






目录
一.课程内容
其实与其说是加载数据集,不如说是对数据集的预处理。
通过shuffle将其打乱,然后组成mini-batch,进行训练,后面的内容就跟上一节差不多啦。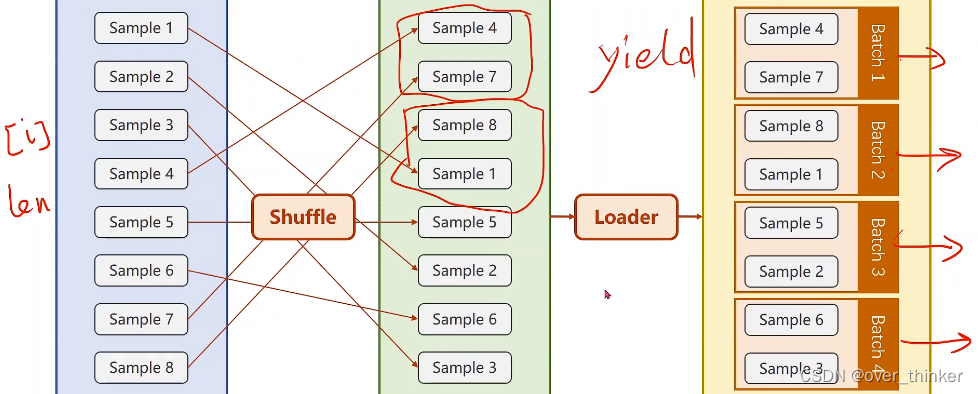
读取数据集,一般有两种方式:
1.将全部数据直接读取进来,适用于数据内存不大的数据。
2.只读取文件名,把文件名存成矩阵处理,避免内存大导致性能不好。

二.代码复现及结果
from ast import Return
from operator import itemgetter
from pickletools import optimize
from torch.utils.data import Dataset #抽象类,不能有实例化对象,只能被继承
from torch.utils.data import DataLoader
import numpy.matlib
import torch
import numpy as np
import matplotlib.pyplot as plt
class Diabetes(Dataset):
def __init__(self,filepath1,filepath2 ):
x_yuan=np.loadtxt(filepath1,delimiter=' ',dtype=np.float32)
y_yuan=np.loadtxt(filepath2,delimiter=' ',dtype=np.float32)
self.len=x_yuan.shape[0]
self.x_data=torch.from_numpy(x_yuan)
self.y_data=torch.from_numpy(y_yuan)
def __getitem__(self, index) :#魔法函数
return self.x_data[index],self.y_data[index]
def __len__(self):
return self.len
dataset=Diabetes("C:\\anaconda_3\\Lib\\site-packages\\sklearn\\datasets\\data\\diabetes_data.csv.gz","C:\\anaconda_3\\Lib\\site-packages\sklearn\\datasets\\data\\diabetes_target.csv.gz")
train_loader=DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=0)
print(train_loader)
class Model(torch.nn.Module):
def __init__(self) :
super(Model,self).__init__()
self.linear1=torch.nn.Linear(10,6)#维度报错,这里老师给的和数据不一致修改一下
self.linear2=torch.nn.Linear(6,4)
self.linear3=torch.nn.Linear(4,1)
self.sigmoid=torch.nn.Sigmoid()
'''self.activate=torch.nn.Sigmoid'''
def forward(self,x):
x=self.sigmoid(self.linear1(x))
x=self.sigmoid(self.linear2(x))
'''x= torch.tensor(x)'''
x=self.sigmoid(self.linear3(x))
x= x.squeeze(-1) #计算出来的数据是422*1的矩阵,与输入为一维张量不符,需要降维
return x #避免出现参数传递错误,就不设置新参数而是选择x自动代换
model=Model()
sunshi=torch.nn.BCELoss(size_average=True)
youhua=torch.optim.SGD(model.parameters(),lr=0.1)
e_ch=[]
loss_l=[]
if __name__ == '__main__':
for epoch in range(100):
for i,data in enumerate(train_loader,0):
x_data,y_data=data
y_pred=model(x_data)
loss = sunshi(y_pred,y_data)
print(epoch,i,loss.item())
e_ch.append(epoch)
loss_l.append(loss.item())
youhua.zero_grad()
loss.backward()
youhua.step()
plt.plot(e_ch,loss_l)
plt.xlabel("epoch")
plt.ylabel("loss")
plt.show()
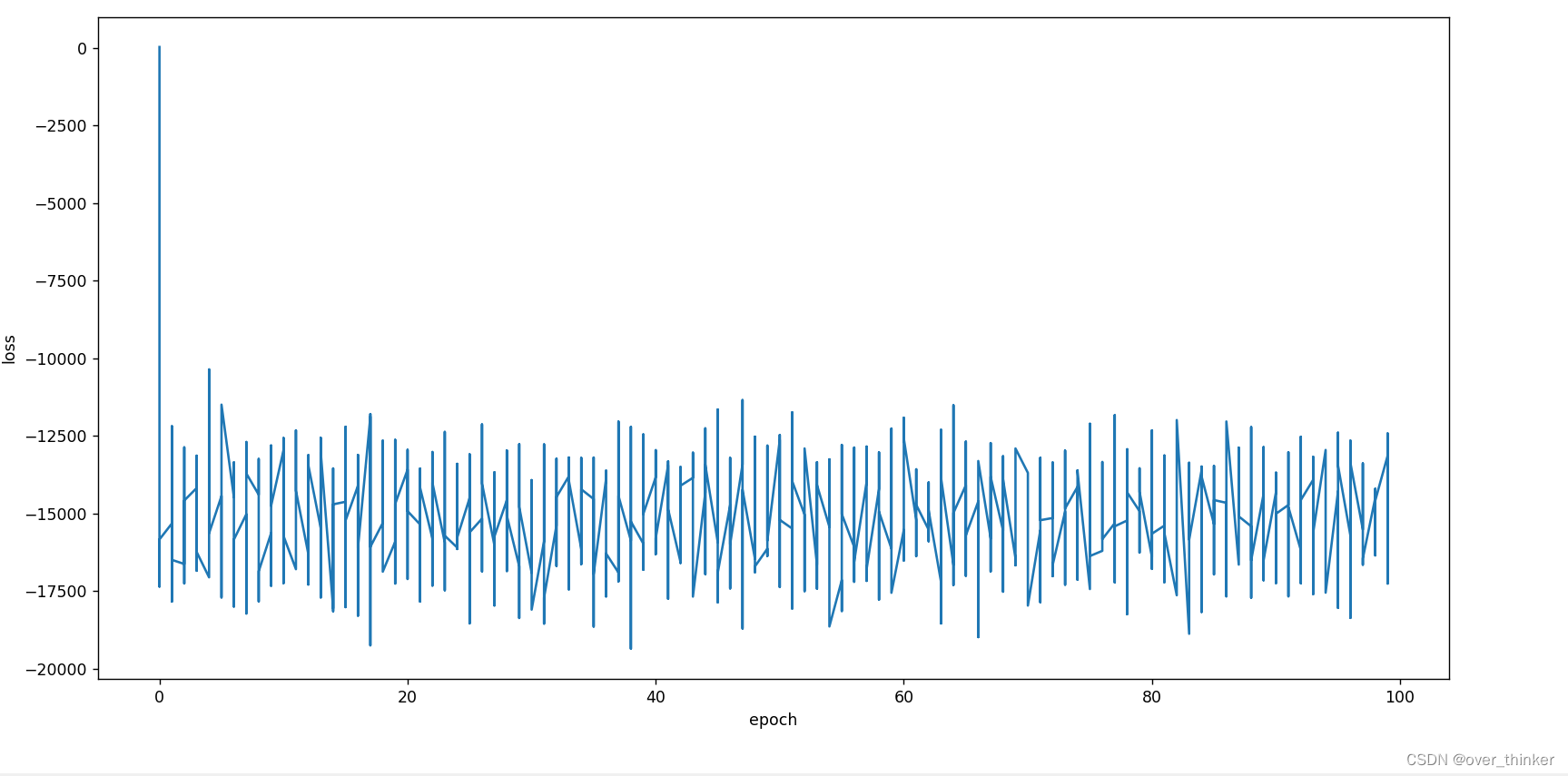 我知道结果很烂,但是我已经知道原因了,因为新数据集里的y和老师的不一样,是一个 实数集,不是0和1的分类问题.再打这段字的时候我突然意识到,既然激活函数就是将实数集映射到[0.1]之中,所以我们将代码稍加修改
我知道结果很烂,但是我已经知道原因了,因为新数据集里的y和老师的不一样,是一个 实数集,不是0和1的分类问题.再打这段字的时候我突然意识到,既然激活函数就是将实数集映射到[0.1]之中,所以我们将代码稍加修改
dataset.y_data=torch.sigmoid(dataset.y_data)
train_loader=DataLoader(dataset=dataset,batch_size=32,shuffle=True,num_workers=0)绘制图像
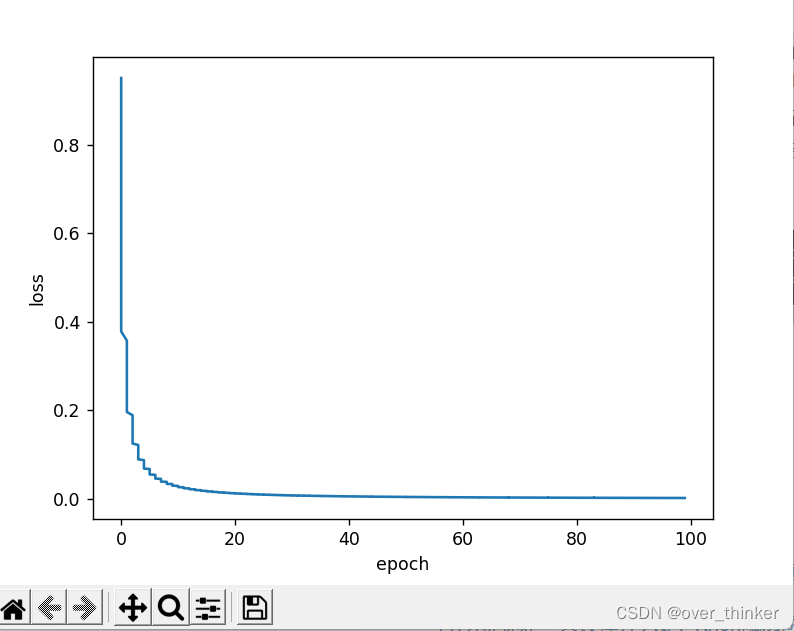
三.补充
1,关于魔法函数--请看这几篇Python进阶:实例讲解Python中的魔法函数(Magic Methods) - 知乎 (zhihu.com)
(47条消息) 一文读懂什么是Python魔法函数_吃花椒的喵醬的博客-CSDN博客_python魔法函数是什么
2.关于如何用新数据集拟合,虽然我找了用不同方法的博客,但是我自己解决了。不过还是贴着留作以后看。
(47条消息) 线性回归做糖尿病分析(diabetes数据集),并分析单个特征值与病情的关系_做个好男人!的博客-CSDN博客_diabetes数据集
3.关于datas和dataloader
(47条消息) pytorch-DataLoader(数据迭代器)_学渣渣渣渣渣的博客-CSDN博客_数据迭代器
4.另外还有一个错误:TypeError: 'tuple' object is not callable.
.shape是一个turple数据类型,你在后面加“()”,相当于把.shape看成了一个函数名,相当于调用,.shape函数,因此会报错:
tuple对象不能被调用 的错误!!!!















 1914
1914











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









