









ABSTRACT
多时相遥感图像被广泛应用于军事和民用领域,比如地面目标识别、城市发展评估以及地理变化评估。地面变化对特征点在数量和质量上的检测具有一定的挑战,这是基于特征点检测的配准算法所面临的常见的困难。在严峻的外观变化下,检测到的特征点可能包含大量的外点,而内点可能也分布不适当且不均匀。本文提出了一种基于卷积神经网络(CNN)特征的多时相遥感图像配准方法,两个关键的贡献如下:(1)我们使用CNN生成强大的多尺度特征描述符(2)我们设计了逐渐增加的内点选择,以提高特征点配准的鲁棒性。在多时相卫星图像数据集和多时相无人驾驶飞行器图像数据集上,我们进行了大量的实验,实验结果表明:在大多数情况下,我们的方法优于四种最先进的方法。
一 INTRODUCTION
图像配准是找到图像之间最佳对齐的过程。这是一项基本的任务,以便能够集成和比较从不同视角、不同时间或不同传感器获取的图像。多时相遥感图像被广泛应用于军事和民用领域,比如地面目标识别、城市发展评估以及地理变化评估。
图像配准能够分为两种主要的类型:(1)基于区域的方法(2)基于特征的方法。不同于直接使用图像强度值(基于区域的方法),基于特征的方法使用表示高级信息的特征描述符,因此在多时相分析中更倾向于选择外观变化是可以预计到的【6】。由于我们主要致力于研究基于特征的方法,因此我们介绍和讨论当前的方法(2)。
大多数基于特征的方法都依赖于SIFT【7】或改进版本来检测特征点,由于它具有尺度不变性以及旋转不变性【8】-【11】。然而,在多时相或多传感器图像配准中存在一定程度的外观差异的地方。SIFT检测出的特征点会也许会包含严重外点。在更糟糕的情况下,SIFT无法检测到足够的数量特征点。 这些问题限制了图像配准的应用。
在这项工作中,我们提出了一种新颖的非刚性图像配准方法。我们的两项重要贡献总结如下:(1)我们使用来自预训练的VGG [12]网络的层生成多尺度特征描述符。针对卷积神经网络在图像配准中的有效利用,我们的特征利用高级卷积信息,同时保留了一些定位能力。(2)我们设计了与提取的特征一致性工作的点集配准。在配准的早期阶段,粗略的形变由最可靠的特征点快速确定。之后,通过增加特征点的数量来优化配准细节,同时限制不匹配。通过卷积特征和几何结构信息来评估逐点对应。
我们将我们的特征检测方法与SIFT进行比较。我们的图像配准算法在多时相卫星图像和无人机图像进行测试,与四个最好的工作进行对比。我们通过测量特征预匹配的精度来比较特征检测方法。配准的性能评估通过度量相一致像素点之间的距离来实现。本文的其余部分安排如下:第2部分回顾了基于特征的配准问题的经典和前沿研究。 第3节介绍了我们工作的详细方法。 第4节展示了我们的实验。 结论见第5节。
二 RELATED WORKS
基于特征的图像配准算法通常包含四个步骤。
1)使用诸如SIFT [7]之类的特征描述符在一对图像(即,感测和参考图像)中检测到足够数量的特征点。
2)通过查找特征空间中的最近邻居(我们称之为特征预匹配)来估计初步的逐点对应关系。
3)非刚性点集配准,用来搜索最佳转换参数。
4)图像转换,重新采样根据恢复的转换得到的感知的图像
三 METHOD
A.SOLUTION FRAMEWORK
该算法的目标是对感知图像IY进行变换,使其与参考图像IX对齐。我们从参考图像中检测特征点集X,并从感测到的图像中检测特征点集Y.接下来,我们使用基于期望最大化(EM)的过程来获得Y的变换位置,即Z.然后使用Y和Z来求解用于图像变换的薄板样条(TPS)插值。我们方法的主要过程在图1中。

在整篇论文中,我们使用以下符号:
-
分别从参考图像和感测图像中提取的特征点集。
- Z-Y改变后的位置。
- N,M-X和Y分别的点的数量。
点集X中点的下标,点集Y中点的下标。
B FEATURE DESCRIPTION AND PREMATCHING
1)GENERATING FEATURE DESCRIPTORS
我们的卷积特征描述符是使用预训练的VGG-16 [12]网络中某些层的输出构建的,这是一个对1000个类别进行分类的图像分类网络。选用VGG是因为其有如下特性:(1)其卓越的图像分类性能证明了其分辨能力。(2)它结构简洁,仅通过堆叠卷积,池化层和全连接层构建,而没有采用分支或快捷连接来增强梯度流。 这种设计使得该网络适用于不同的目的。(3)网络层次神,经过大量多样化图像数据训练。VGG经常用于许多计算机视觉解决方案中的特征提取,例如fast-RCNN [51]物体探测器和超分辨率生成对抗网络(SRGAN)[52]。
基于卷积滤波器的可视化和使用单层输出作为特征的误差实验,已选择多个网络层来构建我们的特征描述符。我们主要考虑卷积滤波器的普遍性和选择层时的感受域大小。神经网络中的卷积层包含各种小滤波器,并且每个滤波器在输入图像中搜索特定模式。通过在使用随机值生成的输入图像上应用梯度上升[53],可视化VGG-16的每个卷积层中的滤波器。我们选择使用在Imagenet数据集[54]上训练的VGG网络,以便我们的特征描述符搜索通用的模式。图3显示了代表性的可视化滤波器。pool5层不用于特征提取,因为它受特定分类对象的影响,因此不适合检测一般特征。

由于我们只使用卷积层来提取特征,因此输入图像可以是任何大小,只要高度和宽度是32的倍数即可。但是,输入图像的大小可能有两个方面的影响:(1)每个描述符的感受域将是不同的并且影响性能。(2)较大的输入图像需要更多的计算。在把图像输入到网络之前,我们将输入图像的大小调整为224 * 224,以便具有适当大小的感受野和减少计算量。三层的输出用于构建我们的特性:pool3,pool4和block5conv1之后添加的最大池化层,即pool5_1。这些层搜索一组通用模式,产生的特征响应值,可以很好地覆盖不同大小的感受野。
正如图像2所示:VGG-16包含5个卷积计算块,每个块具有2-3个卷积层和每个块末尾的最大池化层。我们在输入图像上划分一个28 * 28网格划分我们的块,每个块对应于pool3输出中的256维向量,每8 * 8平方生成一个描述符。每个块的中心被视为特征点。256-d向量被定义为pool3特征描述符。 pool3层输出直接形成我们的pool3特征映射F1,其大小为28 * 28 * 256。 pool4层输出(大小为14 * 14 * 512)的处理方式略有不同。 在每个16 * 16区域中,我们生成一个pool4描述符,因此它由4个特征点共享。如公式1所示,pool4特征映射F2为使用Kronecker公式获得(用表示):
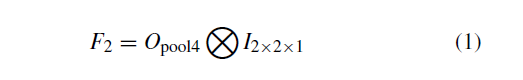
Opool4代表pool4层的输出。 I表示张量下标形状并填充1。
pool5_1层输出大小为7 * 7 * 512。 类似地,每个pool5_1描述符由16个特征点共享。
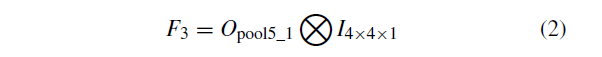

特征描述符的分布如图4所示。

表示pool4描述符,每个描述符由4个特征点共享。 青色点表示由5个特征点共享的pool5_1描述符。
在获取F1,F2和F3之后,使用特征映射将特征映射归一化为单位方差
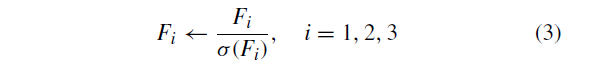
其中计算矩阵中元素的标准差。 point x的pool3,pool4和pool5_1描述符分别由D1(x),D2(x)和D3(x)表示。
2)特征预匹配
我们首先定义我们的特征的距离度量。 两个特征点x和y之间的距离是三个距离值的加权和。
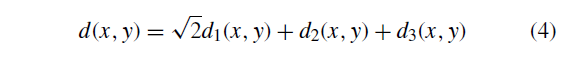
每个分量距离值是各个特征描述符之间的欧几里德距离。
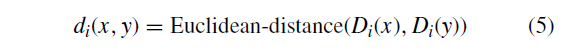
用pool3描述符d1(x; y)计算的距离的权重系数是根号2,因为D1是256-d而D2和D3是512-d。
如果满足以下条件,则特征点x与y匹配:
1)d(x,y)在所有d(.,y)中是最小的。
2)不存在d(z,y)<d(z,y),
是一个大于1的参数,称为匹配阈值。
匹配算法不满足双射。
C. DYNAMIC INLIER SELECTION
我们的特征点是在方形图像块的中心生成的。在变形的情况下,相应的特征点可以使它们的图像块部分或完全重叠。因此为了得到更准确的配准,重叠比例较大的特征点应具有更好的对齐。部分重叠的块中心之间应该距离要小。使用我们的动态内点选择确定对齐程度。
使用EM算法迭代求解Z(每次迭代中Y的变换位置),我们在每k次迭代中更新内点的选择。选择作为内点的点引导点位置的移动,而外点则连贯地移动。在特征预匹配阶段,使用低阈值选择大量特征点以过滤掉不相关的点。然后我们指定一个大的起始阈值
,只有内点(重叠块的特征点)才能满足。在配准过程的其它部分中,每k次迭代将阈值
减去一个步长
,允许更多的特征点来影响转换。这种方法使得强匹配的特征点能够确定整体变换,而其他特征点可以优化配准精度。
内部选择产生M * N先验概率矩阵PR,然后由我们的基于高斯混合模型(GMM)的变换求解器获取。矩阵中的数值代表和
相对应的推定概率。假设
对应于
,我们得到一个大的推定概率PR [m;n]。 并且很大的概率将进一步导致ym的显著变换,通过该变换可以配准相对应的点对。使用卷积特征和几何结构信息确定推定的概率。通过以下过程获得先验概率矩阵PR:
1)通过如下公式得到卷积特征成本矩阵
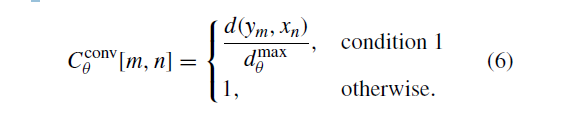
条件1是当在阈值,
和
是有效匹配。
是我们之前定义的卷积特征的距离度量。
是在阈值
下,是所有匹配的特征点的最大距离。
2)计算使用形状上下文[55] 的几何结构成本矩阵,这是一个基于直方图的描述符,用于描述一个点的邻域结构。描述符将轮廓点放置在极坐标系的中心,并记录落在弧形箱中的点数。
将由
测试得到。
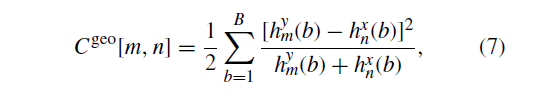
其中和
分别表示在围绕
和
的第b个bin中落下的点数。
3) 和
的值都在【0,1】之间,C由阿达玛变换得到。公式如下:

4) 我们应用Jonker-Volgenant算法[56]来解决成本矩阵C上的线性分配。分配的点对被认为是推定对应的。最后,我们使用下面公式计算先验概率矩阵:

是一个值在【0,1】之间的超参数,由我们内点选择的确信度来准确选择。先验概率矩阵需要归一化:
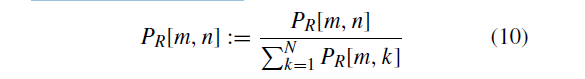
阈值的步长由确定.
D. MAIN PROCESS
我们将点集Y视为高斯混合模型(GMM)质心。 定义GMM概率密度函数为:
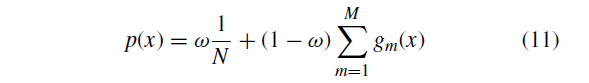
是正太分布密度函数:
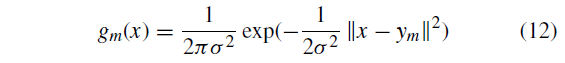
该模型对混合物中的每个高斯质心使用各向同性方差。另一个均匀分布项
被添加用来对外点用一个权重参数
进行解释,
。
我们使用EM算法找到最佳变换参数,这种方法的目的是最大化似然函数,或等效地最小化负对数似然函数:
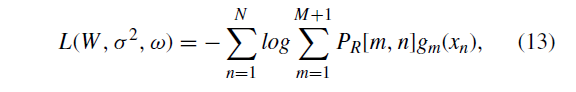
由于存在不可观察的变量m,我们无法直接计算梯度。 另外,EM算法最小化负对数似然函数的期望:
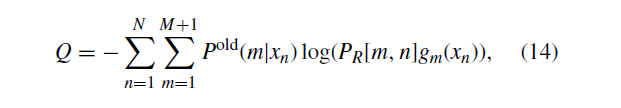
表示使用来自最后一次迭代的参数计算的后验概率项。 在扩展该等式并省略派生冗余项之后,该等式可以重写为:
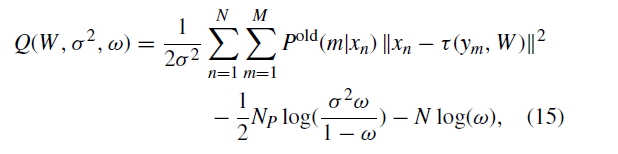
和
表示
的变换位置。
非刚性转换定义为:

其中G是由高斯径向基函数(GRBF)生成的矩阵,W包含要学习的变换参数。
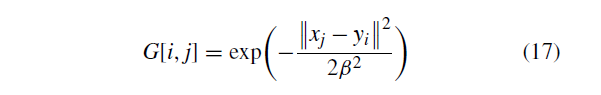
我们得到了一个基于运动相干理论(MCT)[57]的正则化项:
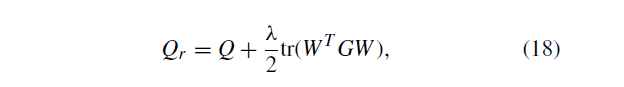
其中tr代表迹操作。
EM算法迭代地计算期望和最小化梯度直到收敛。
E步骤:使用来自最后一次迭代的参数计算后验概率矩阵。
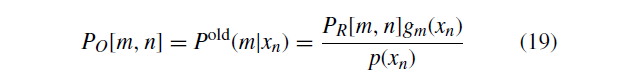
M步骤:求解导数并更新参数。

.1表示填充为1的列向量。
E. IMPLEMENTATION DETAILS
- 参数设置
在特征预匹配阶段,阈值通过选择最可靠的128对特征点自动决定的。同样,
通过选择64对特征点得到。在内点选择步骤,步长
由公式
得到。置信参数
=0.5。形状上下文在径向上使用5个箱,在切线方向上使用12个箱。在点集配准阶段,annealing constant
设定为0:95; 高斯径向基方差
设定为2。
- 初始化
输入图像的尺寸被调整为224*224,外点平衡权重参数被设置为0.5,
为2。变换系数W被初始化为值为0的矩阵。GMM方差
使用以下方式初始化:
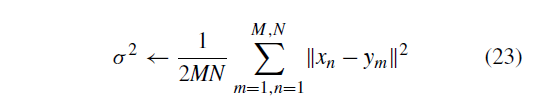
- 计算损失
单个224 * 224图像的特征计算需要13.45B FLOPs。 在2.9GHz双核Intel i5 CPU上,这需要1.2秒。 在求解矩阵时,我们得到最差的成本时间O(N3)。 权重矩阵W具有N*N个值,每个值需要N次迭代来计算,因此,复杂性是O(
)。 总的来说,点集配准具有O(
)复杂度。
F. PSEUDOCODE
我们在算法1中总结了多时相遥感图像配准的方法。

四. 实验
我们的工作表现在多时相卫星图像数据集和多时相无人机图像数据集上进行测试。 我们将我们的特征描述符与SIFT进行比较 我们的图像配准方法针对四种基于SIFT的最新方法进行了测试:CPD [33],GLMDTPS [25],GL-CATE [17]和PRGLS [13]。
A. EXPERIMENT SETTING
进行了两种类型的实验。
1) FEATURE PREMATCHING PRECISION TEST
特征预匹配是图像配准的重要中间阶段,我们将卷积特征与SIFT进行比较。 在每对测试图像中,我们使用两种方法提取和预匹配特征点。 然后我们使用匹配的最可靠95-105对,度量公式为:。通过控制阈值来选择特征匹配对。
2) IMAGE REGISTRATION ACCURACY TEST
这种实验有不同方法得到的已经对齐的图像来实现。在每对感知和对齐图像中,测试时识别15对指定的界标点。测试器记录图像上的界标点的位置,并根据每对界标点之间的距离测量误差。误差度量是均方根距离(RMSD),平均绝对距离(MAD),距离中值(MED)和距离标准偏差(STD)。
3) DATASETS
上述两种类型的实验均在两个数据集上执行:(1)从Google Earth获取的多时相卫星图像数据集(2)使用具有CMOS相机的小型无人机(DJI Phantom 4 Pro)捕获的多时相无人机图像数据集; 每个数据集包括15对图像。图像的大小范围为600 * 400到1566 * 874.我们的数据集中的图像对包含显着的外观变化和轻微的错位,旋转或视角变化。
B. RESULTS OF FEATURE PREMATCHING PRECISION TEST
两个数据集的数值结果如表1所示。图5中显示了两个数据集中的特征预匹配的四个示例,展示了检测到的特征点位置,正确和不正确的匹配。结果表明,我们的方法产生比SIFT更正确的对应关系。 此外,我们的方法检测到的特征点在图像上更均匀地分布,因为我们的方法保证在每8*8的区域中只存在一个特征点。


C. RESULTS OF IMAGE REGISTRATION ACCURACY TEST
卫星图像数据集的数值结果如表2所示,无人机图像数据集的结果如表3所示。我们展示了图6中两个数据集中通过不同方法生成的配准图像的四个示例。结果表明,我们的方法在大多数情况下都能产生最佳性能,尤其是当图像对中的外观差异具有挑战性时。原因是卷积特征在外观变化情况下比SIFT更稳健,所有比较的方法都是基于SIFT。此外,GLMDTPS表现不尽如人意,因为这种方法强调一对一的对应关系,在存在外点的情况下不稳健。CPD使用统一分布对外点进行建模来解决这个问题,PRGLS表现良好,只有它受到类似几何邻域结构导致的可疑对应。GL-CATE超越其他三种方法,并在卫星图像数据集上表现最佳。 其缺点源于提取的特征点,其对多时相图像不够敏感。我们方法的相当好的准确性证明了我们的动态内点选择策略是使用了基于块的特征选取原则。




五. 结论
我们提出了一种基于特征的图像配准方法,两个关键贡献:(1)我们使用预训练的VGG网络构建基于卷积神经网络的特征提取方法。 针对卷积神经网络在图像配准中的有效利用,我们的特征描述符利用高级卷积信息保留一些定位功能。(2)我们提出了一种特征点配准方法,该方法使用逐渐扩大的内点选择机制,以便在配准的早期阶段通过最可靠的特征点快速确定粗略变换参数。 之后,通过增加特征点的数量来优化配准细节,同时限制不匹配。 与SIFT相比,在两个多时相数据集上进行的特征预匹配测试结果表明准确度有很大的提升,图像配准测试结果表明我们的方法在大多数情况下优于目前四种最先进的方法。















 1346
1346











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









