







一、特点
- 大多数现存的深度学习配准方法需要有ground-truth的训练数据,而这些数据的ground-truth是很难准确获取的。
- 多分辨率图像配准
- fully convolutional networks (FCNs)
1.为什么不用基本ground-truth的方法? 因为基于ground-truth的方法,网络学习出来的变换局限于数据集本身的变换类型。降低学习出来的网络配准效果的鲁棒性
2.为什么要用多分辨率 因为针对大的变形,单一分辨率下图像配准的效果较差。多分辨率能增加图像变换程度。
二、Method
本文的框架如下图所示:
基于深度学习的配准:网络输出是变形场V,用V对Moving Image进行变换(重采样),然后得到warped Moving Image。损失函数定义为:warped moving image 和 Fixed Image的相似性程度。这样就可以通过训练网络使损失函数越小,来优化配准过程,从而使配准效果越好。
每一个regression layer (Reg)的输出大小和输入图像大小相同。相当于对一个voxel预测一个偏移矢量。 CNNs通常采用池化操作来获取平移不变的特征,增加感受野,降低feature map的维度,降低计算成本。要想得到与原来相同图像大小就需要进行插值。所以作者采用采用反卷积算子进行上采样。

可以看到网络的输入是Moving image and Fixed Image。loss 是多级loss。其中在不同的网络部分计算一个
Dvloss。其中网络的回归输出(reg)用卷积来模拟回归输出。回归层的输出大小和输入图像大小一样。分别对应三个方向上的偏移。文章中也用了正则化计数,主要是为了对预测的Dv进行正则。
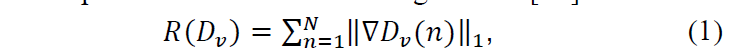
where 𝑁 is the number of pixel/voxels in the deformation field.把配准可以用下图中的公式(2)表示。

在本文中提到的多尺度配准就是网络不同的位置引出一个loss,分别预测一个变形场,然后用于配准图像。然后三个地方分别计算一个NCC(normalized cross-correlation)损失和正则化项。这就是总Loss的组成。
相似性度量:采用normalized cross-correlation (NCC-归一化交叉相关)作为损失函数的一部分。至于为什么采用这个,可能和作者做的医学图像的模态是MR图像有关,因为很多文章都说不同模态采用的相似性度量是不一样的(但是也没人说哪种模态该用哪种相似性度量函数)--瞎猜的!
多分辨率损失:Loss = Loss1 + 0.6Loss2 + 0.3Loss3
三、Experiments
本文中用到的数据集:LPBA40 dataset


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









