







题目仅含中文!!
视频链接:【中英字幕】吴恩达深度学习课程第三课 — 结构化机器学习项目
参考链接:
- 【中英】【吴恩达课后测验】Course 3 - 结构化机器学习项目 - 第一周测验
- 吴恩达《深度学习》-课后测验-第三门课 结构化机器学习项目(Structuring Machine Learning Projects)-Week1 Bird recognition in the city of Peacetopia (case study)( 和平之城中的鸟类识别(案例研究))
题目
问题陈述
这个例子来源于实际项目,但是为了保护机密性,我们会对细节进行保护。
现在你是和平之城的著名研究员,和平之城的人有一个共同的特点:他们害怕鸟类。为了保护他们,你必须设计一个算法,以检测飞越和平之城的任何鸟类,同时警告人们有鸟类飞过。市议会为你提供了10,000,000张图片的数据集,这些都是从城市的安全摄像头拍摄到的。它们被命名为:
- y = 0: 图片中没有鸟类
- y = 1: 图片中有鸟类
你的目标是设计一个算法,能够对和平之城安全摄像头拍摄的新图像进行分类。
有很多决定要做:
- 评估指标是什么?
- 你如何将你的数据分割为训练/开发/测试集?
问题1
市议会告诉你,他们想要一个算法:
- 拥有较高的准确度
- 快速运行,只需要很短的时间来分类一个新的图像。
- 可以适应小内存的设备,这样它就可以运行在一个小的处理器上,它将用于城市的安全摄像头上。
请注意: 有三个评估指标使您很难在两种不同的算法之间进行快速选择,并且会降低您的团队迭代的速度,是真的吗?
A.正确
B.错误
问题2
经过进一步讨论,市议会缩小了它的标准:
- “我们需要一种算法,可以让我们尽可能精确的知道一只鸟正飞过和平之城。”
- “我们希望经过训练的模型对新图像进行分类不会超过10秒。”
- “我们的模型要适应10MB的内存的设备.”
如果你有以下三个模型,你会选择哪一个?

问题3
根据城市的要求,您认为以下哪一项是正确的?
A.准确度是一个优化指标; 运行时间和内存大小是令人满意的指标。
B.准确度是一个令人满意的指标; 运行时间和内存大小是一个优化指标。
C.准确性、运行时间和内存大小都是优化指标,因为您希望在所有这三方面都做得很好。
D.准确性、运行时间和内存大小都是令人满意的指标,因为您必须在三项方面做得足够好才能使系统可以被接受。
问题4
结构化你的数据
在实现你的算法之前,你需要将你的数据分割成训练/开发/测试集,你认为哪一个是最好的选择?
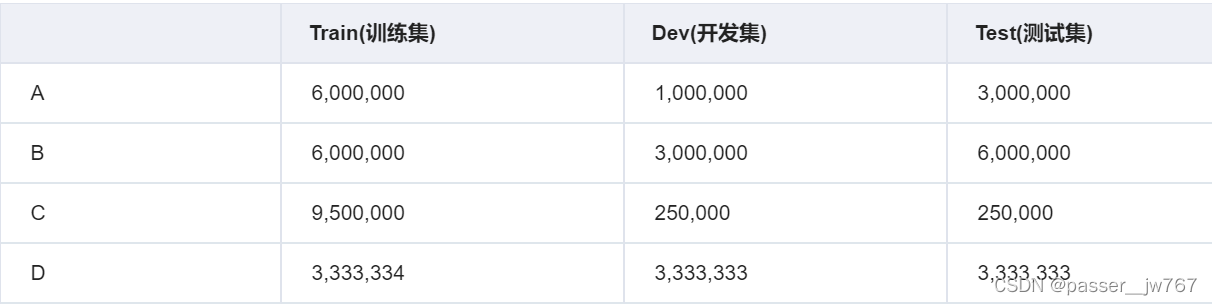
问题5
在设置了训练/开发/测试集之后,市议会再次给你了1,000,000张图片,称为“公民数据”。 显然,和平之城的公民非常害怕鸟类,他们自愿为天空拍照并贴上标签,从而为这些额外的1,000,000张图像贡献力量。 这些图像与市议会最初给您的图像分布不同,但您认为它可以帮助您的算法。
你不应该将公民数据添加到训练集中,因为这会导致训练/开发/测试集分布变得不同,从而损害开发集和测试集性能,是真的吗?
A.True
B.False
问题6
市议会的一名成员对机器学习知之甚少,他认为应该将1,000,000个公民的数据图像添加到测试集中,你反对的原因是:(多选)
A.这会导致开发集和测试集分布变得不同。这 是一个很糟糕的主意,因为这会达不到你想要的效果。
B.公民的数据图像与其他数据没有一致的 x- >y 映射(类似于纽约/底特律的住房价格例子)。
C.一个更大的测试集将减慢迭代速度,因为测试集 上评估模型会有计算开销。
D.测试集不再反映您最关心的数据(安全摄像头)的分布。(博主注:训练集是摄像头拍的,用他人拍的数据去测试摄像头拍的,势必会导致准确度下降,要添加也应该添加到整个数据集中,保证同一分布。)
问题7
你训练了一个系统,其误差度如下(误差度 = 100% - 准确度):

这表明,提高性能的一个很好的途径是训练一个更大的网络,以降低4%的训练误差。你同意吗?
A.是的,因为有4%的训练误差表明你有很高的偏差。
B.是的,因为这表明你的模型的偏差高于方差。
C.不同意,因为方差高于偏差。
D.不同意,因为没有足够的信息,这什么也说明不了。
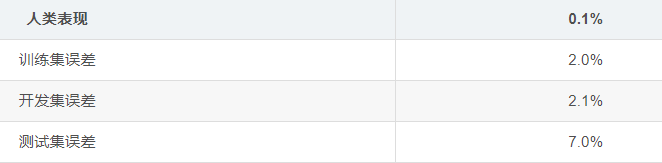
问题8
你让一些人对数据集进行标记,以便找出人们对它的识别度。你发现了准确度如下:

如果您的目标是将“人类表现”作为贝叶斯错误的基准线(或估计),那么您如何定义“人类表现”?
A.0.0% (因为不可能做得比这更好)
B.0.3% (专家1的错误率)
C.0.4% (0.3 到 0.5 之间)
D.0.75% (以上所有四个数字的平均值)
问题9
您同意以下哪项陈述?
A.学习算法的性能可以优于人类表现,但它永远不会优于贝叶斯错误的基准线。
B.学习算法的性能不可能优于人类表现,但它可以优于贝叶斯错误的基准线。
C.学习算法的性能不可能优于人类表现,也不可能优于贝叶斯错误的基准线。
D.学习算法的性能可以优于人类表现,也可以优于贝叶斯错误的基准线。
问题10
你发现一组鸟类学家辩论和讨论图像得到一个更好的0.1%的性能,所以你将其定义为“人类表现”。在对算法进行深入研究之后,最终得出以下结论:

根据你的资料,以下四个选项中哪两个尝试起来是最有希望的?(两个选项。)
A.尝试增加正则化。
B.获得更大的训练集以减少差异。
C.尝试减少正则化。
D.训练一个更大的模型,试图在训练集上做得更好。
问题11
你在测试集上评估你的模型,并找到以下内容:
这意味着什么?(两个最佳选项。)
A.你的开发集欠拟合了。
B.你应该尝试获得更大的开发集。
C.你应该得到一个更大的测试集。
D.你的开发集过拟合了。
问题12
在一年后,你完成了这个项目,你终于实现了:

你能得出什么结论? (多选)
A.现在很难衡量可避免偏差,因此今后的进展将会放缓。
B.统计异常(统计噪声的结果),因为它不可能超过人类表现。
C.只有0.09%的进步空间,你应该很快就能够将剩余的差距缩小到0%
D.如果测试集足够大,使得这0.05%的误差估计是准确的,这意味着贝叶斯误差是小于等于0.05的。
问题13
事实证明,和平之城也雇佣了你的竞争对手来设计一个系统。您的系统和竞争对手都被提供了相同的运行时间和内存大小的系统,您的系统有更高的准确性。然而,当你和你的竞争对手的系统进行测试时,和平之城实际上更喜欢竞争对手的系统,因为即使你的整体准确率更高,你也会有更多的假阴性结果(当鸟在空中时没有发出警报)。你该怎么办?
A.查看开发过程中开发的所有模型,找出错误率最低的模型。
B.要求你的团队在开发过程中同时考虑准确性和假阴性率。
C.重新思考此任务的指标,并要求您的团队调整到新指标。
D.选择假阴性率作为新指标,并使用这个新指标来进一步发展。
问题14
你轻易击败了你的竞争对手,你的系统现在被部署在和平之城中,并且保护公民免受鸟类攻击! 但在过去几个月中,一种新的鸟类已经慢慢迁移到该地区,因此你的系统的性能会逐渐下降,因为您的系统正在测试一种新类型的数据。(博主注:以系统未训练过的鸟类图片来测试系统的性能)
你只有1000张新鸟类的图像,在未来的3个月里,城市希望你能更新为更好的系统。你应该先做哪一个?
A.使用所拥有的数据来定义新的评估指标(使用新的开发/测试集),同时考虑到新物种,并以此来推动团队的进一步发展。
B.把1000张图片放进训练集,以便让系统更好地对这些鸟类进行训练。
C.尝试数据增强/数据合成,以获得更多的新鸟的图像。
D.将1,000幅图像添加到您的数据集中,并重新组合成一个新的训练/开发/测试集
问题15
市议会认为在城市里养更多的猫会有助于吓跑鸟类,他们对你在鸟类探测器上的工作感到非常满意,他们也雇佣你来设计一个猫探测器。(哇~猫探测器是非常有用的,不是吗?)由于有多年的猫探测器的工作经验,你有一个巨大的数据集,你有100,000,000猫的图像,训练这个数据需要大约两个星期。你同意哪些说法?(多选)
A.需要两周的时间来训练将会限制你迭代的速度。
B.购买速度更快的计算机可以加速团队的迭代速度,从而提高团队的生产力。
C.如果100,000,000个样本就足以建立一个足够好的猫探测器,你最好用100,000,00个样本训练,从而使您可以快速运行实验的速度提高约10倍,即使每个模型表现差一点因为它的训练数据较少。
D.建立了一个效果比较好的鸟类检测器后,您应该能够采用相同的模型和超参数,并将其应用于猫数据集,因此无需迭代。
参考答案
- A。这道题我的理解是,应该是问题应当存在一个可优化指标,一个满足指标吧。但是当同时出现三个要求就很难进行选择了。
- D。很简单,对于分类不超过十秒、适应10MB的内存的设备属于满足指标。在这一项上,显然B就不满足了,因为运行时间花费了13sec。在A、C、D中选择,肯定让可优化指标(测试精准度)尽可能高,则选择D。
- A。像第二题所说的。
- C。有百万条数据,那么在选择上我们尽量将大部分数据分配给训练集进行训练,开发集合测试集的数据可以不需要那么多。百万条数据时,给训练集分配的数据可以达到95%。如题。
- B。其实这题我一下子没理解。。引用一位网友的解释就很清晰了:可以把新数据添加进训练集中,添加到训练集只会有好处没会有坏的影响,但是不能添加到开发集和测试集,不然会影响实际部署效果。
- AD。不能使得训练集与开发/测试集不处于同一分布,这样子会产生一定的影响。
- D。想一下贝叶斯最优误差,我们至少还要一个人们对图片的识别误差值。
- B。选人类错误率最低的作为贝叶斯最优错误率
- A。课上说过的,不用解释了,目前也有很多ML在一些领域方面的能力超过了人类。我们平时说的人类错误率作为贝叶斯最优错误率只是一个大概。
- CD。由题意,这是存在可避免偏差(2.0-1.0>2.1.2.0)。之所以产生这样的原因是因为没有很好的拟合数据。正则化是用于避免过拟合的,所以减少正则化的选项可以选择。(后边半句不知道对不对)有时候过多的数据也不一定会产生正向作用,采用新的模型效果可能会更好。
- BD。开发集误差低,训练集误差高就意味着过拟合。
- AD。B选项不可能超过人的表现错误。C选项,0.09#的进步空间都不知道是从哪来的?A选项是正确的,因为已经很难衡量可避免误差了,对于D选项,如果测试集也能达到非常准确的效果,说明贝叶斯误差更低。
- C。A选项,错误率最低的时候精确度不一定高。
- A。若你把数据放进数据集之后,训练的话就会造成对原有的图像进行再训练,这将会导致过拟合、新样本相对于总样本比例非常低、系统性能下降、时间过长等问题,所以把这1000张数据放进原有的数据集里面是不合理的。仅仅是改变dev/test的话,需要使用所拥有的数据来定义新的评估指标。(回答来自参考链接1的评论区)
- ABC。用100,000,00个样本训练的意思是说,将这100,000,00个样本作为训练、开发、测试集的总数。从而提高训练速度。D选项,超参数并不是通用的。

















 313
313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









