







Hive的存储是建立在Hadoop文件系统之上的。Hive本身没有专门的数据存储格式,也不能为数据建立索引,用户可以自由地组织Hive中的表,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符就可以解析数据了。
Hive中主要包含四类数据模型:表(Table)、外部表(External Table)、分区(Partition)和桶(Bucket)。
Hive中每个分区都对应数据库中相应分区列的一个索引,但是分区的组织方式和传统关系型数据库不同。在Hive中,表中的一个分区对应表下的一个目录,所有分区的数据都存储在对应的目录中。htable表中包含year、month和day三个分区,分别对应三个目录:对于year=2012,month=01,day=01的HDFS子目录为:/warehouse/htable/year=2012/ month=01/ day=01
;对于year=2012,month=02,day=14的HDFS子目录为:/warehouse/htable/year=2012/ month=02/ day=14;
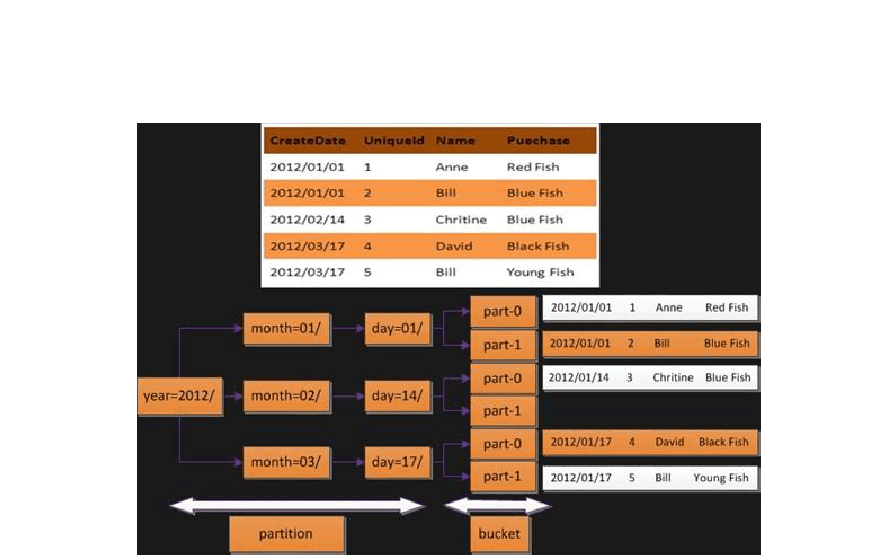
桶对指定列进行哈希计算时,根据哈希值切分数据,每个桶对应一个文件。htable表中属性列Uniqueid列分散到32个桶中,首先要对Uniqueid进行hash计算,对应哈希值为0的桶写入HDFS的目录为:/warehouse/htable/year=2012/ month=01/
day=01/part-0;对应哈希值为1的桶写入HDFS的目录为:/warehouse/htable/year=2012/ month=01/ day=01/part-1。
一、hive功能简介
功能简介
PARTITIONED BY关键字为表格分区
通过CLUSTERED BY关键字将PATITION划分成BUCKET
定义每条记录的存储格式,包括:
字段之间如何分隔;
集合字段中的元素如何分隔;
Map的key值如何分隔
指定存储格式为Hadoop的SequenceFile
(2)查看表结构
DESCRIBE tablename;
(3)修改表格
为表格添加字段
ALTER TABLE pokes ADD COLUMNS (new_col INT);
(4)删除表格
DROP TABLE tablename;
DML
(1)、导入数据
导入操作,只是将文件复制到对应的表格目录中,并不会对文档的
schema进行校验
从HDFS导入
LOAD DATA INPATH ‘data.txt’ INTO TABLE page_view PARTITION(date=’2008-06-08’,
country=’US’)
从本地导入,并覆盖原数据
LOAD DATA LOCAL INPATH ‘data.txt’ OVERWRITE INTO TABLE page_view
PARTITION(date=’2008-06-08’, country=’US’)
定义表格时如不指定Row Format和Stored As从句,
hive采用如下默认配置:
CREATE TABLE …
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ‘\001’
COLLECTION ITEMS TERMINATED BY ‘\002’
MAP KEYS TERMINATED BY ‘\003’
LINES TERMINATED BY ‘\n’
STORED AS TEXTFILE;
默认为纯文本文件TEXTFILE
如果存储的数据不是纯文本,而包含二进制的数据,可用
SequenceFile和RCFile
RCFile;基于列存储,类似于HBase,查询Table时,如果要检索的数据不是整条记录,而是具体的column,RCFile较比
SequenceFile高效一些,只需遍历指定column对应的数据文件即可
如果存储的数据不是纯文本,而包含二进制的数据,可用SequenceFile和RCFile
RCFile:基于列存储,类似于HBase,查询Table时,如果要检索的数据不是整条记录,而是具体的column,RCFile
较比SequenceFile高效一些,只需遍历指定column对应的数据文件即可使用RCFile,创建Table时使用如下语法:
CREATE TABLE …
ROW FORMAT SERDE ‘org.apache.hadoop.hive.serde2.columnar.ColumnarSerDe’
STORED AS RCFILE;
除此之外,Hive还可通过正则表达式的方式指定输入数据源的格式:
CREATE TABLE stations (usaf STRING, wban STRING, name STRING)
ROW FORMAT SERDE ‘org.apache.hadoop.hive.contrib.serde2.RegexSerDe’
WITH SERDEPROPERTIES (
“input.regex” = “(\d{6}) (\d{5}) (.{29}) .*”
);
创建数据库
Create Database
CREATE (DATABASE|SCHEMA) [IF NOT EXISTS] database_name
[COMMENT database_comment]
[LOCATION hdfs_path]
[WITH DBPROPERTIES (property_name=property_value, …)];
The uses of SCHEMA and DATABASE are interchangeable – they mean the same thing. CREATE DATABASE was added in Hive 0.6 (HIVE-675). The WITH DBPROPERTIES clause was added in Hive 0.7 (HIVE-1836).
删除数据库
Drop Database
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT|CASCADE];
The uses of SCHEMA and DATABASE are interchangeable – they mean the same thing. DROP DATABASE was added in Hive 0.6 (HIVE-675).
修改数据库
Alter Database
ALTER (DATABASE|SCHEMA) database_name SET DBPROPERTIES (property_name=property_value, …); – (Note: SCHEMA added in Hive 0.14.0)
ALTER (DATABASE|SCHEMA) database_name SET OWNER [USER|ROLE] user_or_role; – (Note: Hive 0.13.0 and later; SCHEMA added in Hive 0.14.0)
The uses of SCHEMA and DATABASE are interchangeable – they mean the same thing. ALTER SCHEMA was added in Hive 0.14 (HIVE-6601).
No other metadata about a database can be changed.
使用数据库
Use Database
USE database_name;
USE DEFAULT;
USE sets the current database for all subsequent HiveQL statements. To revert to the default database, use the keyword “default” instead of a database name. To check which database is currently being used: SELECT current_database() (as of Hive 0.13.0).
USE database_name was added in Hive 0.6 (HIVE-675).
create table page_view
(
page_id bigint comment '页面ID',
page_name string comment '页面名称',
page_url string comment '页面URL'
)
comment '页面视图'
partitioned by (ds string comment '当前时间,用于分区字段')
row format delimited
stored as rcfile
location '/user/hive/test';这里需要说下stored as 关键词,hive目前支持三种方式:
1:就是最普通的textfile,数据不做压缩,磁盘开销大,解析开销也大
2:SquenceFIle,hadoop api提供的一种二进制API方式,其具有使用方便、可分割、可压缩等特点。
3:rcfile行列存储结合的方式,它会首先将数据进行分块,保证同一个record在一个分块上,避免读一次记录需要读多个块。其次块数据列式存储,便于数据存储和快速的列存取。
RCFILE由于采用是的列式存储,所以加载时候开销较大,但具有很好的查询响应、较好的压缩比。
如果建立的表需要加上分区,则语句如下:
这里partitioned by 表示按什么字段进行分割,通常来说是按时间
create table test_ds
(
id int comment '用户ID',
name string comment '用户名称'
)
comment '测试分区表'
partitioned by(ds string comment '时间分区字段')
clustered by(id) sorted by(name) into 32 buckets
row format delimited
fields terminated by '\t'
stored as rcfile;如果需要对某些字段进行聚类存储,方便对hive集群列进行采样,则应该这样编写SQL:
create table test_ds
(
id int comment '用户ID',
name string comment '用户名称'
)
comment '测试分区表'
partitioned by(ds string comment '时间分区字段')
clustered by(id) sorted by(name) into 32 buckets
row format delimited
fields terminated by '\t'
stored as rcfile;这里表示将id按照name进行排序,聚类汇总,然后分区划分到32个散列桶中。
如果想改变表在hdfs中的位置,则应该使用location字段显式的指定:
create table test_another_location
(
id int,
name string,
url string
)
comment '测试另外一个位置'
row format delimited
fields terminated by '\t'
stored as textfile
location '/tmp/test_location';其中/tmp/test_location可不必先创建
1 基本的Select 操作
SELECT [ALL | DISTINCT] select_expr, select_expr, …
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list [HAVING condition]]
[ CLUSTER BY col_list
| [DISTRIBUTE BY col_list] [SORT BY| ORDER BY col_list]
[LIMIT number]
•使用ALL和DISTINCT选项区分对重复记录的处理。默认是ALL,表示查询所有记录。DISTINCT表示去掉重复的记录
•Where 条件
•类似我们传统SQL的where 条件
•目前支持 AND,OR ,0.9版本支持between
•IN, NOT IN
•不支持EXIST ,NOT EXIST
ORDER BY与SORT BY的不同
•ORDER BY 全局排序,只有一个Reduce任务
•SORT BY 只在本机做排序
Limit
•Limit 可以限制查询的记录数
SELECT * FROM t1 LIMIT 5
•实现Top k 查询
•下面的查询语句查询销售记录最大的 5 个销售代表。
SET mapred.reduce.tasks = 1
SELECT * FROM test SORT BY amount DESC LIMIT 5
•REGEX Column Specification
SELECT 语句可以使用正则表达式做列选择,下面的语句查询除了 ds 和 hr 之外的所有列:
SELECT (ds|hr)?+.+ FROM test
例如
按条件查询
hive> SELECT a.foo FROM invites a WHERE a.ds=’’;
将查询数据输出至目录:
hive> INSERT OVERWRITE DIRECTORY ‘/tmp/hdfs_out’ SELECT a.* FROM invites a WHERE a.ds=’’;
将查询结果输出至本地目录:
hive> INSERT OVERWRITE LOCAL DIRECTORY ‘/tmp/local_out’ SELECT a.* FROM pokes a;
选择所有列到本地目录 :
hive> INSERT OVERWRITE TABLE events SELECT a.* FROM profiles a;
hive> INSERT OVERWRITE TABLE events SELECT a.* FROM profiles a WHERE a.key < 100;
hive> INSERT OVERWRITE LOCAL DIRECTORY ‘/tmp/temp_3’ SELECT a.* FROM events a;
hive> INSERT OVERWRITE DIRECTORY ‘/tmp/temp_4’ select a.invites, a.pokes FROM profiles a;
hive> INSERT OVERWRITE DIRECTORY ‘/tmp/temp_5’ SELECT COUNT(1) FROM invites a WHERE a.ds=’’;
hive> INSERT OVERWRITE DIRECTORY ‘/tmp/temp_5’ SELECT a.foo, a.bar FROM invites a;
hive> INSERT OVERWRITE LOCAL DIRECTORY ‘/tmp/sum’ SELECT SUM(a.pc) FROM pc1 a;
将一个表的统计结果插入另一个表中:
hive> FROM invites a INSERT OVERWRITE TABLE events SELECT a.bar, count(1) WHERE a.foo > 0 GROUP BY a.bar;
hive> INSERT OVERWRITE TABLE events SELECT a.bar, count(1) FROM invites a WHERE a.foo > 0 GROUP BY a.bar;
JOIN
hive> FROM pokes t1 JOIN invites t2 ON (t1.bar = t2.bar) INSERT OVERWRITE TABLE events SELECT t1.bar, t1.foo, t2.foo;
将多表数据插入到同一表中:
FROM src
INSERT OVERWRITE TABLE dest1 SELECT src.* WHERE src.key < 100
INSERT OVERWRITE TABLE dest2 SELECT src.key, src.value WHERE src.key >= 100 and src.key < 200
INSERT OVERWRITE TABLE dest3 PARTITION(ds=’2008-04-08’, hr=’12’) SELECT src.key WHERE src.key >= 200 and src.key < 300
INSERT OVERWRITE LOCAL DIRECTORY ‘/tmp/dest4.out’ SELECT src.value WHERE src.key >= 300;
将文件流直接插入文件:
hive> FROM invites a INSERT OVERWRITE TABLE events SELECT TRANSFORM(a.foo, a.bar) AS (oof, rab) USING ‘/bin/cat’ WHERE a.ds > ‘2008-08-09’;
This streams the data in the map phase through the script /bin/cat (like hadoop streaming). Similarly - streaming can be used on the reduce side (please see the Hive Tutorial or examples)
- 基于Partition的查询
•一般 SELECT 查询会扫描整个表,使用 PARTITIONED BY 子句建表,查询就可以利用分区剪枝(input pruning)的特性
•Hive 当前的实现是,只有分区断言出现在离 FROM 子句最近的那个WHERE 子句中,才会启用分区剪枝
3.Join
Syntax
join_table:
table_reference JOIN table_factor [join_condition]
| table_reference {LEFT|RIGHT|FULL} [OUTER] JOIN table_reference join_condition
| table_reference LEFT SEMI JOIN table_reference join_condition
table_reference:
table_factor
| join_table
table_factor:
tbl_name [alias]
| table_subquery alias
| ( table_references )
join_condition:
ON equality_expression ( AND equality_expression )*
equality_expression:
expression = expression
•Hive 只支持等值连接(equality joins)、外连接(outer joins)和(left semi joins)。Hive 不支持所有非等值的连接,因为非等值连接非常难转化到 map/reduce 任务
•LEFT,RIGHT和FULL OUTER关键字用于处理join中空记录的情况
•LEFT SEMI JOIN 是 IN/EXISTS 子查询的一种更高效的实现
•join 时,每次 map/reduce 任务的逻辑是这样的:reducer 会缓存 join 序列中除了最后一个表的所有表的记录,再通过最后一个表将结果序列化到文件系统
•实践中,应该把最大的那个表写在最后
join 查询时,需要注意几个关键点
只支持等值join
•SELECT a.* FROM a JOIN b ON (a.id = b.id)
•SELECT a.* FROM a JOIN b
ON (a.id = b.id AND a.department = b.department)
•可以 join 多于 2 个表,例如
SELECT a.val, b.val, c.val FROM a JOIN b
ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
•如果join中多个表的 join key 是同一个,则 join 会被转化为单个 map/reduce 任务
LEFT,RIGHT和FULL OUTER
例子
•SELECT a.val, b.val FROM a LEFT OUTER JOIN b ON (a.key=b.key)
•如果你想限制 join 的输出,应该在 WHERE 子句中写过滤条件——或是在 join 子句中写
•容易混淆的问题是表分区的情况
• SELECT c.val, d.val FROM c LEFT OUTER JOIN d ON (c.key=d.key)
WHERE a.ds=’2010-07-07’ AND b.ds=’2010-07-07‘
•如果 d 表中找不到对应 c 表的记录,d 表的所有列都会列出 NULL,包括 ds 列。也就是说,join 会过滤 d 表中不能找到匹配 c 表 join key 的所有记录。这样的话,LEFT OUTER 就使得查询结果与 WHERE 子句无关
•解决办法
•SELECT c.val, d.val FROM c LEFT OUTER JOIN d
ON (c.key=d.key AND d.ds=’2009-07-07’ AND c.ds=’2009-07-07’)
LEFT SEMI JOIN
•LEFT SEMI JOIN 的限制是, JOIN 子句中右边的表只能在 ON 子句中设置过滤条件,在 WHERE 子句、SELECT 子句或其他地方过滤都不行
•
•SELECT a.key, a.value
FROM a
WHERE a.key in
(SELECT b.key
FROM B);
可以被重写为:
SELECT a.key, a.val
FROM a LEFT SEMI JOIN b on (a.key = b.key)
UNION ALL
•用来合并多个select的查询结果,需要保证select中字段须一致
•select_statement UNION ALL select_statement UNION ALL select_statement …















 2933
2933

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









