







安装JAVA
tar -xvf /opt/java/jdk-8u71-linux-x64.tar.gz
/opt/java/jdk1.8.0_71
增加环境变量
vim /etc/profile
修改profile 最后面加入
export JAVA_HOME=/opt/java/jdk1.8.0_71
export CLASSPATH=.:$JAVA_HOME/jre/lib/rt.jar:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
运行
source /etc/profile
切换版本
update-alternatives --install /usr/bin/java java /opt/java/jdk1.8.0_71/bin/java 60
update-alternatives --config java 测试java安装
java -version
java version “1.8.0_71”
Java(TM) SE Runtime Environment (build 1.8.0_71-b15)
Java HotSpot(TM) 64-Bit Server VM (build 25.71-b15, mixed mode)
表示安装完成
centos7 伪分布 安装 cdh5.5.1
下载CDH文件
创建目录,并切换到此目录
mkdir /opt/cdh
cd /opt/cdh
sudo wget http://archive.cloudera.com/cdh5/one-click-install/redhat/7/x86_64/cloudera-cdh-5-0.x86_64.rpm
然后使用yum命令在本地安装
sudo yum --nogpgcheck localinstall cloudera-cdh-5-0.x86_64.rpm
开始安装
(Optionally) add a repository key:
sudo rpm --import http://archive.cloudera.com/cdh5/redhat/5/x86_64/cdh/RPM-GPG-KEY-cloudera 2.安装Hadoop伪节点模式
sudo yum install hadoop-conf-pseudo
启动Hadoop并验证环境
至此,Hadoop的伪节点安装已经完毕,下面我们就开始做一些配置,并启动Hadoop
1. 格式化NameNode
sudo -u hdfs hdfs namenode -format
2.启动HDFS
for x in `cd /etc/init.d ; ls hadoop-hdfs-*` ; do sudo service $x start ; done 此处这样写主要是hadoop 相关的命令在 /etc/init.d/ 里面
为了验证是否启动成功,可以在浏览器里输入地址:http://localhost:50070 (localhost也可更改为ip地址)进行查看
创建/tmp,Staging 以及Log的目录
sudo -u hdfs hadoop fs -mkdir -p /tmp/hadoop-yarn/staging/history/done_intermediate
sudo -u hdfs hadoop fs -chown -R mapred:mapred /tmp/hadoop-yarn/staging
sudo -u hdfs hadoop fs -chmod -R 1777 /tmp
sudo -u hdfs hadoop fs -mkdir -p /var/log/hadoop-yarn
sudo -u hdfs hadoop fs -chown yarn:mapred /var/log/hadoop-yarn
运行下面的指令,来查看文件是否建立:
sudo -u hdfs hadoop fs -ls -R /
启动YARN(YARN是MapReduce的升级版)
sudo service hadoop-yarn-resourcemanager start
sudo service hadoop-yarn-nodemanager start
sudo service hadoop-mapreduce-historyserver start
创建用户目录,为每个MapReduce 用户创建home目录, <user> 替换为你的用户
注意如果你想使用其他用户名比如myuser,那么你需要额外进行如下的操作
useradd myuser -- 创建用户
vim /etc/sudoers -- 修改myuser用户的权限
source /etc/sudoers -- 保存修改内容后,重启
su myuser -- 切换用户接下来执行下面的操作(若是不想添加下面的<user>用root替换;否则就用新建的用户替换)
sudo -u hdfs hadoop fs -mkdir -p /user/<user>
sudo -u hdfs hadoop fs -chown <user> /user/<user>测试HDFS
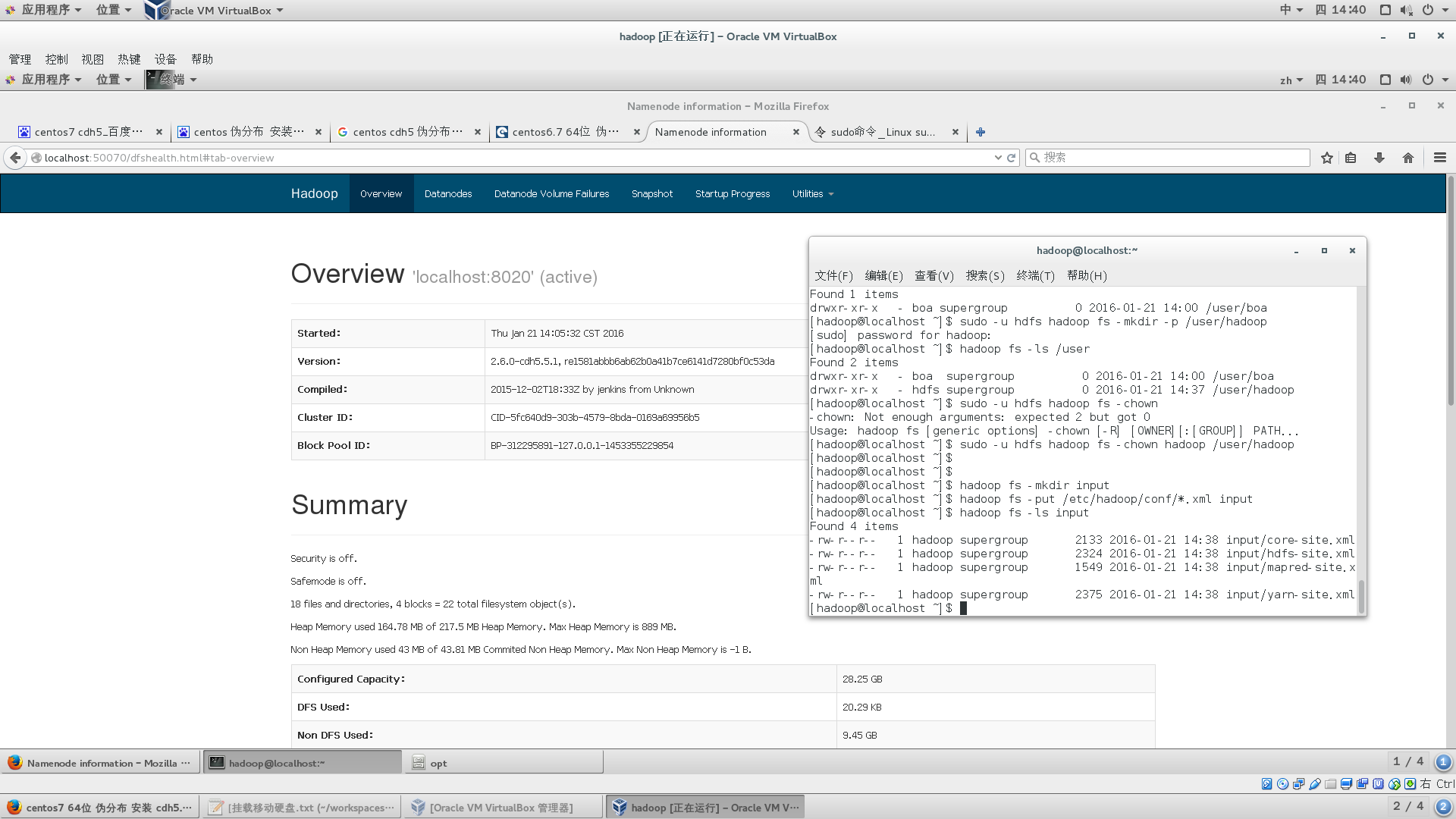
hadoop fs -mkdir input
hadoop fs -put /etc/hadoop/conf/*.xml input
hadoop fs -ls input
若是输出如下内容 表示成功了
测试代码:
源代码:
package boa.hadoop;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
*
* @author zhangdapeng
*2016年1月20日
*
*/
public class Temperature {
static class TempMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
@Override
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
System.out.print("Before Mapper: " + key + ", " + value);
String line = value.toString();
String year = line.substring(0, 4);
int temperature = Integer.parseInt(line.substring(8));
context.write(new Text(year), new IntWritable(temperature));
System.out.println("---->After Mapper:" + new Text(year) + ", " + new IntWritable(temperature));
}
}
static class TempReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
@Override
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int maxValue = Integer.MIN_VALUE;
StringBuffer sb = new StringBuffer();
// 取values的最大值
for (IntWritable value : values) {
maxValue = Math.max(maxValue, value.get());
sb.append(value).append(", ");
}
System.out.print("Before Reduce: " + key + ", " + sb.toString());
context.write(key, new IntWritable(maxValue));
System.out.println("---->After Reduce: " + key + ", " + maxValue);
}
}
public static void main(String[] args) throws Exception {
// 输入路径
// String in = "hdfs://localhost:8020/user/hadoop/input/";
String in = "/home/hadoop/workspace/hadoop/input.txt";
// 输出路径,必须是不存在的,空文件加也不行。
// String out = "hdfs://localhost:8020/user/hadoop/output";
String out = "/home/hadoop/workspace/output/";
Configuration hadoopConfig = new Configuration();
// hadoopConfig.set("fs.hdfs.impl", org.apache.hadoop.hdfs.DistributedFileSystem.class.getName());
// hadoopConfig.set("fs.file.impl", org.apache.hadoop.fs.LocalFileSystem.class.getName());
Job job = Job.getInstance(hadoopConfig);
// 如果需要打成jar运行,需要下面这句
// job.setJarByClass(Temperature.class);
// job执行作业时输入和输出文件的路径
FileInputFormat.addInputPath(job, new Path(in));
FileOutputFormat.setOutputPath(job, new Path(out));
// 指定自定义的Mapper和Reducer作为两个阶段的任务处理类
job.setMapperClass(TempMapper.class);
job.setReducerClass(TempReducer.class);
// 设置最后输出结果的Key和Value的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 执行job,直到完成
job.waitForCompletion(true);
System.out.println("Finished!");
}
}maven配置:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>boa</groupId>
<artifactId>hadoop</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>hadoop</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<archive>
<manifest>
<!--这里要替换成jar包main方法所在类 -->
<mainClass>boa.hadoop.Temperature</mainClass>
</manifest>
<manifestEntries>
<Class-Path>.</Class-Path>
</manifestEntries>
</archive>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id> <!-- this is used for inheritance merges -->
<phase>package</phase> <!-- 指定在打包节点执行jar包合并操作 -->
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
输入数据:
2014010114
2014010216
2014010317
2014010410
2014010506
2012010609
2012010732
2012010812
2012010919
2012011023
2001010116
2001010212
2001010310
2001010411
2001010529
2013010619
2013010722
2013010812
2013010929
2013011023
2008010105
2008010216
2008010337
2008010414
2008010516
2007010619
2007010712
2007010812
2007010999
2007011023
2010010114
2010010216
2010010317
2010010410
2010010506
2015010649
2015010722
2015010812
2015010999
2015011023结果:
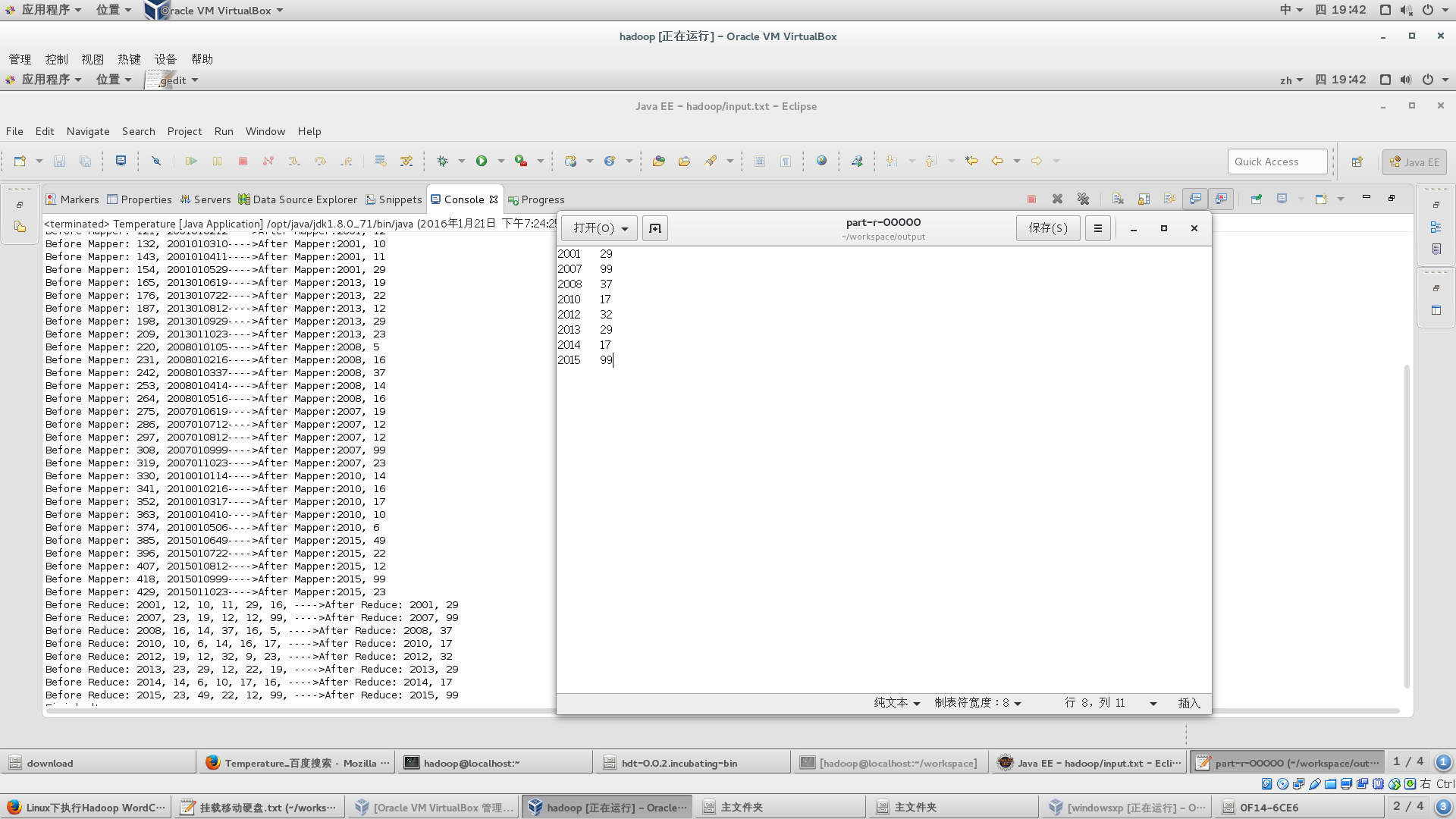
参考:
http://jingyan.baidu.com/article/5bbb5a1b10b57913eaa17976.html
http://dalan-123.iteye.com/blog/2255628















 4486
4486

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









