






Decoder
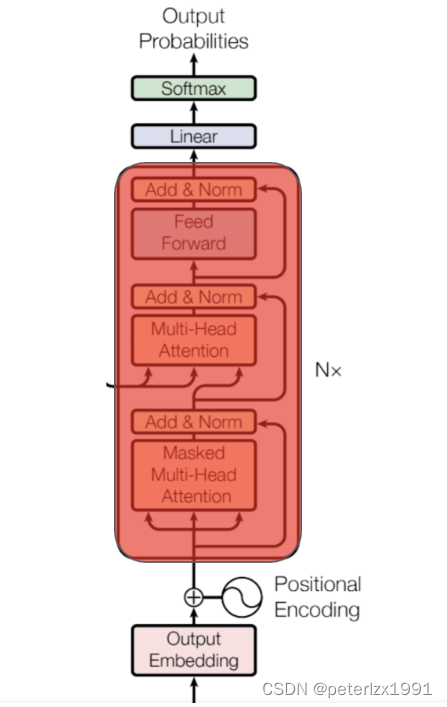
训练过程
假如encoder_input序列是'我很爱你', decoder输入是'bos I love you very much' 那么decoder输出是’I love you very much eos‘
1. 我爱你经过encoder之后得到(4, 300)
2.'bos I love you very much' 经过embeding和pe之后 -> (6, 300)
3. 2的结果(6, 300)需要做一个自注意力机制,每个词做为query对这个句子中的其他词做self-attention,除了当前词, 还要考虑其他词的信息
这里为啥需要做mask?
bos I love you very much
bos x -8 -8 -8 -8 -8
I x x -8 -8 -8 -8
love x x x -8 -8 -8
you x x x x -8 -8
very x x x x x -8
much x x x x x x
每个token在对其他token self-attenteion的时候都只能看到前面的 这里-8代表负无穷, attention经过softmax之后会是0
这里第每行的意义:
1. decoder_input是bos的时候 target是I
2. decoder_input是bos, I的时候 target是love
3. decoder_input是bos, I, love的时候 tartget是you
4. decoder_input是bos, I, love, you的时候, target的是very
5. decoder_input是bos, I, love, you, very的时候, target是much
6. decoder_input是bos, I, love, you, very, much的时候 target是eos
4. 这里经过mask-multi-head-attention之后,decoder-input每行只看到之前的信息(6, 300)
5. 这里4的信息(6, 300)做为query, 1(4, 300)的信息做为k和v
(6, 300) * (300, 4) -> (6, 4)
(6, 4) * (4, 300) -> (6, 300)
这里不用mask,因为encoder的结果信息在decoder每一步都可以看到
6. 5(6, 300)结合了encoder的输出和decoder的输入信息 经过add, Norm, FNN之后依然维度不变还是(6, 300) 这个做为下一个decoder的输入 这个过程要循环6次
7. 最后一次循环之后decoder依旧输出(6, 300) 经过一次映射变化得到(6, 10000假设10000个token)
(6, 300) * linear(300, token_dim) -> (6, toekn_dim) -> softmax -> (6, 10000) 得到每行(位置)的10000个词的概率 每行选概率最大的结果得到每个位置词的编码
8. 7(6, )和deocder_target(6, )做cross_entropy_loss
输入: 实际上把encoder_input -> (我, 很, 爱, 你) decoder_input -> (bos, I, love, you, very, much)
输出: (6, )和(I, love, you, very, much eos)做cross_entropy
end
预测过程
1. 我爱你经过encoder之后得到(4, 300)
2. encoder_output(4, 300), deocder_input_1: bos(1, 300) 不用mask了这里是一步一步预测的
(1, 300) * (300, 4) -> (1, 4)
(1, 4) * (4, 300) -> (1, 300)
3. 最终得到predict_1: I
4. encoder_output(4, 300), decoder_input_2: (bos, predict_1)(2, 300) -> predict_2 (I, love)
5. encoder_output(4, 300), decoder_input_3: (bos, predict_2)(3, 300) -> predict_3(I, love, you)
6. encoder_output(4, 300), decoder_input_4: (bos, predict_3)(4, 300) -> predict_4(I, love, you, very)
7. encoder_output(4, 300), decoder_input_5: (bos, predict_4)(5, 300) -> predict_5(I, love, you, very, much)
8. encoder_output(4, 300), decoder_input_6: (bos, predict_5)(6, 300) -> predict_6(I, love, you, very, much, eos)
当然中间哪一步预测的结果都有可能不正确,并且做为输入带入下一个词的预测















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









