







1 首先参照上篇,搭建本地的ChatGLM-6B对话大模型:
【全网最简单】5分钟 基于Win10 搭建本地ChatGLM-6B对话大模型-CSDN博客
2 安装python交互式的Web库Streamlit:
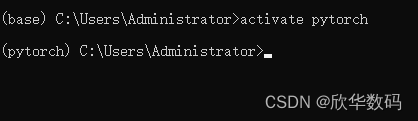
a)打开Conda命令行,进入上篇中使用的虚拟环境:
b)安装Streamlit库:
pip install streamlit

c) 验证是否安装成功:
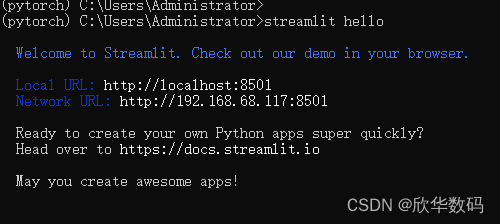
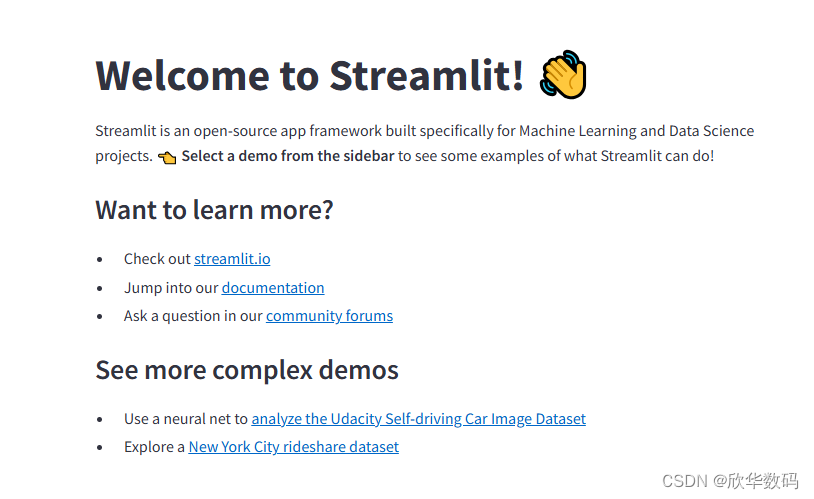
看到这个页面证明安装已经成功。中间可能需要输入邮箱,随便输入一个就行。
3 修改chat_web.py
需修改两句代码:
#此处修改为本地模型数据存放路径
tokenizer = AutoTokenizer.from_pretrained("D:\workplace\ChatModel\chatglm2-6b", trust_remote_code=True)
#此处修改为本地模型数据存放路径
model = AutoModel.from_pretrained("D:\workplace\ChatModel\chatglm2-6b", trust_remote_code=True).cuda()
修改后代码如下:
from transformers import AutoModel, AutoTokenizer
import streamlit as st
st.set_page_config(
page_title="ChatGLM2-6b 演示",
page_icon=":robot:",
layout='wide'
)
@st.cache_resource
def get_model():
#此处修改为本地模型数据存放路径
tokenizer = AutoTokenizer.from_pretrained("D:\workplace\ChatModel\chatglm2-6b", trust_remote_code=True)
#此处修改为本地模型数据存放路径
model = AutoModel.from_pretrained("D:\workplace\ChatModel\chatglm2-6b", trust_remote_code=True).cuda()
# 多显卡支持,使用下面两行代替上面一行,将num_gpus改为你实际的显卡数量
# from utils import load_model_on_gpus
# model = load_model_on_gpus("THUDM/chatglm2-6b", num_gpus=2)
model = model.eval()
return tokenizer, model
tokenizer, model = get_model()
st.title("ChatGLM2-6B")
max_length = st.sidebar.slider(
'max_length', 0, 32768, 8192, step=1
)
top_p = st.sidebar.slider(
'top_p', 0.0, 1.0, 0.8, step=0.01
)
temperature = st.sidebar.slider(
'temperature', 0.0, 1.0, 0.8, step=0.01
)
if 'history' not in st.session_state:
st.session_state.history = []
if 'past_key_values' not in st.session_state:
st.session_state.past_key_values = None
for i, (query, response) in enumerate(st.session_state.history):
with st.chat_message(name="user", avatar="user"):
st.markdown(query)
with st.chat_message(name="assistant", avatar="assistant"):
st.markdown(response)
with st.chat_message(name="user", avatar="user"):
input_placeholder = st.empty()
with st.chat_message(name="assistant", avatar="assistant"):
message_placeholder = st.empty()
user_input = st.text_area(label="用户命令输入",
height=100,
placeholder="请在这儿输入您的命令")
button = st.button("发送", key="predict")
if button:
input_placeholder.markdown(user_input)
model_input = user_input
history, past_key_values = st.session_state.history, st.session_state.past_key_values
for response, history, past_key_values in model.stream_chat(tokenizer, model_input, history,
past_key_values=past_key_values,
max_length=max_length, top_p=top_p,
temperature=temperature,
return_past_key_values=True):
message_placeholder.markdown(response)
st.session_state.history = history
st.session_state.past_key_values = past_key_values
4 使用streamlit run 运行chat_web.py
streamlit run chat_web.py , 注意:此处不是 python chat_web.py

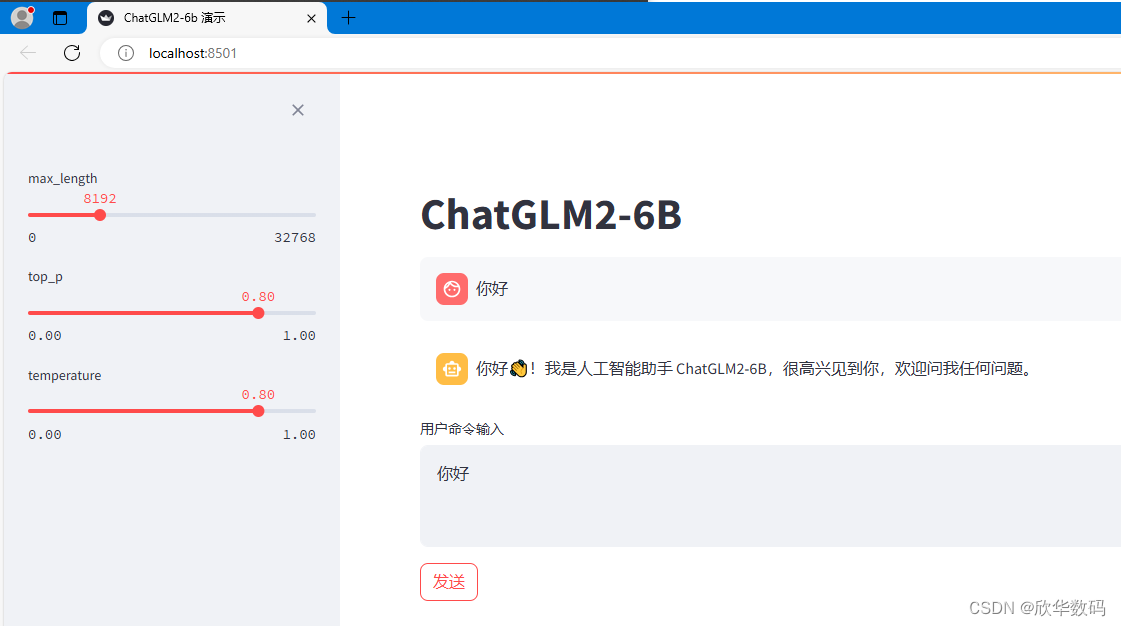
看到进度条到100%,恭喜你,运行成功!
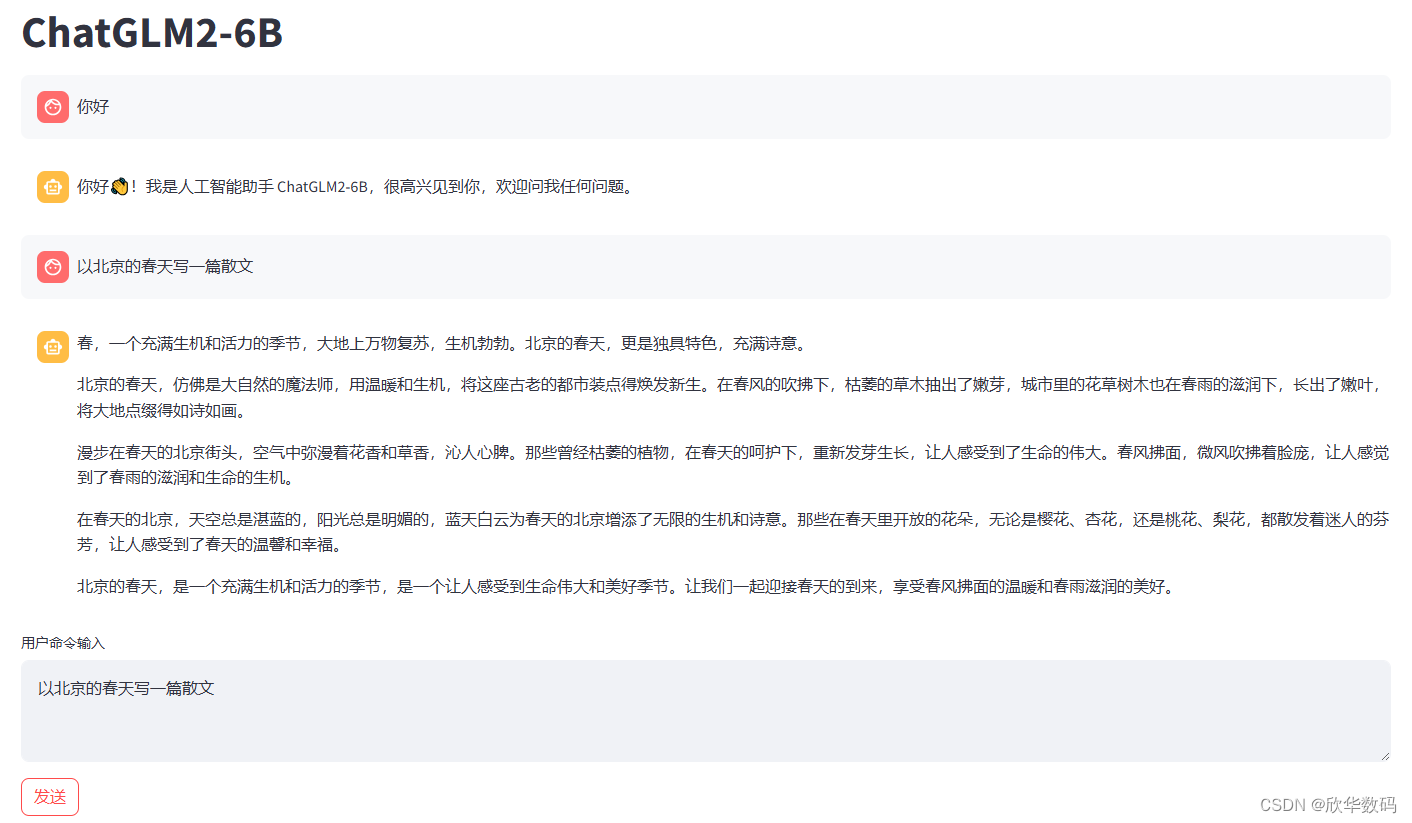
运行后会自动打开默认浏览器:
5 在局域网任意一台机器尽情享受与ChatGlm的聊天吧!
在浏览器地址栏输入: http://192.168.x.x:8501 ,即可访问大模型Web服务
如果你有域名和外网地址,即可提供类ChatGpt服务 :)















 654
654

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









