







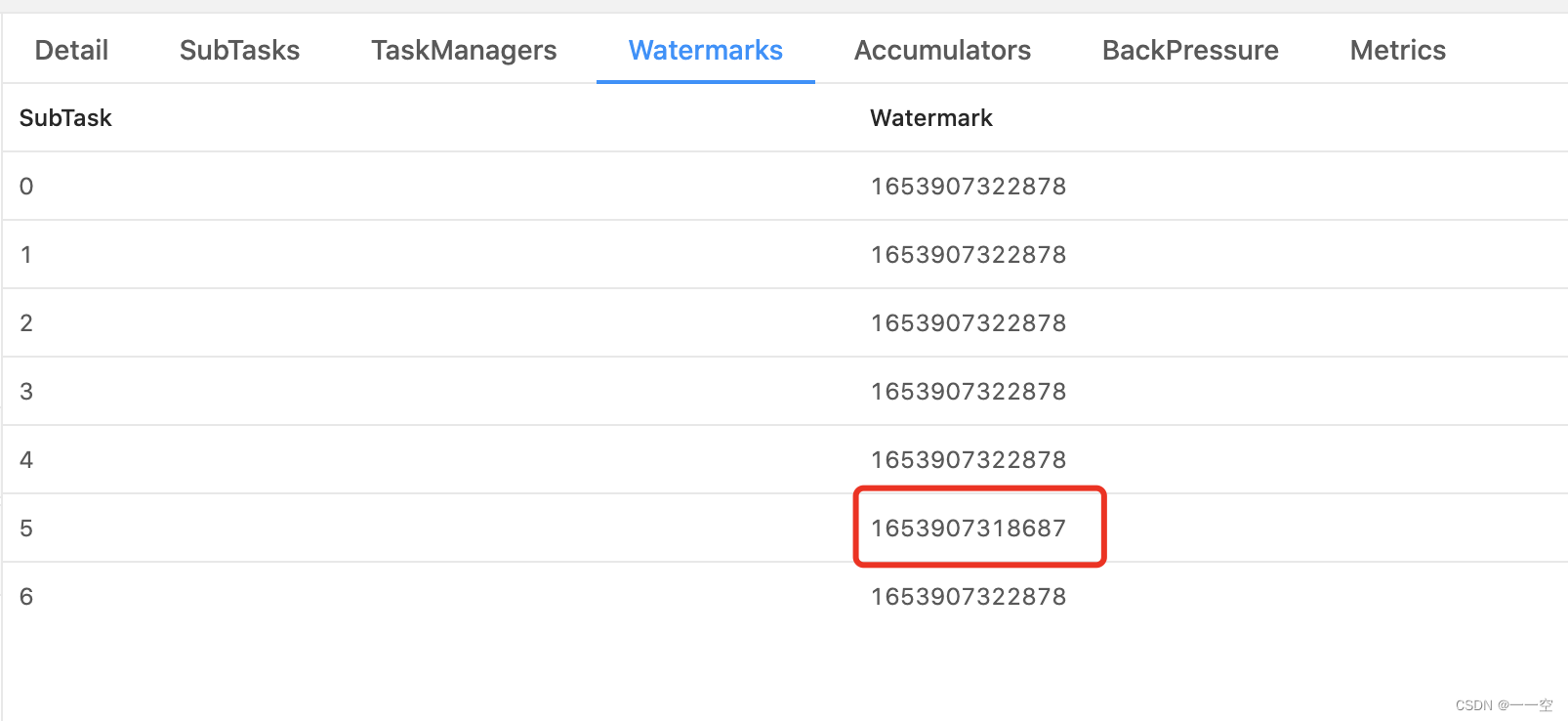
flink某一个算子,不同分区水印不一致
在研发过程红碰到一个问题,实时计算的flink某一个算子的不同分区水印不一致,很明显,由于上游在keyby处理后,导致下游不同分区数据分配不均衡,导致不同分区到达的水印不一致,这种情况下可以考虑收缩分区数量;
如下是统计PV\UV的核心计算代码;
int parallelism = 2;
int dbParallelism = 1;
int days = 7;
DataStream<PVModel> dataStream = dataStream
.keyBy(item -> item.getName())
.map(new MyRepeatMapFunction(days)).setParallelism(parallelism)
.keyBy(item -> item.getName())
.timeWindow(Time.days(days), Time.seconds(10))
.aggregate(new MyPVStatisticFunction()).setParallelism(parallelism)
.name(this.days + "Day");
dataStream.addSink(sink).setParallelism(dbParallelism).name("ToDbSink");
这里采用map的RichMapFunction对数据进行预处理,将PV的访问数据加工成PVModel模型,如下
| date | name | uv | pv |
| 2022-05-30 13:00:00 | ikong | 1 | 1 |
| 2022-05-30 14:00:00 | ikong | 0 | 1 |
| 2022-05-30 15:00:00 | ikong | 0 | 1 |
| 2022-05-30 14:00:00 | lilei | 1 | 1 |
| 2022-05-30 15:00:00 | lilei | 0 | 1 |
思路:通过state记录当天的用户是否已经存在,不存在则uv=1,否则uv=0,pv会一直为1;
MyRepeatMapFunction.java
public static class MyRepeatMapFunction extends RichMapFunction<UVModel, PVModel> {
private int days;
public MyRepeatMapFunction(int days) {
this.days = days;
}
MapState<String, Integer> uvState;
MapState<String, Integer> pvState;
@Override
public void open(Configuration parameters) throws Exception {
uvState = this.getRuntimeContext()
.getMapState(new MapStateDescriptor<>("uv-state" + days
, BasicTypeInfo.STRING_TYPE_INFO
, BasicTypeInfo.INT_TYPE_INFO)
);
pvState = this.getRuntimeContext()
.getMapState(new MapStateDescriptor<>("pv-state" + days
, BasicTypeInfo.STRING_TYPE_INFO
, BasicTypeInfo.INT_TYPE_INFO)
);
}
@Override
public PVModel map(UVModel uvm) throws Exception {
String uvKey = uvm.getName() + new DateTime(uvm.getViewTime()).toString("yyyyMMdd");
String pvKey = uvm.getName();
int uv = 0;
if (!uvState.contains(uvKey)) {
uv = 1;
uvState.put(uvKey, uv);
}
int pv = 1;
pvState.put(pvKey, pv);
PVModel vm = new PVModel();
vm.setDays(uv);
vm.setCount(pv);
vm.setName(uvm.getName());
return vm;
}
}
通过聚合函数AggregateFunction,对用户的uv、pv数据进行累加,最终得到用户最近x天的uv和pv总数
public static class MyPVStatisticFunction implements AggregateFunction<PVModel, PVModel, PVModel> {
@Override
public MyPVStatisticFunction createAccumulator() {
return new PVModel();
}
@Override
public PVModel add(PVModel uvm, PVModel acc) {
acc.setCount(acc.getCount() + 1);
acc.setName(uvm.getName());
acc.setDays(acc.getDays() + uvm.getDays());
return acc;
}
@Override
public PVModel getResult(PVModel tp) {
return tp;
}
@Override
public PVModel merge(PVModel tp1, PVModel tp2) {
PVModel uvm = new PVModel();
uvm.setCount(tp1.getCount() + tp2.getCount());
uvm.setDays(tp1.getDays() + tp2.getDays());
uvm.setName(tp1.getName());
return uvm;
}
}
对PVModel进行累加后的结果如下
| date | name | uv | pv |
| 2022-05-30 | ikong | 1 | 3 |
| 2022-05-30 14:00:00 | lilei | 1 | 2 |
其他辅助代码
UVModel.java
public class UVModel {
private String name = "";
private String url = "";
private Long viewTime = 0L;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public String getUrl() {
return url;
}
public void setUrl(String url) {
this.url = url;
}
public Long getViewTime() {
return viewTime;
}
public void setViewTime(Long viewTime) {
this.viewTime = viewTime;
}
@Override
public String toString() {
return "UVModel{" +
"name='" + name + '\'' +
", url='" + url + '\'' +
", viewTime=" + viewTime +
'}';
}
}
PVModel.java
public class PVModel implements Serializable {
private String name = "";
private int days = 0;
private int count = 0;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getDays() {
return days;
}
public void setDays(int days) {
this.days = days;
}
public int getCount() {
return count;
}
public void setCount(int count) {
this.count = count;
}
@Override
public String toString() {
return "UserViewStatisticModel{" +
"name='" + name + '\'' +
", days=" + days +
", count=" + count +
'}';
}
}


















 6473
6473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











