







前言
这两天终于把freertos的内存管理看完了,由于看的比较细,所以看了好久才看完,这里整理一下所有思考和值得学习的地方。
具体的原理就不介绍了,好多博客和视频都有具体说明,这里说一下heap_4的一些缺陷(heap_5与heap_4基本一样,就不一一列举了)
Heap_4缺陷
1. 标记是否使用的最高位bit,在字节对齐后未判断
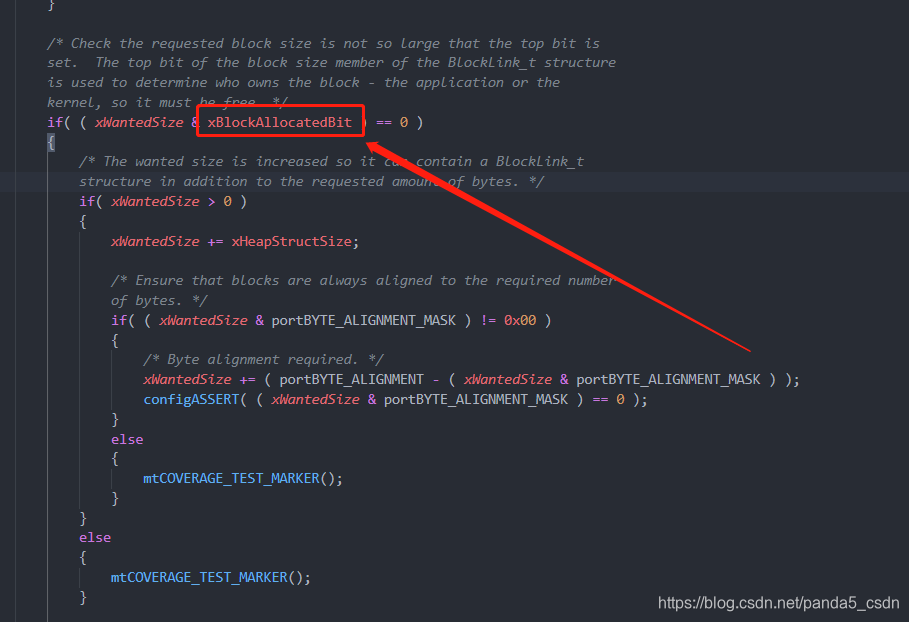
在申请内存的pvPortMalloc()函数中,例如申请内存为0x7FFF FFFF在字节对齐的过程中,进行字节对齐,就会溢出,使得最高位变为1,和定义的最高位代表是否被使用冲突。
虽然实际应用中不会一次性申请这么大的内存,可是依旧会有bug存在。(我的版本是v10.1.1了,被亚马逊收购了,这个问题依旧存在,看来亚马逊就是增加了个注释而已)
2. 申请内存遍历链表,找到及退出
heap_4支持内存合并,依据的是释放的地址和前后空闲内存块是否连续而进行合并(与heap_2不同,heap_2采用的是根据内存块大小从小到大的顺序进行插入)。
但是在申请内存时,代码中找到了符合的内存块就退出了,也就意味着,如果空闲内存链表中有一个BlockSize为10字节的空间和2个字节的空间,申请了1字节内存(这里不考虑字节对齐)会直接在前面的10字节中进行分割,导致变为9字节+2字节的空间。
如果考虑极限情况,也就是可能存在剩余100字节,但是连10个字节的空间都申请不到,因为剩余内存都是被分割成小块得内存。
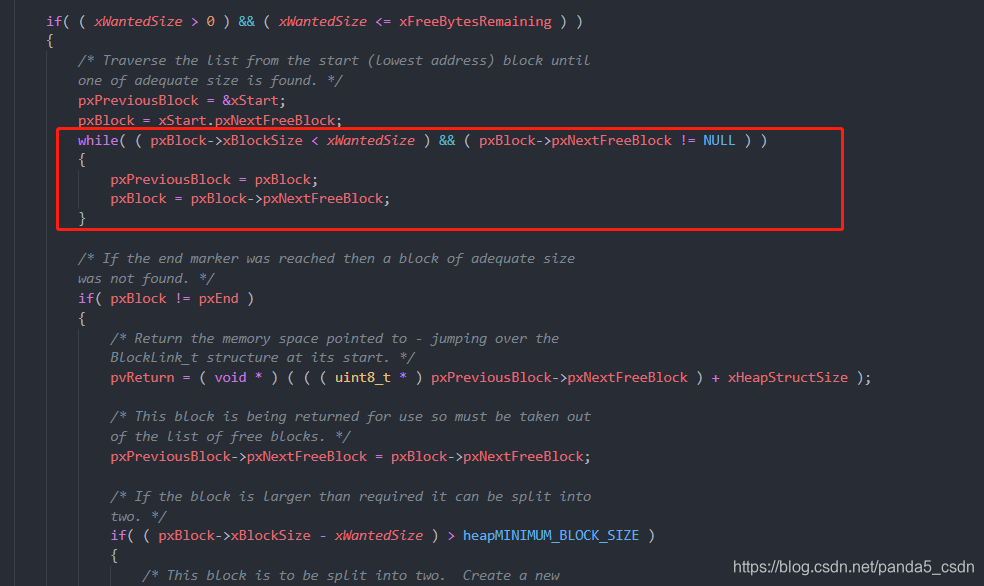
个人觉得可以在查找得时候,查找最符合申请大小的空闲块,这样碎片更少,但是效率降低。(也就是从上面的2字节空间中查找,而不是找到10字节空间中就结束了)
学习点
1. 字节对齐的写法
/* The size of the structure placed at the beginning of each allocated memory
block must by correctly byte aligned. */
static const size_t xHeapStructSize = ( sizeof( BlockLink_t ) + ( ( size_t ) ( portBYTE_ALIGNMENT - 1 ) ) ) & ~( ( size_t ) portBYTE_ALIGNMENT_MASK );
/* Byte alignment required. */
xWantedSize += ( portBYTE_ALIGNMENT - ( xWantedSize & portBYTE_ALIGNMENT_MASK ) );
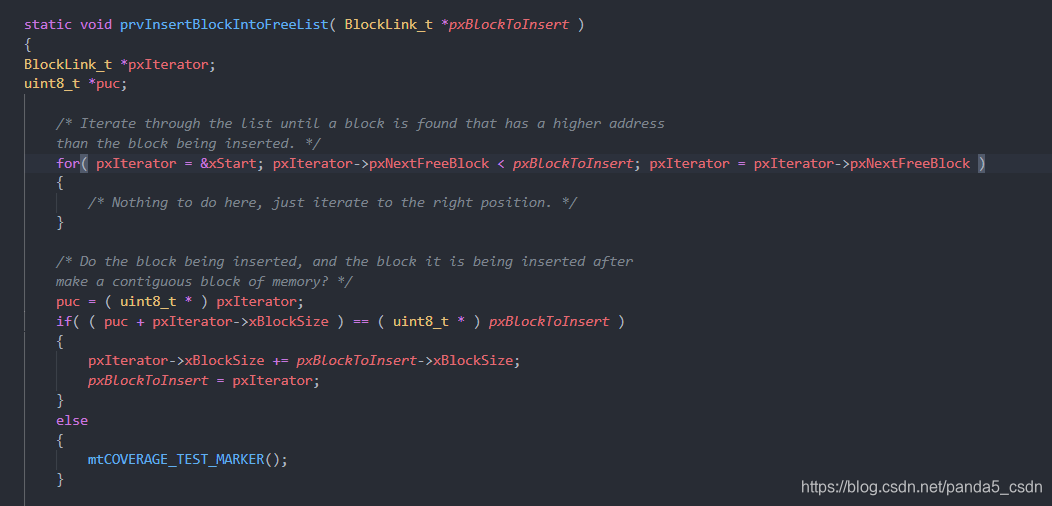
2. 内存合并算法
3. 链表设计
关于heap_4和heap_2的链表设计,我觉得很精妙。
heap_2中的static BlockLink_t xStart, xEnd;,这样设计很好理解,用2个结构体代表头尾,不占用内存空间;
而heap_4中是 static BlockLink_t xStart, *pxEnd = NULL;,这里的pxEnd和上面的不太一样,而且占用了堆空间。但是这里的好处是为了适配heap_5的,因为heap_5需要支持多块不连续的内存,有了这个pxEnd链表后,可以直接将这个链表指向下一个非连续的内存中,很方便。

















 5780
5780

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









