







tf.data.Dataset是一种针对大规模数据设计的迭代器。tf.data中有许多数据集预处理函数,并且可以和keras框架的compile、fit、evaluate训练方式和tf.GradientTape无缝衔接,使训练网络和数据预处理变得简单
tf.data数据集的构建与预处理
数据集构建
代码示例
import tensorflow as tf
x = tf.constant([1,2,3,4,5])
y = tf.constant([6,7,8,9,10])
dataset = tf.data.Dataset.from_tensor_slices((x,y))
for x,y in dataset:
print(x.numpy(),y.numpy())
数据集预处理函数
训练过程中为了得到最优的结果,我们常常用分批,多次迭代的方法训练网络。先建立一个缓冲区,将训练集打乱放入,再将训练集分批,反复迭代,进行多个epoch,多次更新权重。tf.data中提供数据集预处理的函数,让训练简单。下面给出几个常用的预处理函数。
Dataset.map(f)
对数据集中的每个元素应用函数f,得到一个新数据集
Dataset.shuffle(buffer_size)
设定一个固定大小(buffer_size)的缓冲区,取出原数据集前buffer_size个元素放入,将数据集打乱,得到一个新的数据集
Dataset.batch(batch_size)
将数据集分成批,批大小为batch_size
dataset = dataset.shuffle(buffer_size=28800).batch(720)
Dataset.prefetch()
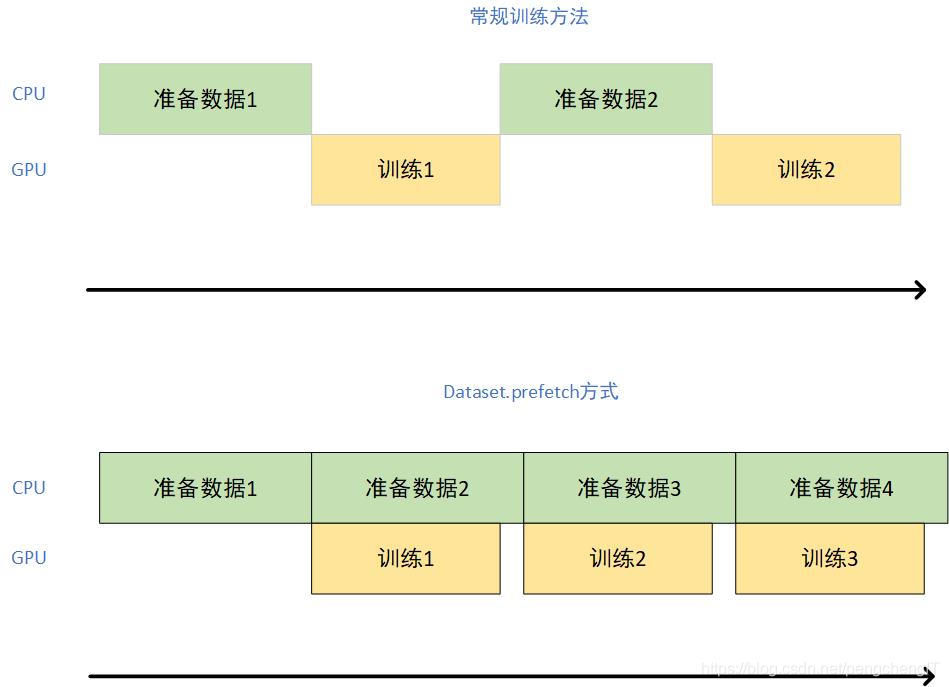
这是一种并行化策略,充分利用多核CPU与GPU的计算资源,减少CPU/GPU的空载时间,加入下面一行代码,让TensorFlow自动根据CPU情况处理,使用后会大大减少训练时间
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)














 2773
2773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









