







dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open(img_path+‘Annotations/%s.xml’ % (image_id), encoding=‘UTF-8’)
out_file = open(img_path’labels/%s.txt’ % (image_id), ‘w’)
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find(‘size’)
w = int(size.find(‘width’).text)
h = int(size.find(‘height’).text)
for obj in root.iter(‘object’):
difficult = obj.find(‘difficult’).text
# difficult = obj.find(‘Difficult’).text
cls = obj.find(‘name’).text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find(‘bndbox’)
b = (float(xmlbox.find(‘xmin’).text), float(xmlbox.find(‘xmax’).text), float(xmlbox.find(‘ymin’).text),
float(xmlbox.find(‘ymax’).text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + ‘\n’)
wd = getcwd()
for image_set in sets:
if not os.path.exists(img_path+‘labels/’):
os.makedirs(img_path+‘labels/’)
image_ids = open(img_path+‘ImageSets/Main/%s.txt’ % (image_set)).read().strip().split()
if not os.path.exists(img_path+'dataSet\_path/'):
os.makedirs(img_path+'dataSet\_path/')
list_file = open('dataSet\_path/%s.txt' % (image_set), 'w')
# 这行路径不需更改,这是相对路径
for image\_id in image_ids:
list_file.write(img_path+'images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
然后运行:
(yolov5) PS G:\bsh\yolov5\yolov5-master\datavivoimg> python .\text_to_yolo.py
#如果运行成功,会输出如下代码:
G:\bsh\yolov5\yolov5-master\datavivoimg
然后去查看
labels里边的标签和dataset\_path里的文件
## 3. yolov5训练得到模型文件
首先配置自己数据集的yaml文件:
在 yolov5 目录下的 data 文件夹下 新建一个 vivo.yaml文件(可以自定义命名),用记事本打开
内容如下,修改的时候注意空格问题,一定要严格按照格式来修改:
train: G:/bsh/yolov5/yolov5-master/datavivoimg/dataSet_path/train.txt
val: G:/bsh/yolov5/yolov5-master/datavivoimg/dataSet_path/val.txt
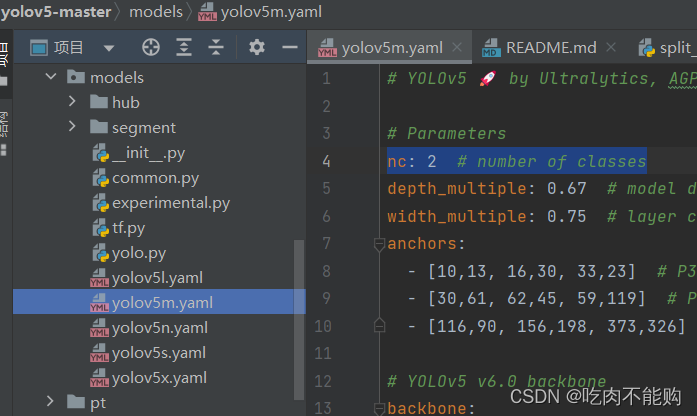
number of classes
nc: 2
class names
names: [“prince”, “garfield”]
然后注意,不需要修改yolov5的配置文件(这里不需要修改,其实上边的vivo.yaml里修改了numclass之后会自动覆盖)

然后进行训练
python train.py --weights pt/yolov5m.pt --cfg models/yolov5m.yaml --data data/vivo.yaml --epoch 200 --batch-size 6 --img 640
按照我的参数,我笔记本的gpu 1060,大概1-2个小时,挺快的。
如果训练报错缺少库要自己改一改,
例如我缺少了git库就去conda install git,
而且pillow库版本9.3过高不匹配,我就修改到pip install pillow==8.0
因为我batchsize=8报错memory异常,所以调小到6,然后开始训练:
训练结果如下:
YOLOv5m summary: 212 layers, 20856975 parameters, 0 gradients, 47.9 GFLOPs
Class Images Instances P R mAP50 mAP50-95: 100%|██████████| 1/1 [00:00<00:00, 2.40it/s]
all 8 8 0.933 1 0.995 0.651
prince 8 5 0.989 1 0.995 0.687
garfield 8 3 0.876 1 0.995 0.614
Results saved to runs\train\exp7
可以看到,36张图片,训练了200epoch就达到了99.5%的mAP,效果还是非常好的。
## 4. 使用detect.py自动标注
通过设置参数,打开detect.py,修改save–text 参数,值为’store\_false’

该参数的意思是是否保存检测后后的结果,如框的位置大小,框的物体类别。注意,store\_false才是保存检测的结果
运行语句:
python detect.py --weights .\runs\train\exp7\weights\prigarbest.pt --source .\datavivoimg\images\
就可以把images文件夹下的所有图像标注出来了。这是运行结束的效果:
image 197/200 G:\bsh\yolov5\yolov5-master\datavivoimg\images\IMG_20230719_230826_Burst17.jpg: 640x480 1 garfield, 34.0ms
image 198/200 G:\bsh\yolov5\yolov5-master\datavivoimg\images\IMG_20230719_230826_Burst18.jpg: 640x480 1 garfield, 34.0ms
image 199/200 G:\bsh\yolov5\yolov5-master\datavivoimg\images\IMG_20230719_230826_Burst19.jpg: 640x480 1 garfield, 34.0ms
image 200/200 G:\bsh\yolov5\yolov5-master\datavivoimg\images\IMG_20230719_230826_Burst20.jpg: 640x480 1 garfield, 34.0ms
Speed: 0.6ms pre-process, 35.1ms inference, 1.9ms NMS per image at shape (1, 3, 640, 640)
Results saved to runs\detect\exp5
200 labels saved to runs\detect\exp5\labels
然后去exp5中查看效果:
所有的图片都被标注了,labels统一存放了,可以把labels复制到dataset中去,进行以后的训练了,全文完结,撒花~


然后挨着打开标注好的图片对满意的图片进行保留,不想要就按del进行删除,最后使用choose.py进行对应标签的保留,其他的标签删掉
import os
指定exp72文件夹路径和labels文件夹路径
imgs_folder_path = ‘G:/bsh/yolov8/runs/detect/predict21/’
labels_folder_path = ‘G:/bsh/yolov8/runs/detect/predict21/labels’
获取exp72文件夹中的所有图片文件名(不含扩展名)
image_names = [os.path.splitext(file)[0] for file in os.listdir(imgs_folder_path) if file.endswith(‘.jpg’)]
image_names = [os.path.splitext(file)[0] for file in os.listdir(imgs_folder_path) if file.endswith(‘.bmp’)]
获取labels文件夹中的所有txt文件名
txt_files = [file for file in os.listdir(labels_folder_path) if file.endswith(‘.txt’)]
遍历labels文件夹中的txt文件
for txt_file in txt_files:
# 提取txt文件名(不含扩展名)
txt_file_name = os.path.splitext(txt_file)[0]
# 检查txt文件名是否在图片文件名列表中
if txt_file_name not in image_names:
# 不在图片文件名列表中的txt文件,删除
txt_file_path = os.path.join(labels_folder_path, txt_file)
os.remove(txt_file_path)
然后把留下的标签复制粘贴到数据集的labels文件夹里,这个时候需要重新分配训练集和验证集,需要运行split\_train\_val.py,这个时候注意:是把上边的路径修改以下:
意思就是从labels里便读取标签进行重新分配
#parser.add_argument(‘–xml_path’, default=‘G:/bsh/dataset/luosi/Annotations’, type=str, help=‘input xml label path’)
parser.add_argument(‘–xml_path’, default=‘G:/bsh/dataset/luosi/labels’, type=str, help=‘input xml label path’)
然后继续运行text\_to\_yolo.py,这里其实原作者写的不好,应该先转换格式再分配路径,以后有机会我改改。这里先不管了,继续运行,记得注释掉转换格式的代码(因为已经标注的就是yolo格式的txt,不需要再转换了)
注释后的代码长这样
-*- coding: utf-8 -*-
import xml.etree.ElementTree as ET
import os
from os import getcwd
dataAllPath = ‘G:/bsh/dataset/luosi/’
sets = [‘train’, ‘val’, ‘test’]
classes = [“yuanguojia”,“naiguojia”,“huanhuogai”,“dianchi”,“shuomingshu”,“paomoban”,“xiaohuogai”] # 改成自己的类别
classes = [“luosi”] # 改成自己的类别
print(dataAllPath)
使用detect.py产生的标签不需要进行转换
def convert(size, box):
dw = 1. / (size[0])
dh = 1. / (size[1])
x = (box[0] + box[1]) / 2.0 - 1
y = (box[2] + box[3]) / 2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return x, y, w, h
def convert_annotation(image_id):
in_file = open(dataAllPath+‘Annotations/%s.xml’ % (image_id), encoding=‘UTF-8’)
out_file = open(dataAllPath+‘labels/%s.txt’ % (image_id), ‘w’)
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find(‘size’)
w = int(size.find(‘width’).text)
h = int(size.find(‘height’).text)
for obj in root.iter(‘object’):
difficult = obj.find(‘difficult’).text
# difficult = obj.find(‘Difficult’).text
cls = obj.find(‘name’).text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find(‘bndbox’)
b = (float(xmlbox.find(‘xmin’).text), float(xmlbox.find(‘xmax’).text), float(xmlbox.find(‘ymin’).text),
float(xmlbox.find(‘ymax’).text))
b1, b2, b3, b4 = b
# 标注越界修正
if b2 > w:
b2 = w
if b4 > h:
b4 = h
b = (b1, b2, b3, b4)
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + ‘\n’)
wd = getcwd()
for image_set in sets:
if not os.path.exists(dataAllPath+‘labels’):
os.makedirs(dataAllPath+‘labels/’)
image_ids = open(dataAllPath+‘ImageSets/Main/%s.txt’ % (image_set)).read().strip().split()
if not os.path.exists(dataAllPath+'dataSet\_path/'):
os.makedirs(dataAllPath+'dataSet\_path/')
list_file = open(dataAllPath+'dataSet\_path/%s.txt' % (image_set), 'w')
# 这行路径不需更改,这是相对路径
for image\_id in image_ids:
# list\_file.write(dataAllPath+'images/%s.jpg\n' % (image\_id))
# list\_file.write(dataAllPath+'images/%s.bmp\n' % (image\_id))
list_file.write(dataAllPath+'images/%s.png\n' % (image_id))
# convert\_annotation(image\_id)
list_file.close()
然后就可以继续运行训练了,这个时候就完成了一次完整闭环的训练循环,用少数样本训练小模型,用小模型预测结果自动保存标签,人工筛选满意的结果进行保存,然后汇总到labels一起合并训练,如果不满意可以继续循环训练,直到达到满意的指标
完结撒花~~!
## 附录 遇到的错误
### 1.缺少pillow库
具体表现为运行detect.py报错:
(yolov5) PS G:\bsh\yolov5\yolov5-master> python detect.py --weights .\pt\yolov5m.pt --source .\demoimg
Traceback (most recent call last):
File “detect.py”, line 45, in
from models.common import DetectMultiBackend
File “G:\bsh\yolov5\yolov5-master\models\common.py”, line 24, in
from PIL import Image
File “F:\APP\miniconda\envs\yolov5\lib\site-packages\PIL\Image.py”, line 100, in
from . import _imaging as core
ImportError: DLL load failed while importing _imaging: 找不到指定的模块。
推测原因是pillow库是pip requirements自动安装的最新版本9.3.0,和我的pytorch不兼容,所以降级
pip install pillow==8.0
然后就可以运行了。
### 2.detect.py适用范围
官网的代码参数可以调用电脑摄像头等数据来源,供大家参考
python detect.py --weights yolov5s.pt --source 0 # webcam
img.jpg # image
vid.mp4 # video
screen # screenshot
path/ # directory
list.txt # list of images
list.streams # list of streams
‘path/*.jpg’ # glob
一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照下面的知识点去找对应的学习资源,保证自己学得较为全面。


二、Python必备开发工具
工具都帮大家整理好了,安装就可直接上手!
三、最新Python学习笔记
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。

四、Python视频合集
观看全面零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

五、实战案例
纸上得来终觉浅,要学会跟着视频一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
六、面试宝典


简历模板
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









