







Embedding 的训练可以分为两种方法:端到端(End-to-End)和非端到端的训练。
类别特征的稀疏表示存在构造的ont-hot vector太大以及vector之间距离刻画问题,这些问题可能使模型难以有效学习,因此类别特征的embeding应运而生。
端到端(嵌入层)
端到端的方法是将 Embedding 层作为神经网络的一部分,在进行 BP 更新每一层参数的时候同时更新 Embedding,这种方法的好处是让 Embedding 的训练成为一个有监督的方式,可以很好的与最终的目标产生联系,使得 Embedding 与最终目标处于同一意义空间。(端到端的方法可参考 TensorFlow 中的 tf.nn.embedding_lookup 方法。)
将 Embedding 层与整个深度学习网络整合后一同进行训练是理论上最优的选择,因为上层梯度可以直接反向传播到输入层,模型整体是自洽和统一的。但这样做的缺点同样显而易见的,由于 Embedding 层输入向量的维度甚大,Embedding 层的加入会拖慢整个神经网络的收敛速度。
这里可以做一个简单的计算。假设输入层维度是 100,000,Embedding 输出维度是 32,上层再加 5 层 32 维的全连接层,最后输出层维度是 10,那么输入层到 Embedding 层的参数数量是 100,000×32=3,200,000,其余所有层的参数总数是 (32×32)×4+32×10=4416。那么 Embedding 层的权重总数占比是 3,200,000/(3,200,000+4416)=99.86%。
也就是说 Embedding 层的权重占据了整个网络权重的绝大部分。那么训练过程可想而知,大部分的训练时间和计算开销都被 Embedding 层所占据。正因为这个原因,对于那些时间要求较为苛刻的场景,Embedding 最好采用非端到端,也就是预训练的方式完成。
当然,端到端的 Embedding 层在深度模型中还是非常常见的,由于高维稀疏特征向量天然不适合多层复杂神经网络的训练,因此如果使用深度学习模型处理高维稀疏特征向量(增加节点数量,增加训练参数,指数级别的增加,使得训练速度变慢,且不容易收敛),几乎都会在输入层到全连接层之间加入 Embedding 层完成高维稀疏特征向量到低维稠密特征向量的转换。
广义来说,Embedding 层的结构可以比较复杂,只要达到高维向量的降维目的就可以了,但一般为了节省训练时间,深度神经网络中的 Embedding 层往往是一个简单的高维向量向低维向量的直接映射,如下图:
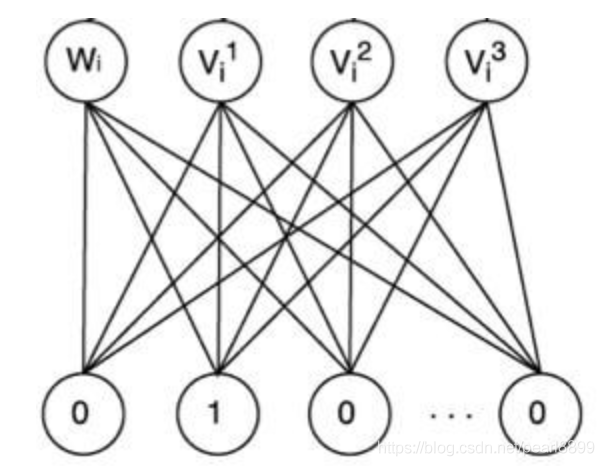
用矩阵的形式表达 Embedding 层,本质上是求解一个 m(输入高维稀疏向量的维度)乘以 n(输出稠密向量的维度)维的权重矩阵的过程。如果输入向量是 One-Hot 特征向量的话,权重矩阵中的列向量即为相应维度 One-Hot 特征的 Embedding 向量。
推荐系统应用实践中,使用端到端训练 Embedding 典型的例子,一个是微软的 Deep Crossing 模型,另外一个就是谷歌提出的著名的 Wide&Deep 模型(深度部分).
非端到端(预训练)
也就是通过预训练获得 Embedding,上一小节讲到的 Word2Vec 方法,通过语料库切分后的一堆词构建样本进行训练,其目的很纯粹,就是为了得到词向量。在真正的任务中,训练词向量并不是最终目的,而是一个预处理过程,只是为了提高最终任务模型的性能且缩短训练时间。在做其他任务时,将训练集中的词替换成事先训练好的向量表示放到网络中,就是一个非端到端的过程。在推荐场景也是一样,由于 Embedding 层的训练开销巨大,因此在一些时间要求比较高的场景下,Embedding 的训练往往独立于深度学习网络进行,在得到稀疏特征的稠密表达之后,再与其他特征一起输入神经网络进行训练。
在自然语言中,非端到端很常见,因为学到一个好的的词向量表示,就能很好地挖掘出词之间的潜在关系,那么在其他语料训练集和自然语言任务中,也能很好地表征这些词的内在联系,预训练的方式得到的 Embedding 并不会对最终的任务和模型造成太大影响,但却能够提高效率节省时间,这也是预训练的一大好处。
但是在推荐场景下,根据不同目标构造出的序列不同,那么训练得到的 Embedding 挖掘出的关联信息也不同。所以,在推荐中要想用预训练的方式,必须保证 Embedding 的预训练和最终任务目标处于同一意义空间,否则就会造成预训练得到 Embedding 的意义和最终目标完全不一致。比如做召回阶段的深度模型的目标是衡量两个商品之间的相似性,但是 CTR 做的是预测用户点击商品的概率,初始化一个不相关的 Embedding 会给模型带来更大的负担,更慢地收敛。
因此在推荐场景下,如果对于训练时间要求并不高的场景下,用端到端的训练方式可以得到更理想的效果。
Word2Vec,Doc2Vec,Item2Vec 都是典型的非端到端的方法,另外需要注意一点,Embedding 的本质是建立高维向量到低维向量的映射,而 “映射” 的方法并不局限于神经网络,实质上可以是任何异构模型,这也是 Embedding 预训练的另一大优势,就是可以采用任何传统降维方法,机器学习模型,深度学习网络完成 Embedding 的生成。
比如主题模型 LDA 可以给出每一篇文章下主题的分布向量,也可以看作是学习出了文章的 Embedding。,在推荐系统应用实践中,FNN 也可以看做是一种采用 Embedding 预训练方法的模型,
FNN 利用了 FM 训练得到的物品向量,作为 Embedding 层的初始化权重,从而加快了整个网络的收敛速度。在实际工程中,直接采用 FM 的物品向量作为 Embedding 特征向量输入到后续深度学习网络也是可行的办法。
另外一种更加特别的例子,就是是 2013 年 Facebook 提出的著名的 GBDT+LR 的模型,其中 GBDT 的部分本质上也是完成了一次特征转换,可以看作是利用 GBDT 模型完成 Embedding 预训练之后,将 Embedding 输入单层神经网络进行 CTR 预估的过程。
Embedding质量的评估
【工作中也使用embeding,但是使用的很粗糙,能训练得到embeding向量,写一个脚本,计算一些向量的相似度,然后再去数据库中,查询对应的商量是否相似,相似的标准是同品类,查询几条后,确实相似度较高的商品,品类相似可互相替代。如此验证后,便上线了。看到这篇博客,眼前一亮,收集一下,以后再用embeding的时候,有点依据,用的硬气点。】
虽然目前 Embedding 的应用已经十分火热,但对其评价问题,即衡量该 Embedding 训练得是好是坏,并没有非常完美的方案。实际上,评价其质量最好的方式就是以 Embedding 对于具体任务的实际收益(上线效果)为评价标准。但是若能找到一个合适的方案,可以在上线前对得到的 Embedding 进行评估,那将具有很大的意义。
Word Embedding 有较多的比较成熟的度量方案,常用的有以下几种7:
-
Relatedness
Relatedness:task(相似度评价指标,看看空间距离近的词,跟人的直觉是否一致) 目前大部分工作都是依赖 wordsim353 等词汇相似性数据集进行相关性度量,并以之作为评价 Word Embedding 质量的标准。这种评价方式对数据集的大小、领域等属性很敏感。Google 在 Word2Vec 中给出的评估方案就是这个。
-
Analogy
Analogy:task 也就是著名 A - B = C - D 词汇类比任务(所谓的 analogy task,就是 Embedding 线性规则的体现,如 king – queen = man – woman)
-
Categorization Categorization 分类,看词在每个分类中的概率。
-
聚类算法 例如 kmeans 聚类,查看聚类分布效果 。若向量维度偏高,则对向量进行降维,并可视化。如使用 pca,t-sne 等降维可视化方法,包括 google 的 tensorboard 以及 Embedding Projector,python 的 matplotlib 等工具,从而得到词向量分布。
Item Embedding 则基本上没有统一认可的方案,下面提供一些方案提供参考:
- 一个常用的评估的办法就是采样看 Top N 的相似度,看是不是确实学习到了有意义的信息,下一节提到的阿里 EGES 论文中,用的就是这样的方法。
- 从 item2vec 得到的词向量中随机抽出一部分进行人工判别可靠性。即人工判断各维度 item 与标签 item 的相关程度,判断是否合理,序列是否相关。
- 也可以借鉴 Word Embedding 中聚类可视化的方法,抽样进行对比,查看效果如何。
- 还有一种方案,就是用大量数据训练出一个相对新的类似于 wordsim353 标准的 item 类型的标准,之后进行相似度度量。但是实现难度主要在训练数据的质量和时效性方面,对于商品类还好,但对于新闻类这种更新率极快的 item 类型,时效性是很大问题。
- 当然,也可通过观察实际效果来定,也可采用替换 Embedding 对应值为初始值来看预测效果是否有显著下降。
参考:
1.https://lumingdong.cn/application-practice-of-embedding-in-recommendation-system.html















 2016
2016











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









