







 本文深入解析了掘金新版本编辑器的源码,从React版本的源码开始,探讨了Svelte框架的特性,并详细分析了编辑器的结构和关键组件,包括CodeMirror的使用。文章还介绍了编辑器的性能优化,如防抖处理,以及源码中涉及到的文档对象(Doc)的处理逻辑。最后,梳理了源码阅读的流程,赞赏了字节跳动在编辑器性能上的追求。
本文深入解析了掘金新版本编辑器的源码,从React版本的源码开始,探讨了Svelte框架的特性,并详细分析了编辑器的结构和关键组件,包括CodeMirror的使用。文章还介绍了编辑器的性能优化,如防抖处理,以及源码中涉及到的文档对象(Doc)的处理逻辑。最后,梳理了源码阅读的流程,赞赏了字节跳动在编辑器性能上的追求。
掘金(字节跳动)MD编辑器源码解析
写在开头
今天在朋友圈发现,掘金运营发布了新的掘金编辑器,作为一位曾经的富文本编辑器开发者,我当然充满了好奇,于是就有了这篇文章
首先找到
github源码,https://github.com/bytedance/bytemd,然后克隆下来,就开始了
最近我写了一个前端学架构100集,会慢慢更新,请大家别着急,目前在反复修改推敲内容
正式开始
我本人电脑环境
Arm架构Mac,M1芯片那款环境,
nvm控制多个node.js版本,电脑需要全局安装pnpm,用于依赖管理(这里字节跳动是使用的pnpm管理依赖)
如果你比较菜,不懂
pnpm,没事,我有文章:https://juejin.cn/post/6932046455733485575
安装项目依赖(这个项目是用的
lerna管理依赖):
nvm install 12.17
npm i pnpm -g
pnpm i
在项目本地调试编辑器源码:
npm link或者yalc
如果你比较菜,不会这两种方式,没事,我也有文章:
https://mp.weixin.qq.com/s/t6u6snq_S3R0X7b1MbvDVA,总之不会的来公众号翻翻,都有。我的前端学架构100集里面也会都有
React版本的源码解析
先看看在React里面怎么使用的
先引入样式:
import 'bytemd/dist/index.min.css';
再引入组件:
import { Editor, Viewer } from '@bytemd/react';
import gfm from '@bytemd/plugin-gfm';
const plugins = [
gfm(),
// Add more plugins here
];
const App = () => {
const [value, setValue] = useState('');
return (
<Editor
value={value}
plugins={plugins}
onChange={(v) => {
setValue(v);
}}
/>
);
};
从
Editor组件入手
import React, { useEffect, useRef } from 'react';
import * as bytemd from 'bytemd';
export interface EditorProps extends bytemd.EditorProps {
onChange?(value: string): void;
}
export const Editor: React.FC<EditorProps> = ({
children,
onChange,
...props
}) => {
const ed = useRef<bytemd.Editor>();
const el = useRef<HTMLDivElement>(null);
useEffect(() => {
if (!el.current) return;
const editor = new bytemd.Editor({
target: el.current,
props,
});
editor.$on('change', (e: CustomEvent<{ value: string }>) => {
onChange?.(e.detail.value);
});
ed.current = editor;
return () => {
editor.$destroy();
};
}, []);
useEffect(() => {
// TODO: performance
ed.current?.$set(props);
}, [props]);
return <div ref={el}></div>;
};
发现一切都是来源于:
bytemd这个库,于是我们去找到它的源码~
bytemd的源码入口文件
/// <reference types="svelte" />
import Editor from './editor.svelte';
import Viewer from './viewer.svelte';
export { Editor, Viewer };
export * from './utils';
export * from './types';
好家伙,这个
Editor是用sveltejs写的,地址是:https://www.sveltejs.cn/
React和Vue都是基于runtime的框架。所谓基于runtime的框架就是框架本身的代码也会被打包到最终的bundle.js并被发送到用户浏览器。
当用户在你的页面进行各种操作改变组件的状态时,框架的runtime会根据新的组件状态(state)计算(diff)出哪些DOM节点需要被更新,从而更新视图
最小的Vue都有58k,React更有97.5k。换句话说如果你使用了React作为开发的框架,即使你的业务代码很简单,你的首屏bundle size都要100k起步。当然100k不算很大,可是事物都是相对的,相对于大型的管理系统来说100k肯定不算什么,可是对于那些首屏加载时间敏感的应用(例如淘宝,京东主页),100k的bundle size在一些网络环境不好的情况或者手机端真的会影响用户体验。那么如何减少框架的runtime代码大小呢?要想减少runtime代码的最有效的方法就是压根不用runtime
所以这里可以看出来,掘金(字节跳动)非常看重性能
什么是Svelte?
Svelte是由RollupJs的作者Rich Harris编写的编译型框架,没了解过RollupJs的同学可以去它官网了解一下,它其实是一个类似于Webpack的打包工具。Svelte这个框架具有以下特点:和React,Vue等现代Web框架的用法很相似,它可以允许开发者快速开发出具有流畅用户体验的Web应用。不使用Virtual DOM,也不是一个runtime的库。基于Compiler as framework的理念,会在编译的时候将你的应用转换为原生的DOM操作
这篇文章写得很全面,关于
Svelte,https://zhuanlan.zhihu.com/p/97825481,由于本文重点是源码,不是环境,不是框架底层介绍,点到为止,有兴趣的去看文章~
编辑器划分为几个区域
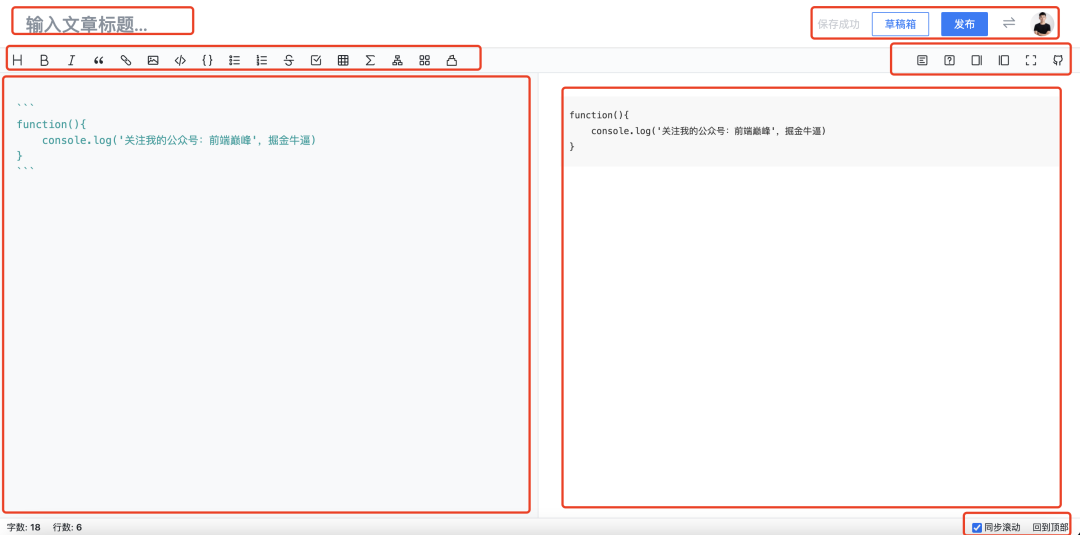
首先是标题区域,输入框,没什么好说的
接下来,应该都是向编辑器插入内容的操作(重点)
右边的改变一些样式和布局的,可以忽略不计
左侧内容区域为编辑区域(重点)
右侧为内容预览区域(重点)
先来一波性能测试
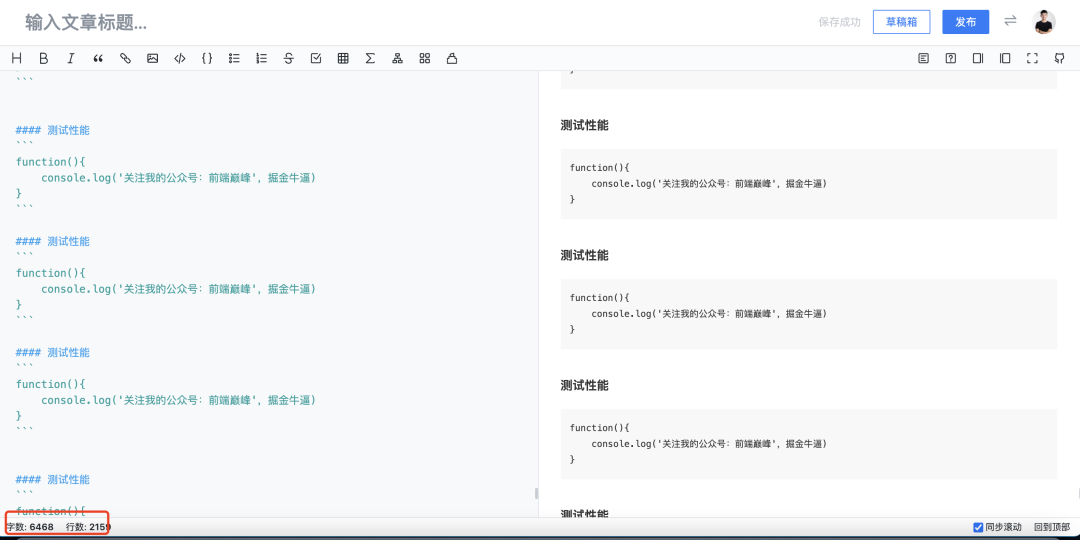
这里我疯狂复制内容,一直粘贴ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1653
1653

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









