







前奏:
【NLG】(二)文本生成评价指标—— METEOR原理及代码示例
1.ENTROPY原理
信息熵可以表达数据的信息量大小,是信息处理一个非常重要的概念。
对于离散型随机变量,信息熵公式如下:
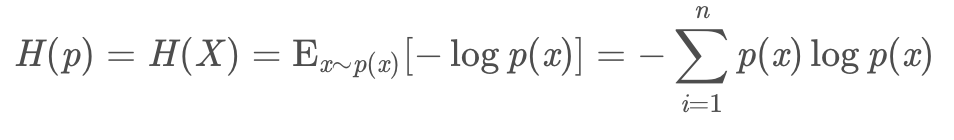
对于连续型随机变量,信息熵公式如下:

对于生成的文本而言,希望其“言之有物”,“灼灼其华”,那可以衡量的一个指标是熵,即:系统整体所包含的的信息量。
2.优缺点
这个没有明确的优缺点,该指标在陈述一个事实。
3.如何算ENTROPY
一个首要问题:p(x)怎么计算?对于离散型随机变量而言,其出现的概率= 出现次数/整体的词。
输入是生成的文本,多个文本,字与字之间用空格分离,可以组成list,作为输入。
输出是生成的文本的熵。
def entropy(predicts):
etp_score = [0.0, 0.0, 0.0, 0.0]
div_score = [0.0, 0.0, 0.0, 0.0]
counter = [defaultdict(int), defaultdict(int),
defaultdict(int), defaultdict(int)]
for gg in predicts:
g = gg.rstrip().split()
for n in range(4):
# print('---n: ', n)
for idx in range(len(g)-n):
ngram = ' '.join(g[idx:idx+n+1])
# print('----ngram: ', ngram)
counter[n][ngram] += 1
# print('---counter: ', counter)
for n in range(4):
# print('---scores n: ', n)
total = sum(counter[n].values()) + 1e-10
for v in counter[n].values():
etp_score[n] += - (v+0.0) / total * (np.log(v+0.0) - np.log(total))
div_score[n] = (len(counter[n].values())+0.0) / total
return etp_score, div_score
if __name__ == '__main__':
predicts = ['你 说 什 么 ?', '你 说 的 是 啥 ?']
etp_score, div_score = entropy(predicts)















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









