






假定我们有一组object n个O1,O2,...On,每个Object有m个特征,f1,f2,...fm 。我们已知的数据如下
1)我们知道每个object的特征取值
例如 f1(Obj1) = 0.5 f2(Obj1) = 0.2 ... fm(Obj1) = 0.1
2)我们知道每个Object的两两比较结果,Pij表示objecti > objectj 或者说前者好于后者
例如object 1 大于 object2 的概率 P12
这类监督学习,相当于绕了个弯子,并不是直接知道 F: Rm -> R ,而是只知道两两比较的结果
如果直接知道每个Object的优秀值,那么就是可以直接回归学习出函数F: Rm -> R
通常这种情况,采用交叉熵代价函数
也就是 令 oij = F(Obj1) - F(Obj2) 可以理解成logistic regression 的两组输出结果的差值
Cij = C(oij) = -Pij*log(Pij) - (1-Pij)*log(Pij)
其中Pij 是我们已知的标注结果,也就是监督结果,Pij 是F函数输出的差值oj,经过sigmoid函数转化后的结果 Pij= exp(oij) / 1+ exp(oij) (sigmoid函数)
简化后,得到
Cij = -Pij*oij + log(1+exp(oij))
优化的目标也就是让所有的Cij尽可能的小。也就是学习出的函数F,能够满足大部分我们已知的(2),即两两比较的结果。
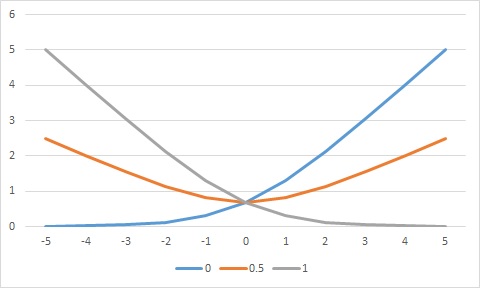
这种代价函数Cij的好处
1)在Pij = 1 ,即人工标注强烈要求i〉j的情况下, oij越大,则Cij越小,oij越小,Cij越大
2)在Pij = 0 ,即人工标注认为ii和j差不多, oij越大,则Cij越大,oij越小,Cijj越大
2)在Pij = -1 ,即人工标注认为ii<j, oij越大,则Cij越大,oij越小,Cijj越小
符合直观,如下图















 3215
3215

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









