









Abstract
金融投资组合管理是将资金不断分配到不同的金融产品,以期获得更大累计收益的过程。本文展示了一个不使用金融模型的强化学习框架,为投资组合管理问题提供深度机器学习解决方案。该框架包括 EIIE(完全相同的独立评估者的集合)拓扑、投资组合内存、在线随机批量学习,和针对即时奖励的奖励函数。本研究中该框架在三种情况下得到实现:卷积神经网络(CNN)、基础循环神经网络(RNN)和长短期记忆网络(LSTM)。它们和大量近期评审或公布的投资组合选择策略经历了三次后验测试实验,实验中加密货币市场的交易周期是 30 分钟。加密货币是一种去中心化的电子货币,其中最著名的就是比特币。该框架的三种实例在所有实验中稳稳占据前三名的位置,优于其他交易算法。尽管后验测试中的佣金率高达 0.25%,该框架仍然能够在 50 天内使收益至少是原来的 4 倍。
Introduction
提到四种传统投资组合管理方法
1.Follow the Winner - 尝试渐近地实现与最佳策略相同的增长率(预期的日志返回),这通常基于CGT。
2.Follow the Loser-将财富从获胜的资产转移到输家,这似乎与常识矛盾,但从经验得出往往会达到明显更好的表现。
3.Pattern Matching–based approaches- 试图基于历史数据采样来预测下一个市场分布和基于采样分布来明确优化产品组合。
4.Meta-Learning Algorithm(MLAS) - 虽然上面这三个类别聚焦单一策略(类),但还有一些其他策略关注多种策略(类)。元算法(MAs)它通过自适应地组合来自基本优化算法池的迭代来工作
小小dis了下价格预测
许多人试图预测价格变动或趋势,以所有资产的历史价格作为输入,神经网络可以输出下一时期资产价格的预测向量。这个想法很容易实现,因为它是一个监督学习,或者更具体地说是一个回归问题。然而,这些基于价格预测的算法的性能在很大程度上取决于预测的acc,但事实证明,未来的市场价格很难预测。
离散交易信号
xxxx
可扩展性的必要性
市场行为可以离散化,但离散化被认为是一个主要缺点,因为离散化的行为会带来未知风险。例如,一个极端的离散行为可能被定义为将所有资本投资于一项资产,而不将风险分散到市场的其他部分。此外,离散化的规模非常大。市场因素,如总资产的数量,因市场而异。为了充分利用机器学习对不同市场的适应性,交易算法必须具有可扩展性。
本文的重点思想框架
本文提出了一个专门为项目组合管理任务设计的RL框架。该框架的核心是相同独立评估器(EIIE=Ensemble of Identical Independent Evaluators 完全相同的独立评估者的集合)拓扑的集成。IIE是一种神经网络,其工作是检查资产的历史并评估其近期的潜在增长。每个资产组的评估分数根据其在组合中资产的有意权重变化的大小进行贴现,并呈现给softmax层,其结果将是下一交易期的新组合权重。除市场历史记录外,EIIE中还输入了前一交易期的投资组合权重。这需要RL代理人考虑交易成本对其财富的影响。所以将每个时期的投资组合权重记录在投资组合向量存储器(PVM)中。EIIE采用一种在线随机批量学习方案(OSBL)进行训练,该方案与交易前训练和回测或在线交易期间的在线训练兼容。RL框架的报酬函数是周期对数收益的显式平均。EIIE具有明确的功能,在训练下,它沿着功能的梯度上升方向进化。这项工作测试了三种不同的IIE,一种卷积神经网络(CNN),一种基本的递归神经网络(RNN),以及长短期记忆(LSTM)
加密货币
比特币仍是占主导地位的加密货币。
加密货币有两种不同于传统金融资产的性质:分散化和开放性,使其市场成为算法投资组合管理实验的最佳试验场。
Problem Definition
公式
vt are the opening prices for Period t + 1 as well as the closing prices for Period t
price relative vector of the tth trading period, yt,
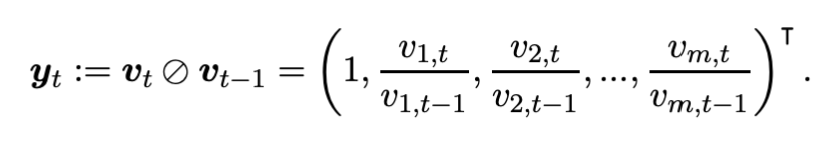
If pt−1 is the portfolio value at the begining of Period t, ignoring transaction cost, wt−1 is the portfolio weight vector
![]()
The rate of return for Period t is then (3)
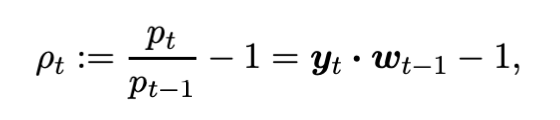
If there is no transaction cost, the final portfolio value will be
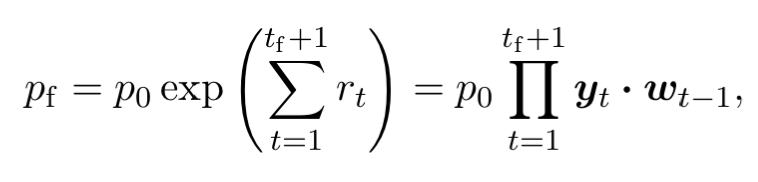
at the end of the same period, the weights evolve into:(⊙ is the element-wise multiplication)
![]()
(下面的点乘我怀疑是乘起来加和,就是保证最终的所有w加起来=1)
Denoting pt−1 as the portfolio value at the beginning of Period t and pt′ at the end,µt ∈ (0, 1]
![]()
The rate of return (3) and logarithmic rate of return (4) are now

and the final portfolio value in Equation (6) becomes
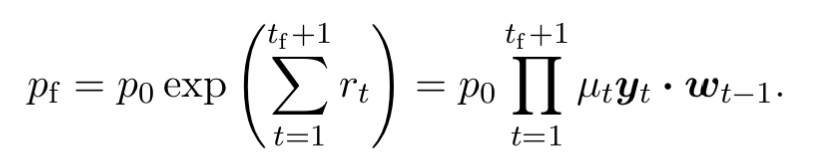
后面的公式卡了555
假设
股票回测定义:是指设定了某些股票指标组合后,基于历史已经发生过的真实行情数据,在历史上某一个时间点开始,严格按照设定的组合进行选股,并模拟真实金融市场交易的规则进行模型买入、模型卖出,得出一个时间段内的盈利率、最大回撤率等数据。
在这项工作中,只考虑回测交易(参考股票回测的定义),即交易代理假装回到市场历史上的某个时间点,不知道任何“未来”市场信息,并从那时起进行纸面交易。作为回测实验的要求,有以下两个假设:。零滑移:所有市场资产的流动性都足够高,每次交易都可以在下订单时立即以最后的价格进行。2.零市场影响:软件交易代理人投入的资金微不足道,对市场没有影响。在现实的交易环境中,如果一个市场的交易量足够大,这两个假设就接近现实。
Data Treatments
资产预选
选择top-volumed cryptocurrencies,因为意味着资产的市场流动性好。
但是不在回测实验过程中去选择top-volumed cryptocurrencies,因为资产的交易量与其受欢迎程度相关,而这受其历史表现的影响。将未来销量排名给到回测,将不可避免地间接地将未来的价格信息传递给实验,造成不可靠的积极结果。出于这个原因,在回测开始之前要根据容量信息预选,以避免生存偏差。
Price Tensor
资产在时间t内的特征为收盘价,最高价,最低价。
由于只有价格的变化才会决定资产组合管理的性能,所以所有特征价格都要/收盘价进行标准化,最终得到叠加的Xt


Filling Missing Data
flat fake price-movements (0 decay rates)平坦的假价格(0衰减率)来填充缺失点
Reinforcement Learning
采用的是Full-Exploitation和Deterministic Policy Gradient
虽然许多金融市场都有完整的订单历史记录,但agent实际处理这些信息的任务太大了。因此,订单历史信息的子抽样方案被用于未来简化市场环境的状态表示。
(1)periodic feature extraction 周期性特征提取。周期特征提取将时间离散为多个时段,然后提取每个时段的最高、最低和收盘价。
(2)history cut-off 历史截止,只是简单地利用最近几个时期的价格特征来代表环境当前状态。
结果表示为第3.2节中所述的价格张量Xt。
买卖是由Wt'(Wt-1)和Wt两个值确定的,而Wt-1是在t-1时刻确定的,因此t时刻的动作只有Wt
t-1时刻的动作Wt-1对t时刻的买卖有影响,t时刻的状态要包含t-1时刻的动作Wt-1
Policy Networks
Softmax
Network Topologies
CNN,RNN,LSTM
在所有情况下,网络的输入是中定义的价格张量X,输出是投资组合向量WT

Figure 2: CNN Implementation of the EIIE
a 全卷积网络。最后一个隐藏层是所有非现金资产的投票分数。这些分数和现金偏差的softmax激活函数结果将成为实际对应的投资组合权重。为了使神经网络考虑交易成本,从上一期的投资组合向量wt-1,插入到投票层之前的网络中。

Figure 3: RNN (Basic RNN or LSTM) Implementation of the EIIE
在这种情况下,单个资产的价格输入由小的循环子网获取。这些子网是相同的LSTM或基本RNN。循环子网之后的可感知网络的结构与CNNI图的后半部分相同。
Portfolio-Vector Memory

Figure 4: A Read/Write Cycle of the Portfolio-Vector Memory
PVM是一组按时间顺序排列的投资组合向量。初始化为统一相同的权重。
在每个训练步骤中,策略网络从t处的内存位置加载上一时期的投资组合向量t− 1,并用其输出覆盖t处的内存。随着policy网络的参数在多个训练阶段的收敛,内存中的值也会收敛。
Online Stochastic Batch Learning
与监督学习不同的是,在监督学习中,数据点是无序的,小批量是训练样本空间的随机不相交子集,在这种训练方案中,批次中的数据点必须按时间顺序排列。此外,由于数据集是时间序列,从不同时期开始的小批量被认为是有效和独特的,即使它们有明显的重叠间隔。
(说实话没懂xs)















 8263
8263











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









