






一、https://blog.csdn.net/weixin_39357271/article/details/127066607?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-2-127066607-blog-131732474.235%5Ev38%5Epc_relevant_sort_base2&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-2-127066607-blog-131732474.235%5Ev38%5Epc_relevant_sort_base2&utm_relevant_index=5
二、官方自带YOLOv5的半自动标注方法
1、找到YOLOv5的detect.py文件,修改相应参数
(1)参数save-txt的末尾添加default = True,这个参数就是保存检测的标签文件。
parser.add_argument('--save-txt', action='store_true', help='save results to *.txt',default=True)
(2)参数nosave的的末尾添加default = True,这个参数是是否保存检测后图片,设置不保存。
parser.add_argument('--nosave', action='store_true', help='do not save images/videos',default=True)
接下来去找刚才的运行结果,一般默认保存在run/detect/文件夹下,存在一个labels文件,就是我们需要的标签文件。
2、对生成的标签文件使用IableImg进行微调
(1)、因为用初始权重得到的标签的坐标框信息可能存在一些误差,所以还需要进行手动微调,哈哈,是不是又回到了最开始的打标签的时候,这样其实已经能节约很多时间了。
(2)、将最开始测试图片和得到的labels文件夹放在一起,使用labelImg打开该文件夹。
打开labelImg之前,先在labels文件夹下手动创建一个classes.txt文件,里面写上你的类别名称,防止labelImg的闪退。
(3)、设置打开的图片文件夹,设置保存标签的文件夹,如下图

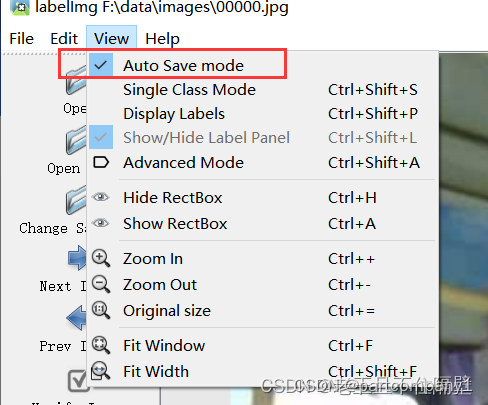
(4)、打开自动保存功能,如下图
3、保存下来的是txt文件,若在自己代码中想要数据增强,先转换为xml文件(这是由于数据增强代码使用的是xml文件格式)
txt-to-xml.py
# coding:gbk
# 将txt格式转换成xml格式数据集
from xml.dom.minidom import Document
import os
import cv2
def makexml(picPath, txtPath, xmlPath): # txt所在文件夹路径,xml文件保存路径,图片所在文件夹路径
"""此函数用于将yolo格式txt标注文件转换为voc格式xml标注文件
在自己的标注图片文件夹下建三个子文件夹,分别命名为picture、txt、xml
"""
# 创建字典用来对类型进行转换,要与classes.txt文件中的类对应,且顺序要一致
# dic = {'0': "vertical", '1': "horizontal",'2': "single"}
dic = {'0': "HanDian"}
files = os.listdir(txtPath)
for i, name in enumerate(files):
xmlBuilder = Document()
annotation = xmlBuilder.createElement("annotation") # 创建annotation标签
xmlBuilder.appendChild(annotation)
txtFile = open(txtPath + name)
txtList = txtFile.readlines()
img = cv2.imread(picPath + name[0:-4] + ".jpg") # 注意这里的图片后缀,.jpg/.png
Pheight, Pwidth, Pdepth = img.shape
folder = xmlBuilder.createElement("folder") # folder标签
foldercontent = xmlBuilder.createTextNode("datasetRGB")
folder.appendChild(foldercontent)
annotation.appendChild(folder)
filename = xmlBuilder.createElement("filename") # filename标签
filenamecontent = xmlBuilder.createTextNode(name[0:-4] + ".jpg")
filename.appendChild(filenamecontent)
annotation.appendChild(filename)
size = xmlBuilder.createElement("size") # size标签
width = xmlBuilder.createElement("width") # size子标签width
widthcontent = xmlBuilder.createTextNode(str(Pwidth))
width.appendChild(widthcontent)
size.appendChild(width)
height = xmlBuilder.createElement("height") # size子标签height
heightcontent = xmlBuilder.createTextNode(str(Pheight))
height.appendChild(heightcontent)
size.appendChild(height)
depth = xmlBuilder.createElement("depth") # size子标签depth
depthcontent = xmlBuilder.createTextNode(str(Pdepth))
depth.appendChild(depthcontent)
size.appendChild(depth)
annotation.appendChild(size)
for j in txtList:
oneline = j.strip().split(" ")
object = xmlBuilder.createElement("object") # object 标签
picname = xmlBuilder.createElement("name") # name标签
namecontent = xmlBuilder.createTextNode(dic[oneline[0]])
picname.appendChild(namecontent)
object.appendChild(picname)
pose = xmlBuilder.createElement("pose") # pose标签
posecontent = xmlBuilder.createTextNode("Unspecified")
pose.appendChild(posecontent)
object.appendChild(pose)
truncated = xmlBuilder.createElement("truncated") # truncated标签
truncatedContent = xmlBuilder.createTextNode("0")
truncated.appendChild(truncatedContent)
object.appendChild(truncated)
difficult = xmlBuilder.createElement("difficult") # difficult标签
difficultcontent = xmlBuilder.createTextNode("0")
difficult.appendChild(difficultcontent)
object.appendChild(difficult)
bndbox = xmlBuilder.createElement("bndbox") # bndbox标签
xmin = xmlBuilder.createElement("xmin") # xmin标签
mathData = int(((float(oneline[1])) * Pwidth + 1) - (float(oneline[3])) * 0.5 * Pwidth)
xminContent = xmlBuilder.createTextNode(str(mathData))
xmin.appendChild(xminContent)
bndbox.appendChild(xmin)
ymin = xmlBuilder.createElement("ymin") # ymin标签
mathData = int(((float(oneline[2])) * Pheight + 1) - (float(oneline[4])) * 0.5 * Pheight)
yminContent = xmlBuilder.createTextNode(str(mathData))
ymin.appendChild(yminContent)
bndbox.appendChild(ymin)
xmax = xmlBuilder.createElement("xmax") # xmax标签
mathData = int(((float(oneline[1])) * Pwidth + 1) + (float(oneline[3])) * 0.5 * Pwidth)
xmaxContent = xmlBuilder.createTextNode(str(mathData))
xmax.appendChild(xmaxContent)
bndbox.appendChild(xmax)
ymax = xmlBuilder.createElement("ymax") # ymax标签
mathData = int(((float(oneline[2])) * Pheight + 1) + (float(oneline[4])) * 0.5 * Pheight)
ymaxContent = xmlBuilder.createTextNode(str(mathData))
ymax.appendChild(ymaxContent)
bndbox.appendChild(ymax)
object.appendChild(bndbox) # bndbox标签结束
annotation.appendChild(object)
f = open(xmlPath + name[0:-4] + ".xml", 'w')
xmlBuilder.writexml(f, indent='\t', newl='\n', addindent='\t', encoding='utf-8')
f.close()
if __name__ == "__main__":
picPath = "D:\\Users\\bj0905\\pycharmproject\\object_detection\\csharp+python\\yolov5-v6.1\\data\\AutoAnnotations\\HanDian\\preimage\\" # 图片所在文件夹路径,后面的\\一定要带上
txtPath = "D:\\Users\\bj0905\\pycharmproject\\object_detection\\csharp+python\\yolov5-v6.1\\data\\AutoAnnotations\\HanDian\\preimagelabeltxt\\" # txt所在文件夹路径,后面的\\一定要带上
xmlPath = "D:\\Users\\bj0905\\pycharmproject\\object_detection\\csharp+python\\yolov5-v6.1\\data\\AutoAnnotations\\HanDian\\preimagelabelxml\\" # xml文件保存路径,后面的\\一定要带上
makexml(picPath, txtPath, xmlPath)
再进行增强:
import xml.etree.ElementTree as ET
import os
import imgaug as ia
import numpy as np
import shutil
from tqdm import tqdm
from PIL import Image
from imgaug import augmenters as iaa
ia.seed(1)
def read_xml_annotation(root, image_id):
in_file = open(os.path.join(root, image_id))
# in_file = open(os.path.join(root, image_id))
tree = ET.parse(in_file)
root = tree.getroot()
bndboxlist = []
for object in root.findall('object'): # 找到root节点下的所有country节点
bndbox = object.find('bndbox') # 子节点下节点rank的值
xmin = int(bndbox.find('xmin').text)
xmax = int(bndbox.find('xmax').text)
ymin = int(bndbox.find('ymin').text)
ymax = int(bndbox.find('ymax').text)
# print(xmin,ymin,xmax,ymax)
bndboxlist.append([xmin, ymin, xmax, ymax])
# print(bndboxlist)
bndbox = root.find('object').find('bndbox')
return bndboxlist
def change_xml_list_annotation(root, image_id, new_target, saveroot, id):
in_file = open(os.path.join(root, str(image_id) + '.xml')) # 这里root分别由两个意思
tree = ET.parse(in_file)
# 修改增强后的xml文件中的filename
elem = tree.find('filename')
elem.text = (str(id) + '.jpg')
xmlroot = tree.getroot()
# 修改增强后的xml文件中的path
elem = tree.find('path')
if elem != None:
elem.text = (saveroot + str(id) + '.jpg')
index = 0
for object in xmlroot.findall('object'): # 找到root节点下的所有country节点
bndbox = object.find('bndbox') # 子节点下节点rank的值
# xmin = int(bndbox.find('xmin').text)
# xmax = int(bndbox.find('xmax').text)
# ymin = int(bndbox.find('ymin').text)
# ymax = int(bndbox.find('ymax').text)
new_xmin = new_target[index][0]
new_ymin = new_target[index][1]
new_xmax = new_target[index][2]
new_ymax = new_target[index][3]
xmin = bndbox.find('xmin')
xmin.text = str(new_xmin)
ymin = bndbox.find('ymin')
ymin.text = str(new_ymin)
xmax = bndbox.find('xmax')
xmax.text = str(new_xmax)
ymax = bndbox.find('ymax')
ymax.text = str(new_ymax)
index = index + 1
tree.write(os.path.join(saveroot, str(id + '.xml')))
def mkdir(path):
# 去除首位空格
path = path.strip()
# 去除尾部 \ 符号
path = path.rstrip("\\")
# 判断路径是否存在
# 存在 True
# 不存在 False
isExists = os.path.exists(path)
# 判断结果
if not isExists:
# 如果不存在则创建目录
# 创建目录操作函数
os.makedirs(path)
print(path + ' 创建成功')
return True
else:
# 如果目录存在则不创建,并提示目录已存在
print(path + ' 目录已存在')
return False
if __name__ == "__main__":
# IMG_DIR = "D:/Users/bj0905/pycharmproject/object_detection/data/data_enhance-test/JPEGImages/"
# XML_DIR = "D:/Users/bj0905/pycharmproject/object_detection/data/data_enhance-test/Annotations/"
IMG_DIR = "D:/Users/bj0905/pycharmproject/object_detection/csharp+python/yolov5-v6.1/data/AutoAnnotations/HanDian/1/preimage/"
XML_DIR = "D:/Users/bj0905/pycharmproject/object_detection/csharp+python/yolov5-v6.1/data/AutoAnnotations/HanDian/1/preimagelabelxml/"
# AUG_XML_DIR = "D:/Users/bj0905/pycharmproject/object_detection/data/data_enhance-test/Annotations-enhance/" # 存储增强后的XML文件夹路径
AUG_XML_DIR = "D:/Users/bj0905/pycharmproject/object_detection/csharp+python/yolov5-v6.1/data/AutoAnnotations/HanDian/1/preimage_enhance/Annotations-AUTO/" # 存储增强后的XML文件夹路径"/"不能少
try:
shutil.rmtree(AUG_XML_DIR)
except FileNotFoundError as e:
a = 1
mkdir(AUG_XML_DIR)
# AUG_IMG_DIR = "D:/Users/bj0905/pycharmproject/object_detection/data/data_enhance-test/JPEGImages-enhance/" # 存储增强后的影像文件夹路径
AUG_IMG_DIR = "D:/Users/bj0905/pycharmproject/object_detection/csharp+python/yolov5-v6.1/data/AutoAnnotations/HanDian/1/preimage_enhance/JPEGImages-AUTO/" # 存储增强后的影像文件夹路径
try:
shutil.rmtree(AUG_IMG_DIR)
except FileNotFoundError as e:
a = 1
mkdir(AUG_IMG_DIR)
AUGLOOP = 6 # 每张影像增强的数量
boxes_img_aug_list = []
new_bndbox = []
new_bndbox_list = []
# 影像增强
seq = iaa.Sequential([
# iaa.Invert(0.5), #灰度处理
iaa.Flipud(0.5), # 只有50%的概率执行上下翻转
iaa.Fliplr(0.5), # 镜像
# 随机裁剪图片边长比例的0~0.1
iaa.Crop(percent=(0, 0.1)),
# 让一些图片变的更亮,一些图片变得更暗
# 对20%的图片,针对通道进行处理
# 剩下的图片,针对图片进行处理
# iaa.Multiply((0.8, 1.2), per_channel=0.2),
# iaa.Multiply((1.2, 1.5)), # change brightness, doesn't affect BBs
# iaa.GaussianBlur(sigma=(0, 3.0)), # iaa.GaussianBlur(0.5),
iaa.Affine(
translate_px={"x": 15, "y": 15}, # 平移
scale=(0.8, 0.95), # 尺度变换
# 旋转
rotate=(-8, 8),
# rotate=(-25, 25),
# 剪切
# shear=(-8, 8)
), # translate by 40/60px on x/y axis, and scale to 50-70%, affects BBs
# iaa.Affine(
# translate_px={"x": 22, "y": 22}, # 平移
# scale=(1.1, 1.1), # 尺度变换
# # 旋转
# rotate=(-12, 12),
# # rotate=(-25, 25),
# # 剪切
# # shear=(-8, 8)
# ),
iaa.Affine(
translate_px={"x": 8, "y": 8}, # 平移
scale=(1.15, 1.15), # 尺度变换
# 旋转
rotate=(-4, 4),
# rotate=(-25, 25),
# 剪切
# shear=(-8, 8)
),
iaa.Affine(
translate_px={"x": 20, "y": 20}, # 平移
scale=(0.95, 0.95), # 尺度变换
# 旋转
rotate=(-15, 15),
# rotate=(-25, 25),
# 剪切
# shear=(-8, 8)
)
])
for name in tqdm(os.listdir(XML_DIR), desc='Processing'):
bndbox = read_xml_annotation(XML_DIR, name)
# 保存原xml文件
shutil.copy(os.path.join(XML_DIR, name), AUG_XML_DIR)
# 保存原图
og_img = Image.open(IMG_DIR + '/' + name[:-4] + '.jpg')
og_img.convert('RGB').save(AUG_IMG_DIR + name[:-4] + '.jpg', 'JPEG')
og_xml = open(os.path.join(XML_DIR, name))
tree = ET.parse(og_xml)
# 修改增强后的xml文件中的filename
elem = tree.find('filename')
elem.text = (name[:-4] + '.jpg')
tree.write(os.path.join(AUG_XML_DIR, name))
for epoch in range(AUGLOOP):
seq_det = seq.to_deterministic() # 保持坐标和图像同步改变,而不是随机
# 读取图片
img = Image.open(os.path.join(IMG_DIR, name[:-4] + '.jpg'))
# sp = img.size
img = np.asarray(img)
# bndbox 坐标增强
for i in range(len(bndbox)):
bbs = ia.BoundingBoxesOnImage([
ia.BoundingBox(x1=bndbox[i][0], y1=bndbox[i][1], x2=bndbox[i][2], y2=bndbox[i][3]),
], shape=img.shape)
bbs_aug = seq_det.augment_bounding_boxes([bbs])[0]
boxes_img_aug_list.append(bbs_aug)
# new_bndbox_list:[[x1,y1,x2,y2],...[],[]]
n_x1 = int(max(1, min(img.shape[1], bbs_aug.bounding_boxes[0].x1)))
n_y1 = int(max(1, min(img.shape[0], bbs_aug.bounding_boxes[0].y1)))
n_x2 = int(max(1, min(img.shape[1], bbs_aug.bounding_boxes[0].x2)))
n_y2 = int(max(1, min(img.shape[0], bbs_aug.bounding_boxes[0].y2)))
if n_x1 == 1 and n_x1 == n_x2:
n_x2 += 1
if n_y1 == 1 and n_y2 == n_y1:
n_y2 += 1
if n_x1 >= n_x2 or n_y1 >= n_y2:
print('error', name)
new_bndbox_list.append([n_x1, n_y1, n_x2, n_y2])
# 存储变化后的图片
image_aug = seq_det.augment_images([img])[0]
path = os.path.join(AUG_IMG_DIR,
str(str(name[:-4]) + '_' + str(epoch)) + '.jpg')
image_auged = bbs.draw_on_image(image_aug, size=0)
Image.fromarray(image_auged).convert('RGB').save(path)
# 存储变化后的XML
change_xml_list_annotation(XML_DIR, name[:-4], new_bndbox_list, AUG_XML_DIR,
str(name[:-4]) + '_' + str(epoch))
# print(str(str(name[:-4]) + '_' + str(epoch)) + '.jpg')
new_bndbox_list = []
print('Finish!')
训练:
训练时JPEGImages放图像文件,Annotations放标注的xml文件,之后运行data-spilt.py进行数据划分(训练集和验证集),数据集划分时新建一个images图像,将JPEGImages图像拷贝进去,images地址填在name = ‘D:/Users/bj0905/pycharmproject/object_detection/csharp+python/yolov5-v6.1/data/images/’ + total_xml[i][:-4] + ‘.jpg’ '\n’变量中,
data-spilt.py
# coding:utf-8
import os
import random
import argparse
parser = argparse.ArgumentParser()
# xml文件的地址,根据自己的数据进行修改 xml一般存放在Annotations下
parser.add_argument('--xml_path', default='Annotations-AUTO-HanDian', type=str, help='input xml label path')
# 数据集的划分,地址选择自己数据下的ImageSets/Main
parser.add_argument('--txt_path', default='ImageSets/Main', type=str, help='output txt label path')
opt = parser.parse_args()
trainval_percent = 1.0
train_percent = 0.9
xmlfilepath = opt.xml_path
txtsavepath = opt.txt_path
total_xml = os.listdir(xmlfilepath)
if not os.path.exists(txtsavepath):
os.makedirs(txtsavepath)
num = len(total_xml)
list_index = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list_index, tv)
train = random.sample(trainval, tr)
file_trainval = open(txtsavepath + '/trainval.txt', 'w')
file_test = open(txtsavepath + '/test.txt', 'w')
file_train = open(txtsavepath + '/train.txt', 'w')
file_val = open(txtsavepath + '/val.txt', 'w')
for i in list_index:
# name = 'D:/Users/bj0905/pycharmproject/object_detection/csharp+python/yolov5-v6.1/data/images/' + total_xml[i][:-4] + '.jpg' '\n'
name = 'D:/Users/bj0905/pycharmproject/object_detection/csharp+python/yolov5-v6.1/data/images/' + total_xml[i][:-4] + '.jpg' '\n'
if i in trainval:
file_trainval.write(name)
if i in train:
file_train.write(name)
else:
file_val.write(name)
else:
file_test.write(name)
file_trainval.close()
file_train.close()
file_val.close()
file_test.close()
运行得到ImageSets文件夹:
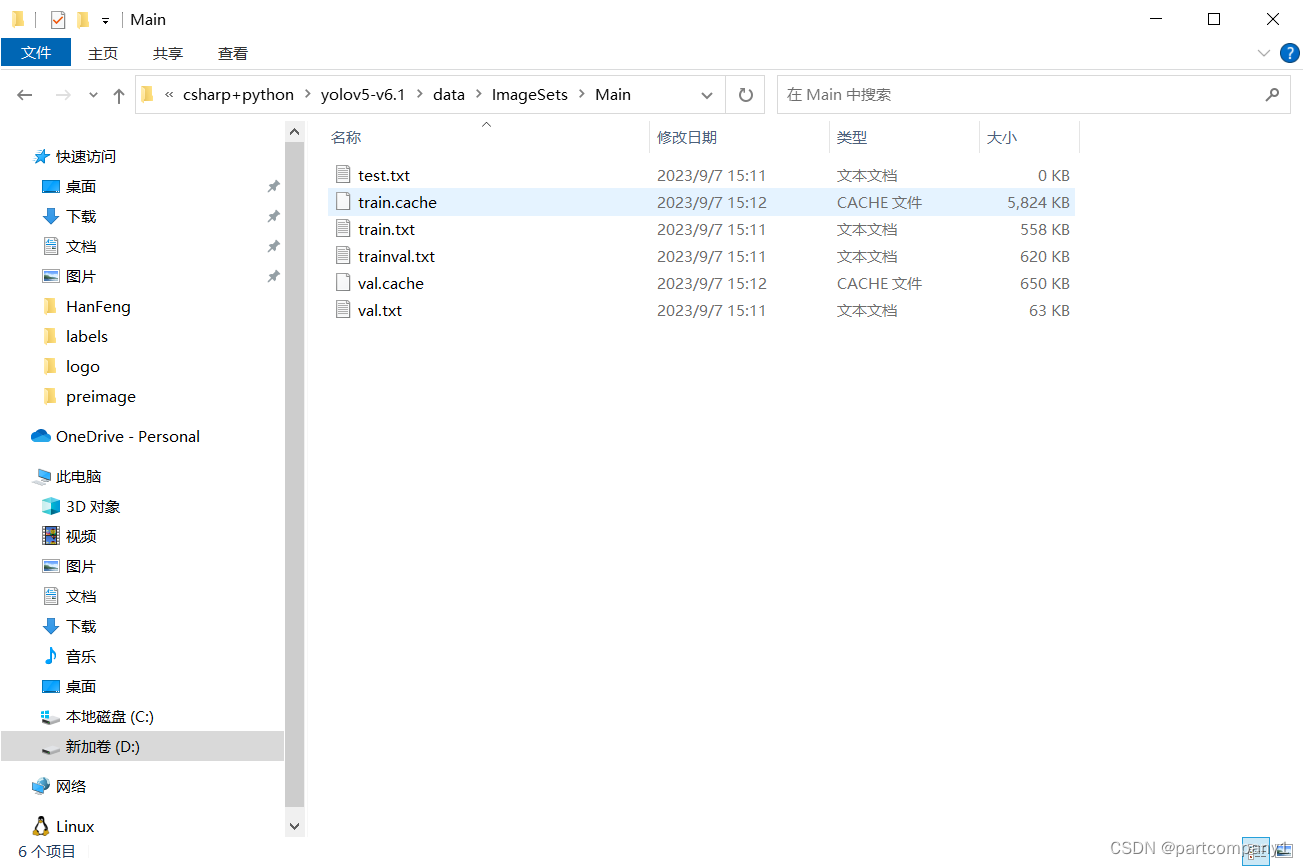
之后再将Annotations文件中的xml标注文件转换为txt文件,放在labels文件夹中:
xml-to-txt.py
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
# 数据标签
classes = ['HanDian'] # 需要修改
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
if w >= 1:
w = 0.99
if h >= 1:
h = 0.99
return (x, y, w, h)
def convert_annotation(rootpath, xmlname):
xmlpath = rootpath + '/Annotations-AUTO-HanDian'
xmlfile = os.path.join(xmlpath, xmlname)
with open(xmlfile, "r", encoding='UTF-8') as in_file:
txtname = xmlname[:-4] + '.txt'
print(txtname)
txtpath = rootpath + '/labels' # 生成的.txt文件会被保存在labels目录下
if not os.path.exists(txtpath):
os.makedirs(txtpath)
txtfile = os.path.join(txtpath, txtname)
with open(txtfile, "w+", encoding='UTF-8') as out_file:
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
out_file.truncate()
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
rootpath = 'D:\\Users\\bj0905\\pycharmproject\\object_detection\\csharp+python\\yolov5-v6.1\\data' ##需要修改的地方改成你的路径
# 修改前面的标签名
xmlpath = rootpath + '\\Annotations' #这就是xml的路径
list = os.listdir(xmlpath)
for i in range(0, len(list)):
path = os.path.join(xmlpath, list[i])
if ('.xml' in path) or ('.XML' in path):
convert_annotation(rootpath, list[i])
print('done', i)
else:
print('not xml file', i)
最后得到images以及labels和ImageSets文件夹就可以进行训练了。















 2544
2544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









