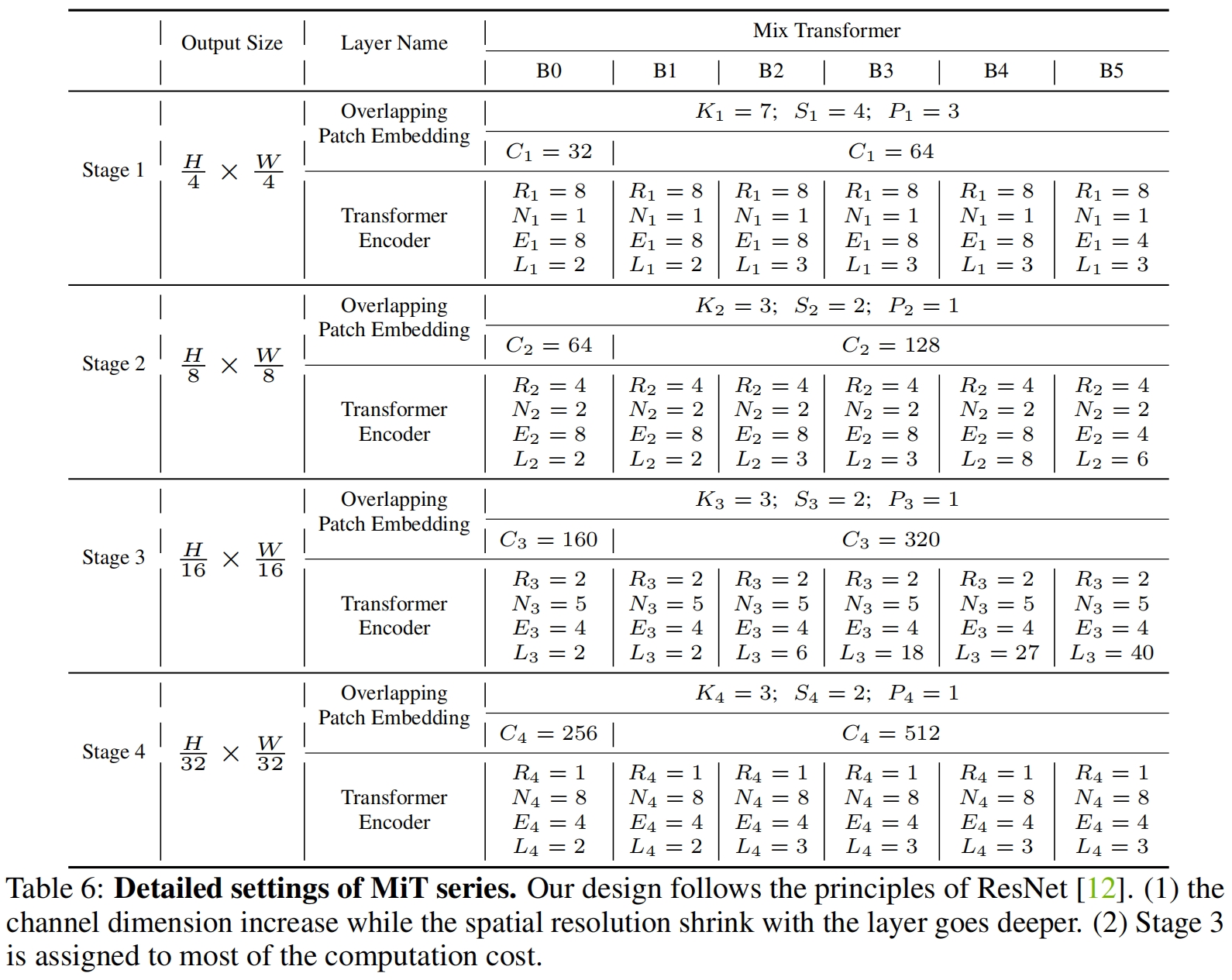
作者设计了一系列Mix Transformer encoder(MiT),MiT-B0到MiT-B5。
Hierarchical Feature Representation.
和ViT只能生成单分辨率的特征图不同,该模块的目标是给定一张图片,生成类似于CNN的多层次特征。具体是通过patch merging层实现的,在每个stage的开始都有一个patch merging层。
Overlapped Patch Merging.
在ViT中,patch之间是不重叠的,patch merging可以通过卷积来实现,比如每个patch大小为16x16,可以通过kernel_size=16,stride=16的卷积实现。不重叠的patch无法保留patch周围的局部连续性,因此本文提出了重叠的patch merging,首先定义 \(K,S,P\) 分别表示卷积的kernel size、stride、padding,本文的所有模型都包含4个stage,第一个stage中 \(K=7,S=4,P=3\) 就实现了分辨率4倍的降采样,其余的3个stage中 \(K=3,S=2,P=1\) 进行2倍降采样,从而得到前面提到的不同大小的多层次特征。
Efficient Self-Attention.
在原始的多头self-attention中,每个head的 \(Q,K,V\) 的维度都是 \(N\times C\),其中 \(C=H\times W\) 是序列长度,自注意计算公式如下
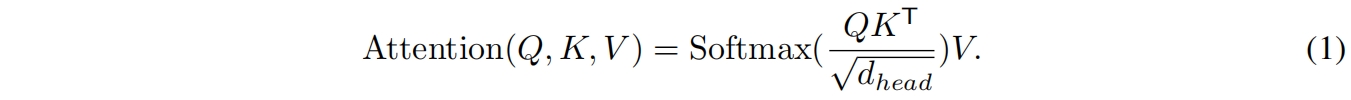
计算复杂度是 \(O(N^2)\)。本文使用PVT中的sequence reduction做法,对序列长度(分辨率)进行降维,如下,其中 \(R\) 是reduction ratio,计算复杂度变成了 \(O(\frac{N^2}{R})\)
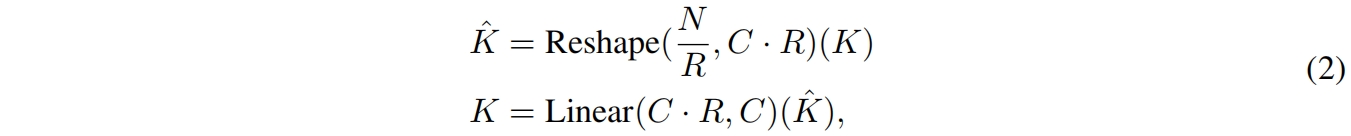
Mix-FFN
ViT使用位置编码PE引入位置信息,但PE的分辨率是固定的,当测试分辨率和训练分辨率不一致时需要进行插值,这通常会导致精度的下降。CPVT中通过卷积来保留位置信息,而本文提出了Mix-FFN,它考虑了zero padding对泄露位置信息的影响。通过在FFN中使用3x3卷积,Mix-FFN定义如下
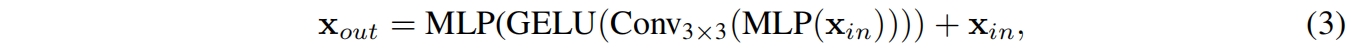
为了进一步减少参数提高效率这里使用的是3x3深度卷积。
Lightweight ALL-MLP Decoder
本文提出了一个轻量化的全由MLP组成的解码器,之所以可以使用如此简单轻量的decoder是因为本文的分层Transformer编码器比传统的卷积编码器具有更大的有效感受野。ALL-MLP decoder具体包括四步:1)首先来自编码器的multi-level特征 \(F_i\) 通过一个MLP层统一通道维度。2)特征上采样到输入的1/4大小并concat到一起。3)另一个MLP层用来融合拼接后的特征 \(F\)。4)最后一个MLP层作为预测输出层得到最终输出mask \(M\),shape为 \(\frac{H}{4}\times \frac{W}{4} \times N_{cls}\),\(N_{cls}\) 为类别数。如下
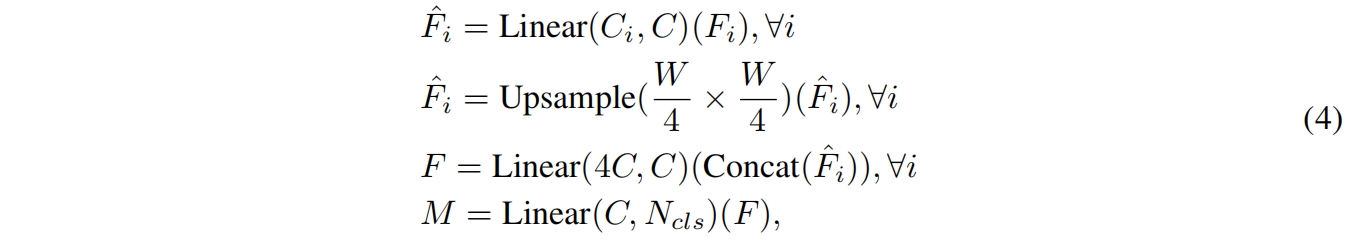
实验结果
MiT-B0到MiT-B5的具体配置如下
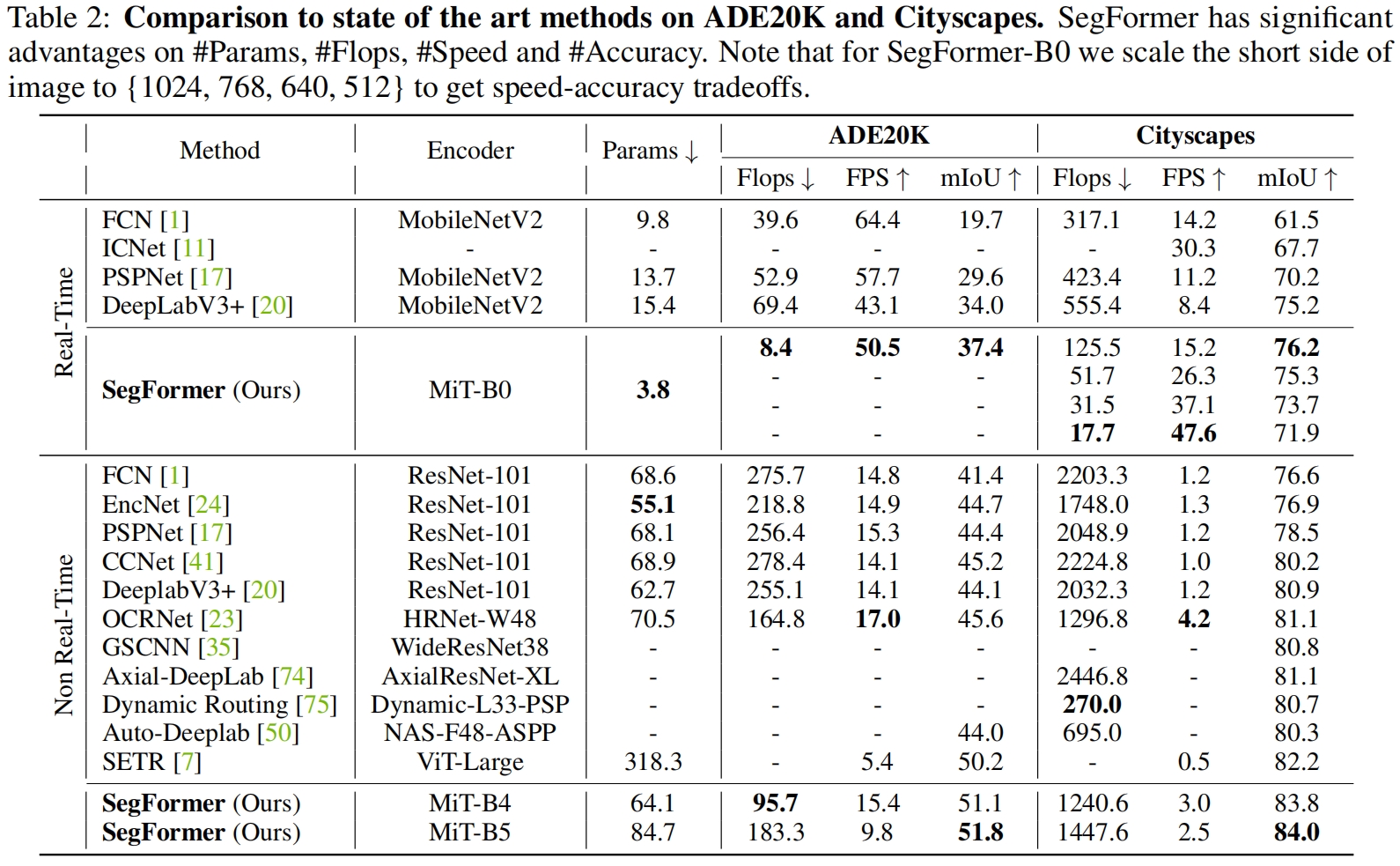
在ADE20K和Cityscapes数据集上和其它模型的性能对比如下,可以看到SegFormer取得了新的SOTA表现。


















 993
993

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











